本文源自 7 月 13 日『高效开发运维』微信群的在线分享,分享者为360Web平台部DBA团队刘臻,本文infoQ的『高效开发运维』公众号首发,已授权转载。
PS:丰富的一线技术、多元化的表现形式,尽在“
HULK一线技术杂谈
”,点关注哦!
1.HULK 私有云平台介绍
2.现有 MySQL 服务规模
3.MySQL 服务常用功能展示
4.各功能模块设计实现思路
5.新的计划
6.Q&A
说起 HULK 私有云平台大家有参加过之前我们同事分享的应该听过,360HULK 私有云平台是奇虎 360 公司内部专属私有云平台,平台涉及云计算、数据库、大数据、监控等众多技术领域。今天要分享的 MySQL 服务就是 HULK 数据库服务中的一种。

这个是 HULK 用户端的首页,而其中数据库服务又集合了 MySQL、Redis、Mongodb、Greenplum、ElasticSearch 等,今天的主角是 MySQL,MySQL 作为基础服务是 DBA 服务体系中的基石,在 HULK 云平台中,MySQL 实例数已经突破 9000+,日访问量超过 200 亿,单份数据量也已经超过了 270TB。
不知道大家跟业务或者 DBA 沟通需求通过什么途径,当年我们没有搞自动化之前,需求沟通占用很大一部分工作时间,并且资源管理、服务部署等都是体力活,往往业务从需求沟通到实例部署完成,都是小时计的,而现在,我们可以做到分钟级,下面是在使用 HULK 平台自动化前后的对比。
