正文
上一讲中我们完成了概括性内容的了解,今天对NCBI的具体资源的内容进行梳理。
NCBI(美国国家生物技术信息中心)的资源架构(上篇)
(
很明显,还有下篇哦)
在首页,我们可以看到上面的标题栏、跟在后面的检索框,中间的主体内容,以及底部的很多链接堆。看了真让人混乱,到底应该从哪里地方进入呢?我迷茫了很久,因为即使是中间的主体内容,准确的说是主体内容的目录也够复杂的。所以只有一个一个先看看到底是个啥么,然后才能重新在头脑中建立起一个整体概念。而事实上,也只有从这里面才能建立一个整体概念,如果跳过这一步骤,直接进入后面的步骤,很容易就混乱,并持续混乱下去,所有,这一过程又是很重要的。
我们按照从左到右,再从上到下的顺序,依次考察链接后,得到如下的架构体系。
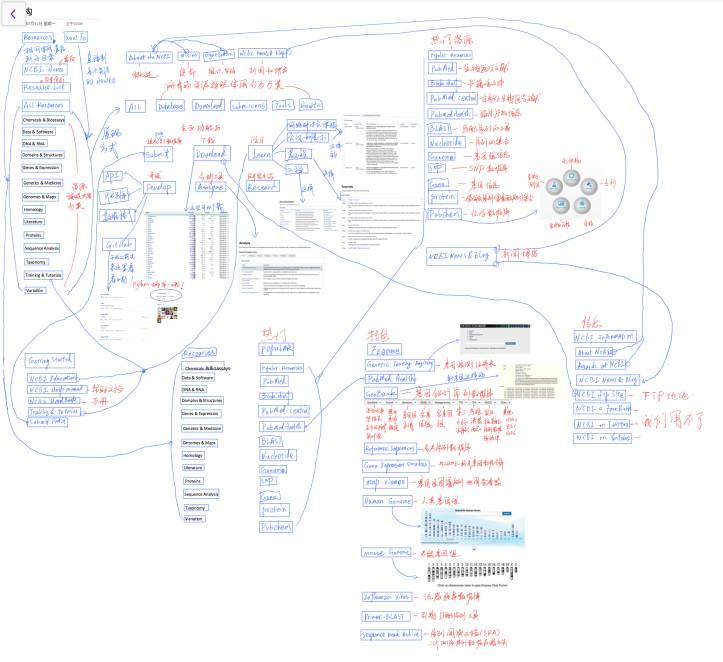
先吐槽一下,为什么左上角会有两个logo?

好的,先看这个比原文更加混乱的表,我画的。不过至少到现在我们明白了一件事情,为什么NCBI要在首页上辣么多东东了,目的就是减少中间环节,你所要的所有东西,全部在页面上可以找到最佳的路径直接访问到。这样的好处不言而喻,坏处就是不够有条理,第一次看上去感觉痛苦的不行。
言归正传,左上角的两个菜单分别叫
资源
(Resources)和
如何
(How To),名字起得显而易见,特别注意的是,仔细看上图可知,在左侧的菜单栏中,也有资源这一超链接叫做
所有的资源
(All Resources),这两个其实是一样的,而唯一左上角菜单的资源菜单的作用在于,点击下拉三角图标后,可见子菜单,移动到菜单项上后,还可以看到二级子菜单。也就是说左上角的资源菜单可以直接到最底层项目,而左侧菜单只能到中间的层次。我不啰嗦,点击一下就可以知道了。内容都是一样的,这里我没有把菜单项的名称标记上中文的原因是,我忘记了:)等到截完屏做出来就不好再添加上去了,但其实这反倒是一件好事情,因为真正所有的资源,后面我们会大量涉及的主体信息其实就是这些内容。熟悉英文的名称比直接看翻译的有意义。
虽然后面会大量提到,但是还是有必要先把内容梳理一遍,这里面包括的内容从上到下来。主页就不说了,
资源列表
(
Resource List)很有意思,是把所有的资源类,注意不是资源,的名称按照字母索引全部排列出来。当然我们看到表示完全无感,因为用的是英文首字母,而我们很多时候只知道中文是啥。我连查啥都不知道好不好。接下来的
所有资源
(All Resources)是把所有的资源类按照
数据库
(Databases)、
下载
(Downloads)、
提交
(Submissions)、
工具
(Tools)和
如何做
(How To)五个大类型全部进行分类。左侧列表中单个资源类的展现形式和这种展现形式是相同的,也是五个大类型。
这些单个的资源类分别是:
化学和生物测定
(Chemicals & Bioassays),
数据和软件
(Data & Software),
脱氧核糖核酸和核糖核酸
(DNA & RNA),
域和结构
(Domains & Structures),
基因和表达
(Genes & Expression),
遗传和医学
(Genetics & Medicine),
基因组和图谱
(Genomes & Maps),
同源性
(Homology),
文献
(Literature),
蛋白质
(Proteins),
序列分析
(Sequence Analysis),
分类法
(Taxonomy),
培训和教程
(Training & Tutorials),
变异
(Variation)。
需要
特别提醒
的
是,这个单个资源类的分法,并不是绝对的把资源们分成各种相互隔离的类别,倒好像是提供了从各种角度把松散的资源组织到一起的办法,其目的是便于人一次性的找到自己所需要的相关性比较大的资源子类的集合。比方说一个卖水果的网店,它可以把货物分成甜水果,酸甜水果,皮厚水果,贵的水果四个资源类。西瓜资源可能既属于甜水果有属于皮厚水果的分类。
