
本文来自作者
蓬蒿
在
GitChat
上分享 「谈谈 Java 内存模型」,
「
阅读原文
」
查看交流实录。
「
文末高能
」
编辑 | 哈比
0. 前言
Java 并发程序要比单线程串行程序复杂很多,很重要的原因在于并发环境下的共享数据一致性和安全性将受到严重挑战。
Java 内存模型 (JMM) 定义了 JVM 如何正确访问计算机主内存。JMM 指定了不同线程如何以及何时可以看到其他线程写入到共享变量的值,以及如何在必要时同步访问共享变量。
作为一名开发者,如果想要设计出能够正确运行的并行程序,理解 JMM 是必要条件。
Java 多线程之间通信一般有两种方式:
共享内存和消息传递
。Java 的并发采用共享内存的方式,共享内存通信方式对于程序员而言总是透明隐式进行的。
JMM 关键技术点都是围绕着多线程的原子性、可见性、有序来讨论的。JMM 解决了
可见性和有序性
的问题,而
锁
解决了
原子性
的问题。
作为一名有追求的 Java 程序猿,你必须要去了解 Java 内存模型(JMM)。通过学习 JMM,你对 java 语言会有种拨开云雾见天日的感觉,这 n 难道还是我最初认识的 Java 吗 ?
1. 什么是 Java 内存模型 (JMM)
假设一个线程为一个共享变量赋值:
count = 1;
那么 Java 内存模型就是为了解决这个问题,” 在什么情况下,读取共享变量
count
的线程能够读取到值 1”。
这似乎看起来是一个很傻的问题。如果在单线程串行环境下的确不算一个问题,但在多线程环境下,若没有内存模型提供正确的同步机制,那么很多情况下线程是不能马上读取到共享变量
count
最新值。
一方面 Java 程序书写顺序与编译后的指令顺序不一定相同,指令存在重排序情况;另一方面每个 CPU 处理器存在缓存,缓存存储了线程读写共享变量的副本。
2. Java 内存模型的抽象
Java 内存模型 (JMM) 定义了 JVM 如何正确访问计算机主内存。JMM 指定了不同线程如何以及何时可以看到其他线程写入到共享变量的值,以及如何在必要时同步访问共享变量。
早期 JDK 的 Java 内存模型不够完善,所以 Java 内存模型在 Java 1.5 中进行了修改。目前,该版本的 Java 内存模型仍然在 Java 8 中使用。
现代计算机硬件内存模型如下所示:

Java 内存模型抽象示意图如下所示:
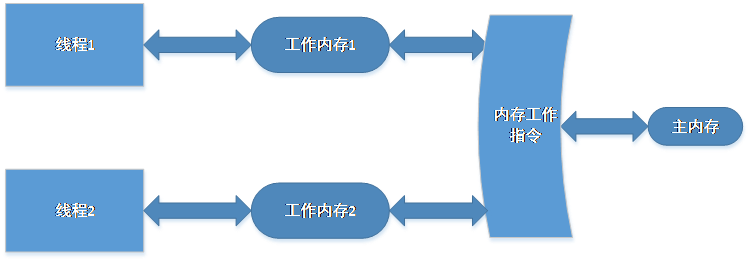
工作内存在 Java 内存中是一个抽象的概念,一般是指 CPU 高速缓存、寄存器等。
在现代多核处理器系统中处理器一般会存在多层的高速缓存,因为访问内存数据的速度远落后于直接从寄存器、高速缓存获取数据。
高速缓存减少了共享内存总线的访问流量冲突,极大改善了 CPU 的访问性能。缓存使性能得到优化同时也带来的新的具有挑战性的问题。
例如,当两个线程 (处理器) 同时访问同一内存位置的共享变量,在什么条件下双方可以看到相同的值。这其实就是多线程并发中的
内存可见性
问题。
Java 内存模型的可见性问题的底层实现是通过内存屏障 (memory barriers) 实现。
3. JVM 指令重排序 ( Instruction Reorder)
对于一段代码而言,我么习惯性认为代码总是从前而后执行的,依次执行的。在单线程串行环境下,这么理解也是没有错的。
但在多线程并发环境下,那么就有可能出现乱序的情况。从直观感觉可以知道,后面的代码先于之前代码执行。这似乎有点让人有点难以理解?