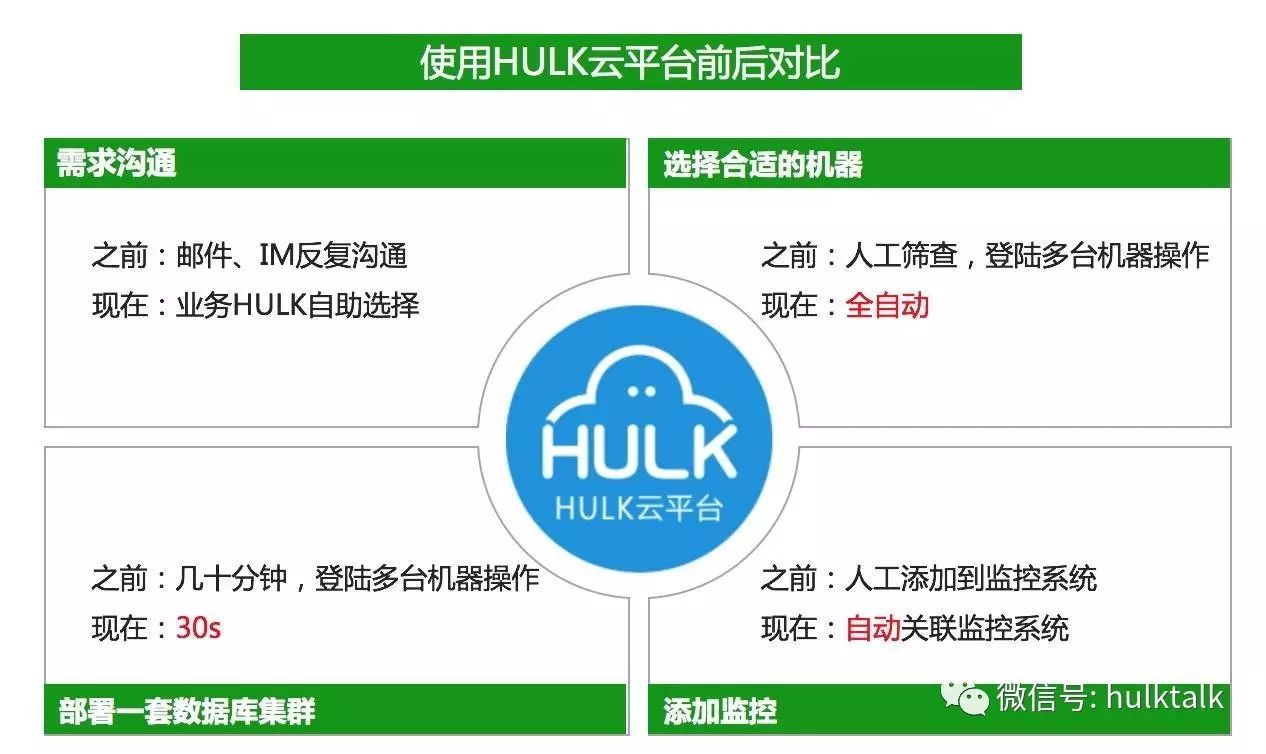
实现全部自动化后,业务可以随时随地自助的提交数据库申请,不受时间和外部其他因素困扰,并能快速的投入使用,极大的提高了开发效率。
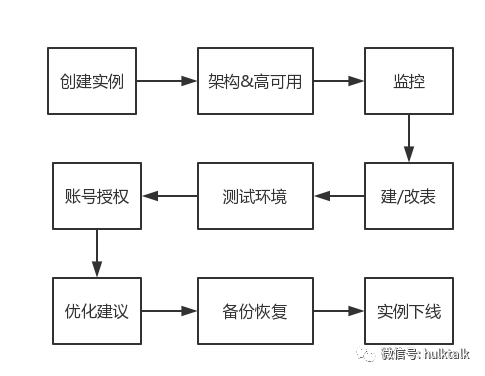
下面会根据业务在 HULK 上从申请到最终下线,贯串整个流程来演示和分析下各个模块的功能和设计思路。
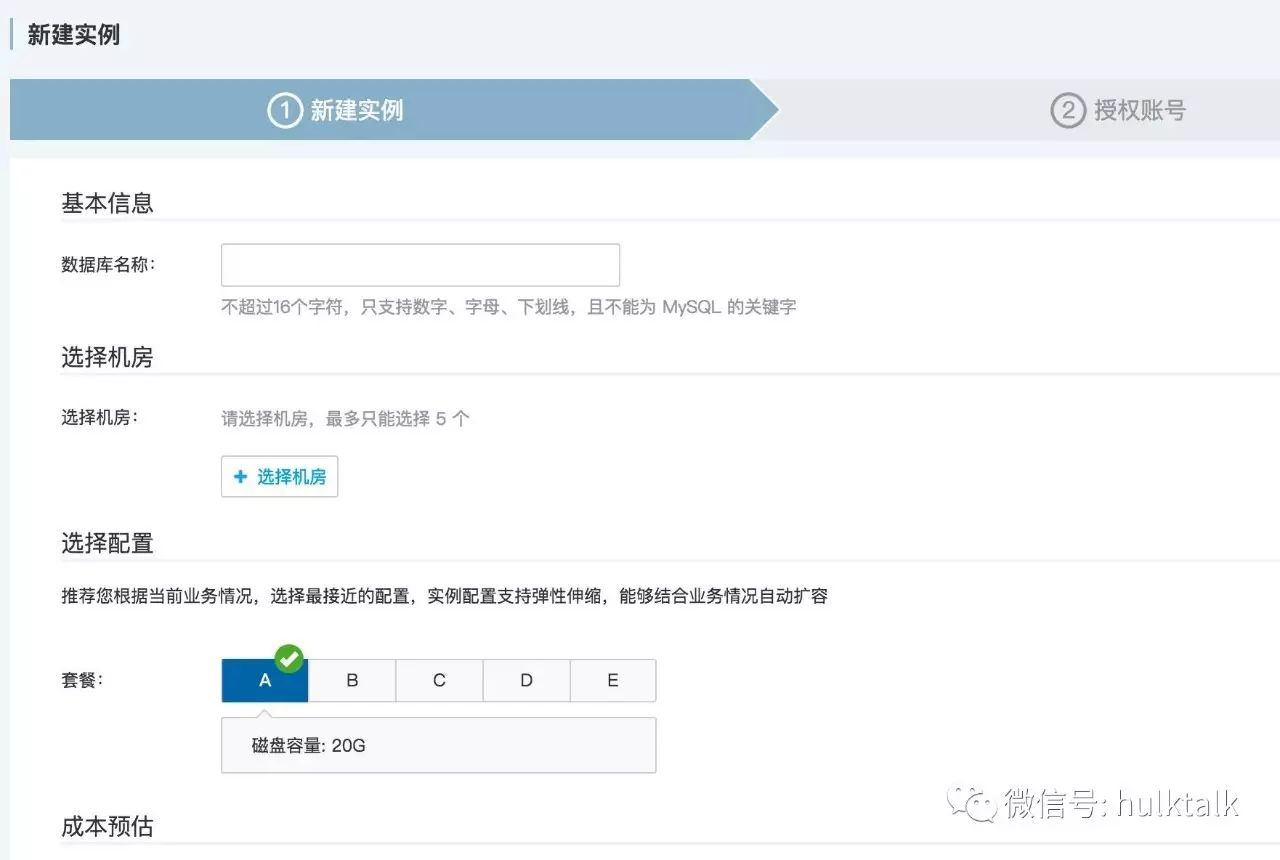
先看下创建实例,目前我们实例创建做到了全自动,业务之需根据自己业务情况选择对应的套餐、部署 IDC 以及访问数据库的机器列表,即可提交任务,任务提交后自动化完成,时间视部署 IDC 情况在 30 秒到 1 分钟之间。这个是实例申请页面,业务提交完申请,只需要查看工单状态,完成后具体的数据库连接信息会邮件发送。我们底层的任务系统用的自研的 QCMD,后面有机会的话也会在这里和大家分享,本次不做过多介绍。
而要做到这样的全自动,就需要从资源分析控制上入手,怎么合理的分配资源,且能高效的利用,是重点要考虑的问题,下面是我们在做自动化中遇到和解决的几个技术点:

借鉴各个公有云的模式,我们分析了业务的各种需求类型,同时对比我们内部的数据库资源,将数据库实例归类划分为套餐,不同的套餐对应不同的数据库资源,每台服务器也有自己对应的资源总数,实例新建、扩容、下线等都会相应增删不同比例的资源。这样每台服务器理论分配的数据库实例和对应消耗的资源是可控的。
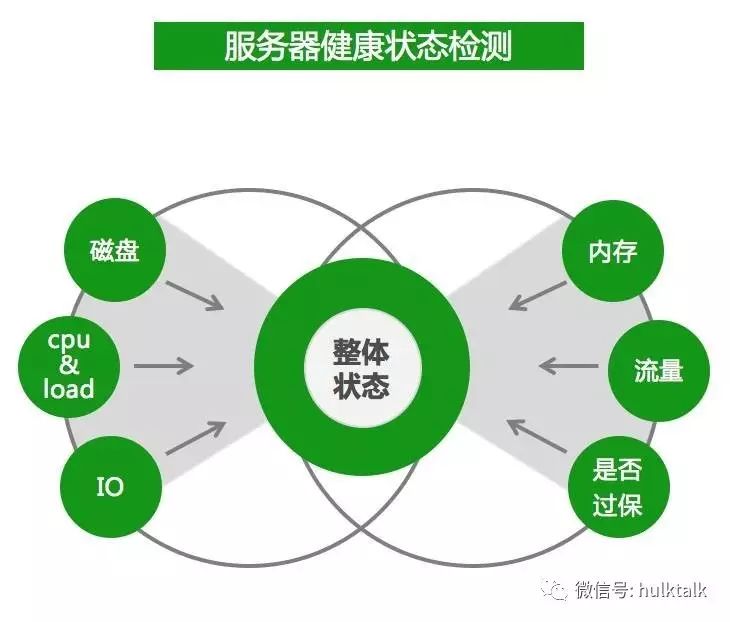
同时,我们对服务器实际消耗的资源进行动态统计分析,并对健康状态进行打分,这样进一步来控制服务器的资源使用。
自动关联监控系统比不可少,第一时间将数据库实例纳入监控体系,并且在管理员维护操作的时候可以灵活启停监控。
对机器资源统计方面我们重点监测下面 7 个点,有一个监测点的值超过了对应阈值则处于不同的状态,在创建实例自动选择机器的时候,将会按照不同的逻辑选择。
实例创建完成,下图是我们默认的数据库架构图,以双 IDC 为例,用 Atlas 作为中间层,提供读写分离,Atlas 已经开源具体可以参考:https://github.com/Qihoo360/Atlas 。 在 Atlas 之上用 LVS 做了一次隔离和负载均衡,其中为了高可用,每个机房的服务节点都是部署多个,避免单点故障。
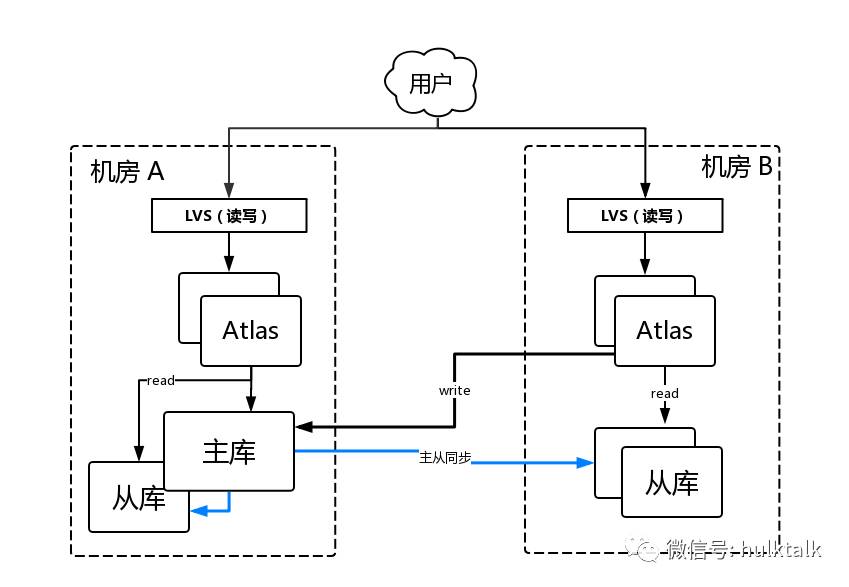