•
化学和生物测定
(Chemicals & Bioassays)这里面包含的和化学有关的资源,生化生化,生物和化学从一开始就是分不开的。
•
数据和软件
(Data & Software)无疑这一条应该排到第二,信息化的使用是依靠大量的数据库和数据检索技术基础之上的。这里面就从计算机信息化的角度提供了各种数据库和检索工具。
•
脱氧核糖核酸和核糖核酸
(DNA & RNA)这里面包含了和DNA、RNA有关的所有资源容,这些都可以在这个分类里面找到,很多的。
•
域和结构
(Domains & Structures)这里面包含了和结构相关的资源,比如蛋白质的结构组成。
•
基因和表达
(Genes & Expression)基因通过某种方法表达出物种的各个形态,比如头发的颜色,翅膀的大小,这里面包含了基因和表达相关的所有资源,这里包含着几乎所有的内容。
•
遗传和医学
(Genetics & Medicine)这里面包含了基因和疾病相互有关系的资源。
•
基因组和图谱
(Genomes & Maps)这里面包含了基因组和图谱的资源,基因组是生物完整基因的组成形式,这里包含着几乎所有的内容。
•
同源性
(Homology)基因组的变化是在遗传的不变性基础上进行的,所以可以追溯他们的源头,这里有这方面的资源。
•
文献
(Literature)和文献有关的资源。
•
蛋白质
(Proteins)蛋白质肯定比基因的层次要高,毕竟组成人体嘛,这里有蛋白质相关的资源。
•
序列分析
(Sequence Analysis)这里面就一个流感病毒的数据库,加上一些通用的分类方法,不知道为什么叫这个名称。
•
分类法
(Taxonomy)万物同源但是随着演化发生了很多的变化,所以要分成很多类型,这就是相关的资源。
•
培训和教程
(Training & Tutorials)相关资源链接
•
变异
(Variation)遗传总是有变异,这里是相关的资源。
这些分类其实并不是分类,而是某一类资源的归类。我相信这些内容必然是从实际出发,对用户和研究者来说都很有效果的。到此为止,内容已经全部提到,后面的内容无外乎是这些资源的细分或者是相关信息以及工具。目前不需要有太深入的了解,有个粗浅认识,为后面的深入探索,提供一个大脑中的印象。
一般来说,但凡放到中间的,都是核心。全都如此,首页上在中间部分的除了欢迎词之外,下面的一排链接,在前面的第一章中已经有了详细翻译,不再赘述。重点是中间部分的水平中间部分六个块。其重要性和左侧列表的不同之处在于他们的功能性,也就是功能性最重要的六个块,六个功能吧。分别是
提交
(Submit),
下载
(Download),
学习
(Learn),
开发
(Develop),
分析
(Analyze)和
研究
(Reserch)。不管你想要用这个中心的资源来干什么,这里都提供,而最常用的就是这六种。我们分别介绍:
存储数据或者草稿(manuscripts),这个草稿指的是未经同行评议(peer-reviewed)的发现,到国家生物信息中心数据库中。
具体的种类包括:
•
核苷酸序列
(Nucleotid Sequences)包括GenBank和Sequence Read Archive(SRA)两个数据库;
•
基因组变异
(Genome Variations)包括单核苷酸多样性(SNP),变异数据库(dbVar),临床变异数据库(ClinVar),遗传检测注册表(Genetic Testing Resgistry(GTR));
•
实验研究和数据集
(Experimental Studies & DataSets)包括基因表达综合库(符合微阵列实验最小信息(MIAME)格式)(Gene Expression Omnibus(GEO)),序列读档案(Sequence Read Archive(SRA)),基因型和表型数据库(dbGap(The Database of Genotypes and Phenotypes)),生化试验数据库(PubChem BioAssay)