根本原因在于 JVM 编译器为了提高程序的执行效率,一般会对代码进行优化。
因此,不能保证程序中的代码顺序一定是按照书写顺序执行的,也就是编译器和处理器会对指令进行重排序。
指令重排序不会对单线程程序有影响,但是在多线程并发环境下就会存在很多问题。
3.1 指令重排序对并发程序的影响
我们来看看指令重排序对并发程序的影响,假设有两个线程 A 和线程 B,线程 A 首先执行 write() 方法,仅接着线程 B 再执行 read() 方法。
/**
* @author [email protected]
* @version $Id: ReorderSample.java v 0.1 2018/1/6 18:38 pez1420 Exp $$
*/public class ReorderService { private int x = 0; private boolean flag = false; public void write() {
x = 1;
flag = true;
} public void read() { if (flag == true) {
x = x * 1;
} if (x == 0) {
System.out.println("x==0");
}
}
}public class ThreadA extends Thread { private ReorderService reorderService; public ThreadA(ReorderService reorderService) { this.reorderService = reorderService;
} @Override
public void run() {
reorderService.write();
}
}public class ThreadB extends Thread { private ReorderService reorderService; public ThreadB(ReorderService reorderService) { this.reorderService = reorderService;
} @Override
public void run() {
reorderService.read();
}
}public class StartMain { public static void main(String[] args) throws InterruptedException { for (int i = 0; i < 10000; i++) {
ReorderService reorderService = new ReorderService();
ThreadA threadA = new ThreadA(reorderService);
ThreadB threadB = new ThreadB(reorderService);
threadA.start();
threadB.start();
threadA.join();
threadB.join();
}
}
}
步骤 1 和步骤 2,步骤 3 和步骤 4 都可能存在重排序的情况。如果发生了重排序,那么线程 B 在执行到步骤 4 时,不一定能看到 x 被赋值为 1。
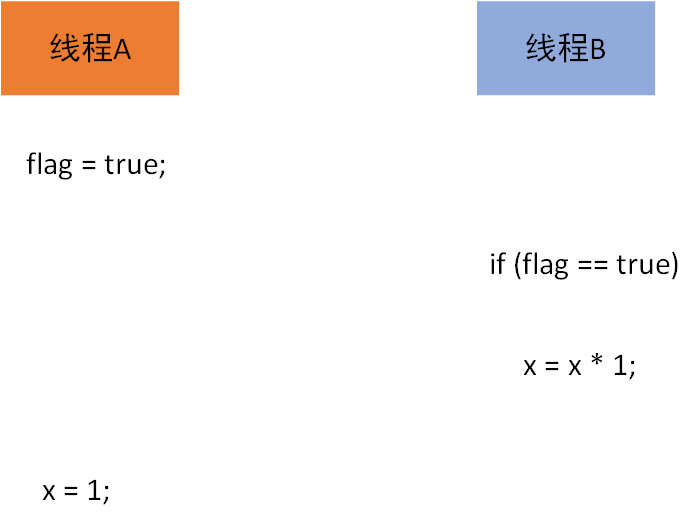
从上图我们可以看到线程 A 的步骤 1 和步骤 2 进行了重排序。
程序运行时,线程 A 首先执行步骤 2flag 的赋值操作将其设置为 true;接着线程 B 执行步骤 3,由于条件为真,线程 B 将读取共享变量 x 的值,此时 x 的值还未被线程 A 写入,所有多线程程序语义由于程序重排序被破坏了!