当单个 Atlas 故障的时候,LVS 检测到异常会直接下线,而当单个从库故障的时候,Atlas 检测到也会下线。 这样在 Atlas 和从库单点故障的时候整个集群还能正常工作,并且不影响业务使用。但是,当主库挂掉的时候,就改我们的故障自动切换 Failover 出场了。
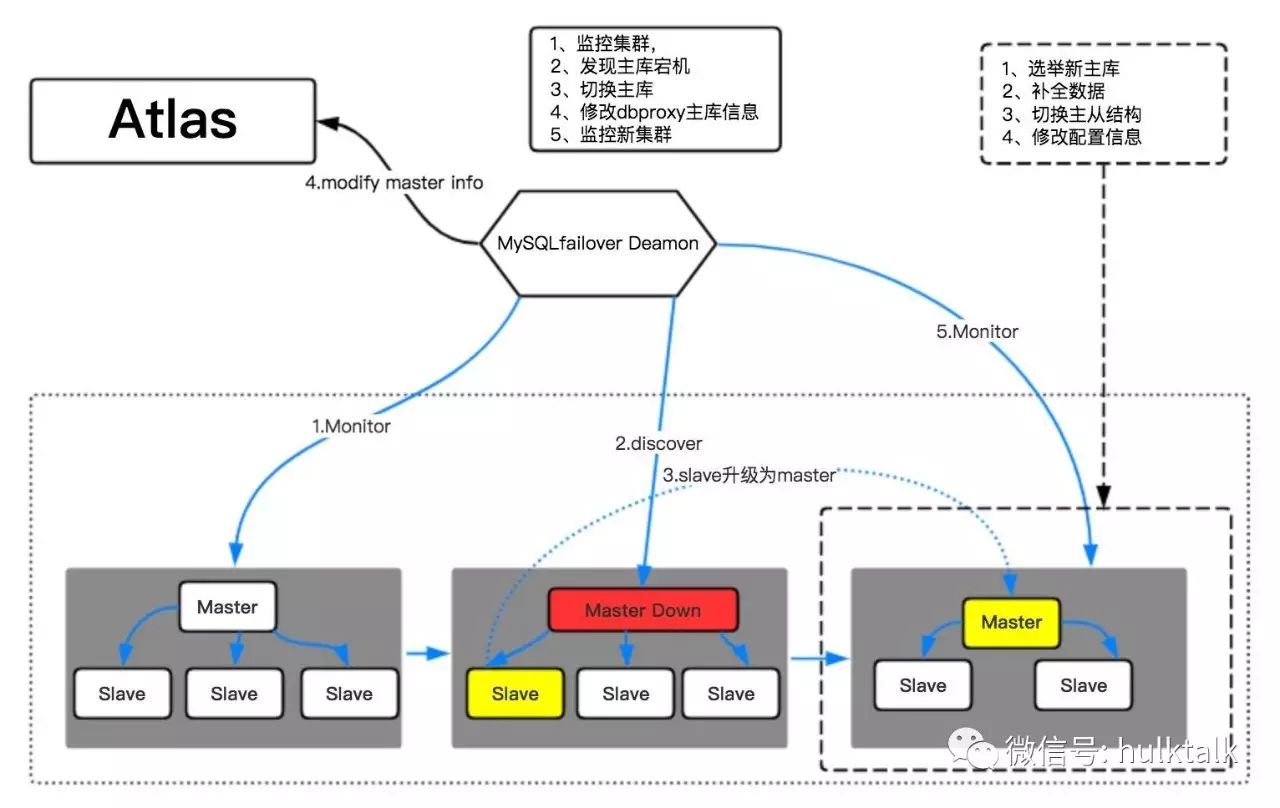
下图是我们主库宕机时的切换流程,我们的故障切换服务 MySQL Failover 实时监控集群状态,当发现主库宕机后,会根据选主逻辑选出新主库、补全数据、重做主从结构然后修改 Atlas 的配置,到此整个切换流程完成,MySQL Failover 重新进入监控状态。正常情况整个故障切换耗时 15s 左右。
说完数据库结构和故障切换,按照正常操作流程业务们该建表、改表、授权、查看监控等操作了,其中授权监控这里就不多赘述了。因为我们平台默认给业务方只有对数据的增删改查权限,所以建表改表需要业务来 HULK 平台操作,针对建表,我们根据运维经验和踩坑实践,总结了 16 个检查项,这里贴出来和大家分享下。
建表语句需要符合一定标准,否则将建表失败,具体审核标准如下:
-
表结构是否合法;
-
表名、列明长度超过 16;
-
必须有 unsigned;
-
必须为 innodb;
-
int bigint (10) 不能小于 10;
-
varchar 长度小于 3000;
-
text 字段个数不能大于 3;
-
主键必须为 int 类型;
-
索引不能有重复;
-
索引个数不能大于 5 个(包括主键);
-
索引字段必须为 not null,并且有 default 值(除自增键外);
-
SQL 是否使用到索引;
-
审核的 SQL 不要包含非审核的表;
-
SQL 中不能有 *;
-
自增字段必须为 int 或者 bigint;
-
请不要使用 MySQL 预留字(Reserved Words);
下面这个是测试建表的示例。

改表我们用的是 pt-osc(pt-online-schema-change),不过我们最近也在研究 gh-ost https://github.com/github/gh-ost ,对 gh-ost 感兴趣的咱们也可以下来交流。
为了方便业务测试,我们在平台上提供了测试环境,并且将测试环境和线上环境打通,业务可以直接将库表结构在线上和测试之间互导。方便业务测试和上线操作。

优化建议我们平台上目前统计了三类:慢日志、未使用索引、char 字段,其中慢日志收集了执行超过 0.5s 的 sql 以天为单位汇总后使用 pt-query-digest 分析,并将结果展示在 HULK 平台。
未使用索引我们使用了 MySQL5.6 中 PS 库的 table_io_waits_summary_by_index_usage 表的信息,汇总分析出没有被使用到的索引,重复索引会浪费存储空间,同时对数据更新性能也有影响,在一些场景下,还会对查询优化器造成干扰,可谓百害而无一利。