这是一个让然觉得很神奇的现象,不过它的确可能存在。但指令重排序有一个基本前提:指令重排序需要确保串行语义一致,但不能够确保多线程间的语义也是一致的。

从上图可以看出,编译器和处理器将步骤 3 和步骤 4 进行了重排序。
3.2 为什么要指令重排序 ?
对于处理器而言,一条汇编指令的执行时分为很多步骤的。在多处理器下,一个汇编指令不一定是原子操作的。
指令重排序涉及到一些计算机组成原理课程的知识,想深入研究的同学可以回去翻翻课本。为提高 CPU 利用率,加快执行速度,将指令分为若干个阶段,可并行执行不同指令的不同阶段,从而多个指令可以同时执行。
在有效地控制了流水线阻塞的情况下,流水线可大大提高指令执行速度。经典的五级流水线,也就是一条指令可以分为 5 个步骤:
-
取址 (IF,Instruction Fetch, 取指 );
-
译码 / 读寄存器 (ID,Instruction Decode, 译码);
-
执行 / 计算有效地址 (EX,Execute, 执行);
-
访问内存(读或写)(MEM,Memory Access, 内存数据读或者写);
-
结果写回寄存器 (WB,Write Back, 数据写回到通用寄存器中)。
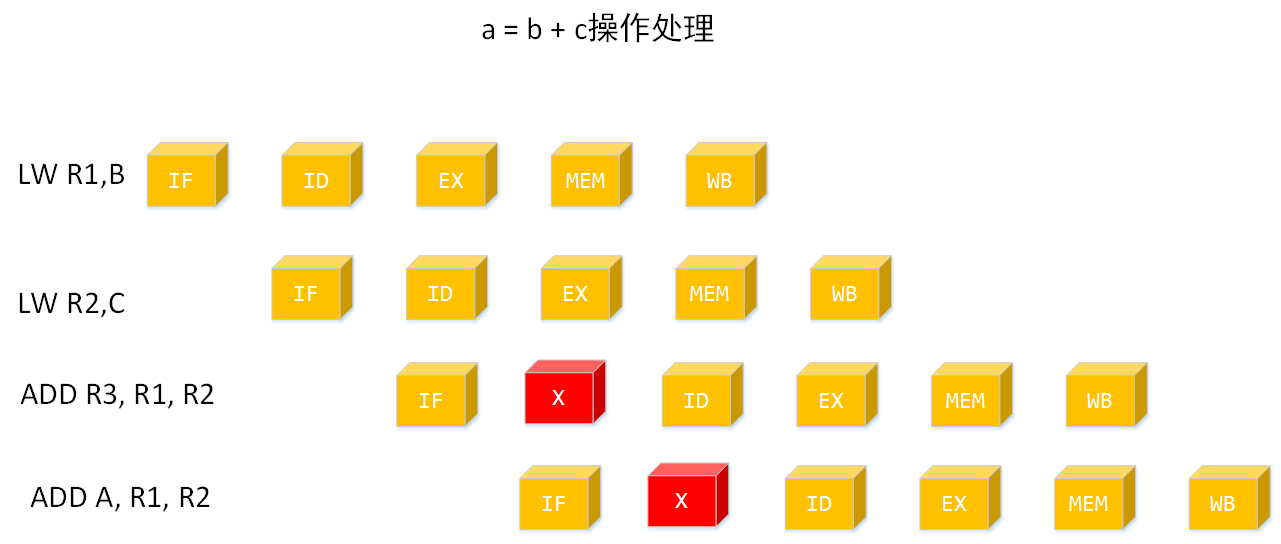
上图左边操作为汇编指令,LW 表示把值 B 加载至寄存器 R1;ADD 指令表示加法,将寄存器 R1 和 R2 值相加写入寄存器 R3;SW 表示将寄存器 R3 的值写入变量 A 中。
ADD 指令和 SW 指令分别有个红叉,表示流水线中断。
ADD 指令中断原因是等待 R2 的结果,SW 指令中断原因是等待 R3 的结果。
我们再分析一个复杂的例子:
a = b + c;
d = e - f;
上面的代码指令流水线为:
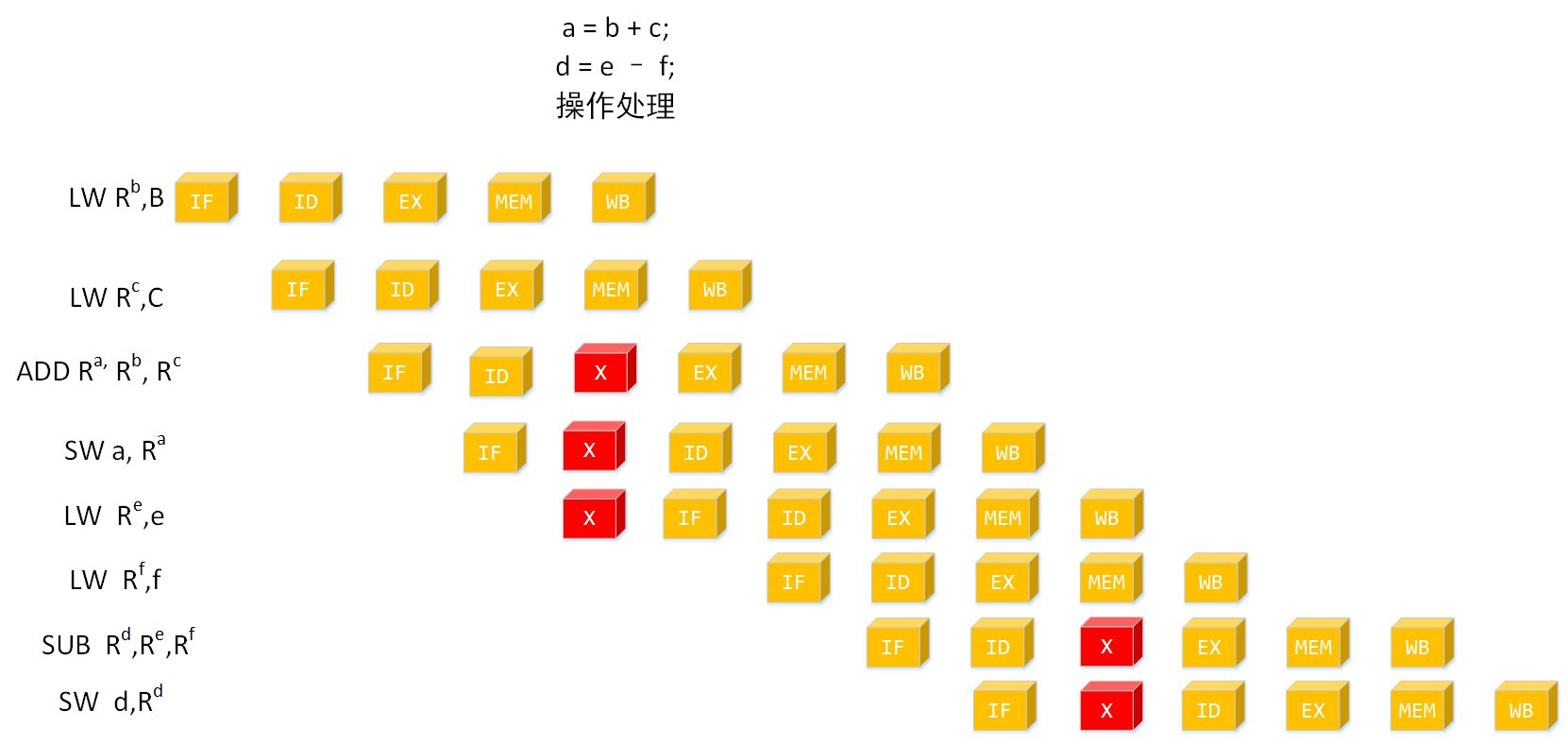
由于中断流水线的存在导致停顿, 哪是否有消除停顿的方法?显然是有的,我们可以将
LW Re,e
LW Rf,f