我们另一个优化建议就是 char 字段优化了,好多业务在建表的时候喜欢用 char 类型,但是 char 是固定长度,申请多少就占多少空间,当存入的字符串长度不够的时候会用空格补齐,这样在非定长的字符串存储中 char 会浪费大量的存储空间,所以我们对线上的所有字段定期进行分析汇总,扫描出使用长度远小于申请长度的表和字段,以报表的方式展示给业务,方便业务及时优化,我们建议直接将 char 改为 varchar,除非存储的是定长的比如 md5 之类的字符串,否则全部建议用 varchar。varchar 是可变长度的,实际使用多少就分配多少,额外再用 1-2 字节存储长度,并且超过指定长度还可以继续写入。
大家关心的数据恢复来了,不知道大家有没有这个经历:不小心误操作了需要恢复数据,但是联系 DBA、沟通需求、DBA 数据恢复、业务数据确认、替换上线,这整个流程走下来可能影响已经扩大,况且有可能数据恢复的需求在半夜,这个流程可能又延长很多。出于这种场景的考虑,我们将数据恢复也做成了自动化的任务,业务可以自助随时提交恢复任务,避免沟通确认各个环节浪费宝贵的数据恢复时间。数据可以恢复到 7 天以内任意时间点。看操作流程截图:

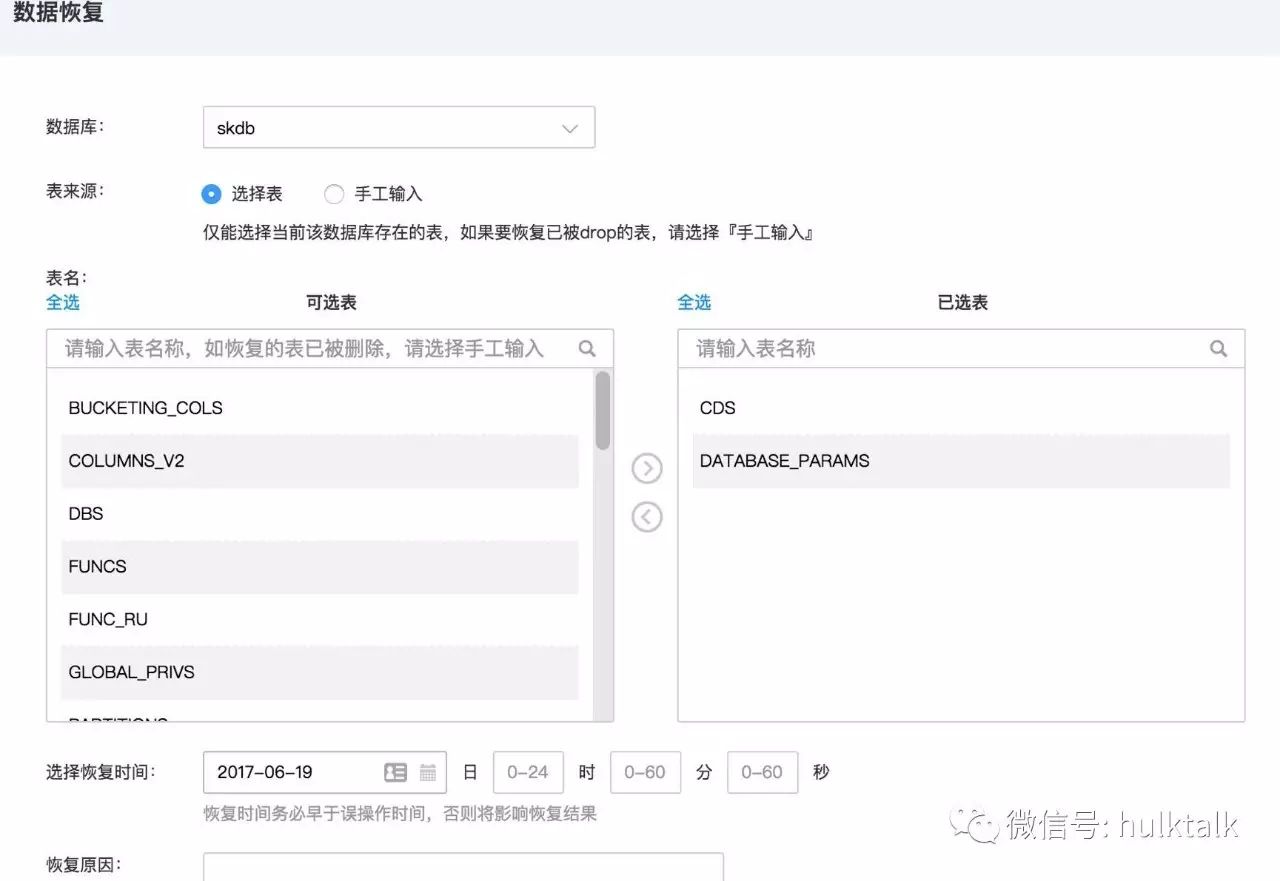