移动前面执行,理解起来很简单,因为这两个操作对程序的执行语义是没有影响的。
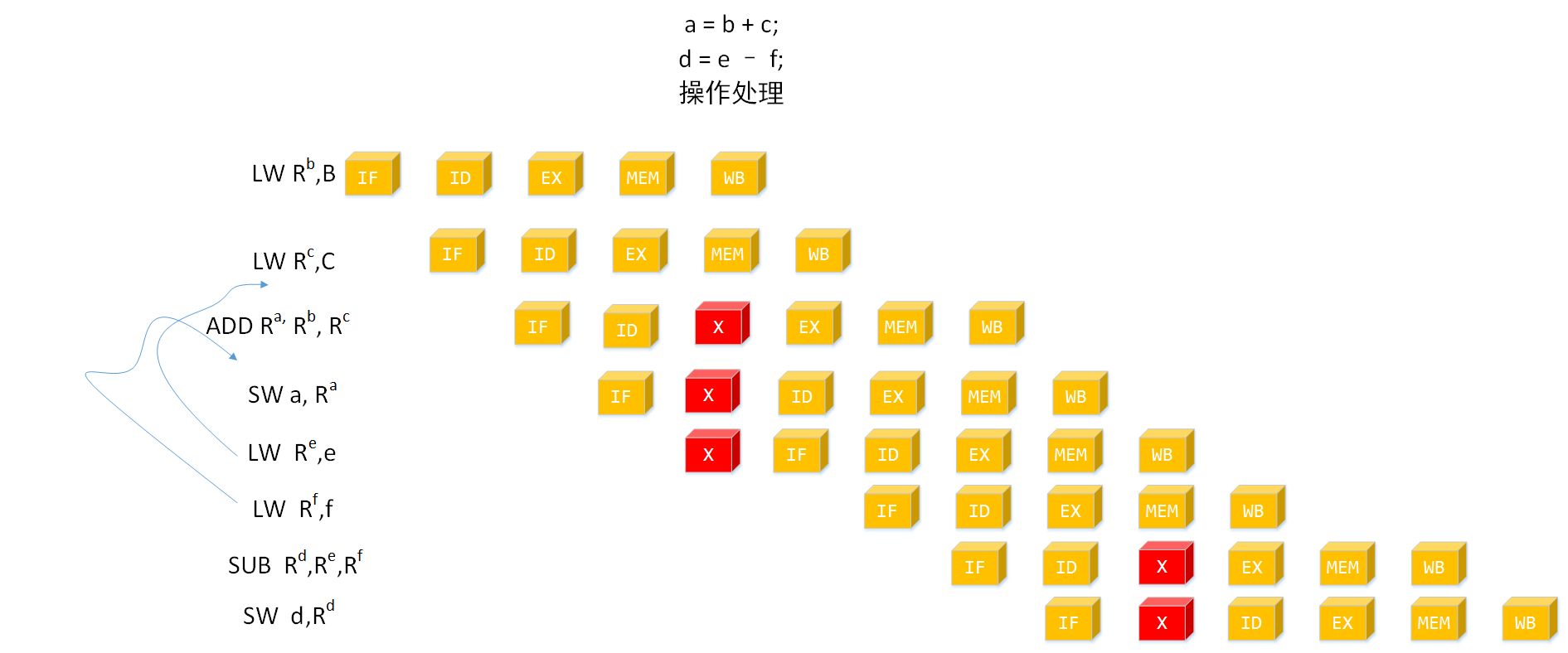 指令进行重排序之后的结果,可以看到所有的中断都已经被消除掉。
指令进行重排序之后的结果,可以看到所有的中断都已经被消除掉。
 显然指令重排序对于提高 CPU 的吞吐能力是有极大的提升的。但也带来了程序运行乱序的负面问题,不过与性能相比较这点牺牲是值得的。
显然指令重排序对于提高 CPU 的吞吐能力是有极大的提升的。但也带来了程序运行乱序的负面问题,不过与性能相比较这点牺牲是值得的。
指令重排序还有一个非常经典的例子,就是单例模式与双重检查锁问题 (double-checked locking)。
3.3 双重检查锁问题 (double-checked locking)
单例模式是所有设计模式中最为简单最好理解的设计方式。通过单例模式与多线程指令重排序、内存可见性相结合,你能够考虑到之前许多重来未考虑的问题。
3.3.1 饿汉模式
饿汉单例模式是在单例类被加载时,对象实例已经被初始化。
public class SingleInstance {
private static final SingleInstance INSTANCE = new SingleInstance();
private SingleInstance() {
}
public static SingleInstance getInstance() {
return INSTANCE;
}
}
3.3.2 懒汉模式
懒汉模式是指在调用 getInstance 方法时,实例对象才会被创建,最为常见的方法是在 getInstance 方法中进行实例化。
public class SingleInstance {
private static SingleInstance INSTANCE;
private SingleInstance() {
}
public static SingleInstance getInstance() {
if (INSTANCE != null) {
return INSTANCE;
} else {
INSTANCE = new SingleInstance();
}
return INSTANCE;
}
}
懒汉模式延迟加载模式在多线程并发环境中,就会出现获取多个实例的情况,与单例模式初衷是相违背的。
3.3.3 懒汉模式解决方案
既然多个线程可以同时进入 getInstance 方法,需要对该方法进行同步,在方法增加同步关键字 synchronized。
public class SingleInstance {
private static SingleInstance INSTANCE;
private SingleInstance() {
}
public static synchronized SingleInstance getInstance() {
if (INSTANCE != null) {
return INSTANCE;
} else {
INSTANCE = new SingleInstance();
}
return INSTANCE;
}
}
显然,每次调用 getInstance 方法都需要进行同步,效率太低了。。那有没有更好的办好呢?我们想到可以用同步代码块的方式减小同步代码的粒度。
public static SingleInstance getInstance() {
synchronized (SingleInstance.class) {
if (INSTANCE != null) {
return INSTANCE;
} else {
INSTANCE = new SingleInstance();
}
}
return INSTANCE;
}
需要指出的是上面这种优化方式并没有减小同步代码的粒度与
public static synchronized SingleInstance
几乎是一样的,效率并没有提升。
后来又有大神提出使用 DCL 双检查锁机制来实现多线程并发环境的单例对象模式。