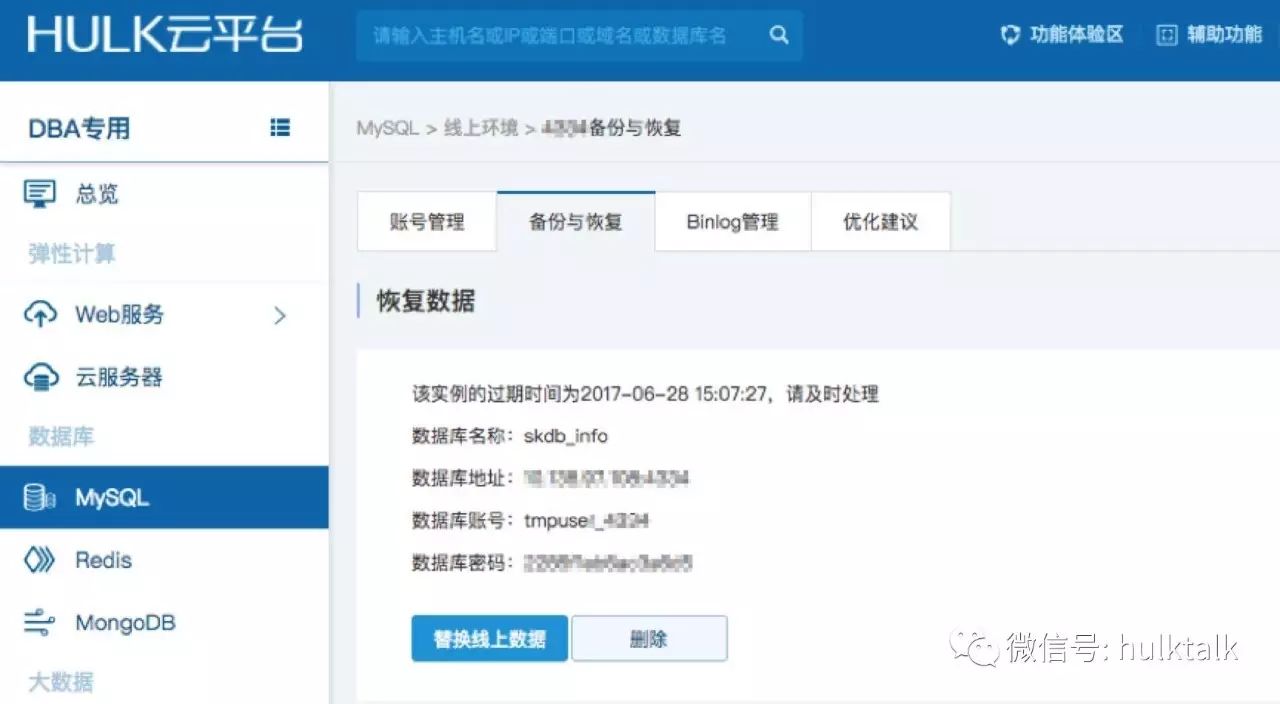
业务之需选择需要恢复的库表,选择时间提交任务即可,视数据量大小耗费时间不一,普通的几 G 的数据表,一般分钟级就能恢复,恢复后会生成临时实例,业务去临时实例确认数据无误后就可以一键替换线上,完成数据恢复申请。
前面大家也了解了自动数据恢复,数据恢复依赖于完善的数据备份。我们的备份系统各模块构成如下图:
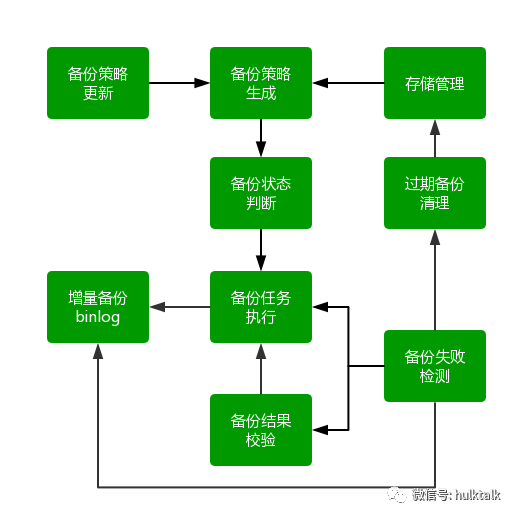
备份系统特点
全量备份 + 增量备份(binlog),每天都会进行全量备份,同时实时进行 binlog 备份。
4, 2,2,1 策略,即保留最近 4 天每天的全量备份,最近 2 周,最近 2 月,最近 1 年的全量备份binlog 保留最近 60 天。
策略根据当天状态动态刷新,根据从库状态(我们在从库备份),存储状态,网络状态等动态跟新备份策略。
备份失败自动归类,集中处理。备份失败检测模块会将失败任务汇总,报表展示。
存储管理模块会根据保留策略,清理过期的备份数据。
我们备份系统是基于 Percona XtraBackup 实现的,不过根据我们的使用场景,做了一些改进与提升:
我们备份过程中按表为单位单独备份打包压缩,以便于支持单 / 多表快速恢复