public class SingleInstance {
private static SingleInstance INSTANCE;
private SingleInstance() {
}
public static synchronized SingleInstance getInstance() {
if (INSTANCE == null) { //1 第一次检查
synchronized (SingleInstance.class) { //2 加锁
if (INSTANCE == null) { //3 第二次检查
INSTANCE = new SingleInstance(); //4 对象实例化 , 问题所在
}
}
}
return INSTANCE;
}
}
上诉的解决方案在第一次检查 INSTANCE 不为 null,则不需要进行加锁操作和对象实例化操作,可极大降低 synchronized 带来的性能消耗。
解决方案看起来似乎是完美的,但这是一个完全错误的优化。
问题的根源出在第 4 个步骤对象实例化,在线程运行至该步骤时,可能拿到的对象的引用为 null。这其中有什么令人诡异的事情发生。
让我们好好回忆之前的指令重排序问题。
实际上,INSTANCE = new SingleInstance();这一步操作可以分解为 3 个步骤:
memory = allocateMemory(); //1-分配内存
initInstance(memory); //2-初始化内存
instance = memory; //3-实例对象 instance 指向 memory 位置
上诉三个步骤中 2 与 3 是存在指令重排序的可能性 (有些 JIT 编译器就会这么干)。2 和 3 指令重排序之后的执行顺序如下:
memory = allocateMemory(); //1-分配内存
instance = memory; //3-实例对象 instance 指向 memory 位置
initInstance(memory); //2-初始化内存