为了快速恢复我们修改部分备份功能,可以支持数据恢复的时候值拷贝需要恢复的数据表和 MySQL 元数据信息, 极大节省数据拷贝、解压以及数据恢复时主从数据同步时间。想象下这种场景:源数据库有 1T 数据,现在需要快速恢复一张 1G 的数据表,如果不支持单表恢复,则需要拷贝 1T 的数据并解压,这恢复时间起码好几个小时,但是支持单表恢复后,拷贝和解压的数据量只有几 G,分钟级就可以恢复。
增加了数据加密模块和加密传输模块
支持时间点,binlog_pos,sql 等多种恢复模式
从 DBA 和运维角度出发,还可以做一些事情来避免机器级别的故障:
-
关注远控报错,有问题及时迁移实例报修
-
监控系统日志,提前发现故障机器。有一些硬件故障不会导致立即宕机,单是个定时炸弹,这些信息会被记录到系统日志,如 message,mcelog 中,对这些日志增加监控,可以提前发现有故障隐患的机器,提前迁移数据库实例,避免宕机影响服务。
-
控制机器过比率,发现现在厂商对过保故障控制的特别到位,一过保,机器故障率里面飙升,所以我们也对机器的过保情况进行了统计,避免重点业务部署在已过保的机器上。
日常操作自动化之后,业务开发效率提高同时 DBA 也可以省去之前大量的重复劳动,可以有更多的精力来提高服务质量以及研究写新的技术。以上就是我们 HULK 平台 MySQL 服务的一些设计思路和实践经验。
Q1:未来计划的数据库的迁库操作是怎样的?是不是开发人员可以很简单地进行操作?