•
生物研究项目数据
(Biological Research Project Data)包括生物数据集合(BioProject)和生化试验原材料数据库(BioSample)
•
核苷酸和化学试剂
(Nucleotide & Chemical Reagents)包
括核酸试剂盒注册表(Probe)和样本描述数据库(PubChem Substance)
•
其他数据类型
(Other Data Types)包含国立医学研究院草稿提交系统(NIH Manuscript Submission System(NIHMS))
选择相应种类后,可以提交数据,并且可以查到如何提交的向导文档。这部分可以发现很多内容还是相互重合的,有些和前面提到的内容也都相关。其实也简单啊,就是那几个关键的数据库嘛。
介绍文字为:
传输国家生物信息中心的数据到你的电脑上。
这里提供了三个主要部分的内容以及一些辅助链接文档。
首先是FTP,可以从中打开文件夹,下图就是我电脑上打开的内容,速度有些慢,但是可以看到里面的大致构成。可以直接下载哦。
第二个内容就是Aspera。这本来是IBM公司的一个高速传输软件,使用了fasp传输技术。感觉使用了这个神器,就秒杀迅雷的感觉,达到只要担心你存储空间的大小的境界。
这个我安装了一个在电脑上,但是没用过,因为没机会用,空间已经满了。究其根本原因,因为最开始我比较傻,又没有老司机带路,使用了ftp往我的服务器上wget的时候,把我的磁盘空间都占满了。我用的是阿里云,值得夸赞的就是,我经常怀疑会传输到一半就完蛋,没想到吭哧吭哧的竟然把如此大的数据库文件都慢慢下载下载了,可见人家服务器的强健,和我阿里云的网络畅通。但是最后一个错误,怎么试都不行的时候。我才发现原来是硬盘占满了。
总之,总关系图中有一个截屏,可以看到这个软件把数据库文件目录组织的很好。顺便说这个软件已插件的方式起作用,打开网页就可以浏览和处理文件了。
第三个就是下载工具,特定在于定制能力强,可以定制某些数据集。包括Entrez程序集(Entrez Programming Utilites(E-utilities)),SRA(Sequence Read Archive)工具包(SRA Toolkit)和GEO2R,最后这个怪名字工具的怪名字表示它是一个基于R语言的GEO数据库下载工具。
GEO前面说过了,但是肯定无法容易一下子记住的名字,
基因表达综合库
(Gene Expression Omnibus):GEO是一个公开的基因组学
(genomics)数据仓库(repository),它支持符合MIAME(微阵列实验最小信息)标准的数据提交。接受基于数组和序列的数据。这个工具帮助用户查询和下载实验和策划(curated)的基因表达谱(gene expression profiles)。还有这三个工具的相关文档。
链接就是如何下载定制的数据集合,大数据下载的最好方法,SRA下载参考。
介绍文字为:
找到有帮助的文档,参加课程或者观看教程。
学习嘛比较容易理解,包含了四个部分的内容,
网络研讨会
和网络课程
(Webinars & Courses),
会议和展示
(Conferences & Presentations),
教程
(Tutorials)和
文档
(Documentation)。总关系图中有截图。
介绍文字为:
使用国家生物信息中心的API们和代码库来创建程序。
这里面呢有三个部分和一个外部链接。首先是
APIs
,懂得就懂,不懂的估计对这一段也不感兴趣了。简单介绍就是包括E-utilities、BLAST URL API 和化学文献强力用户网关(PUG(PubChem Power User Gateway))等的程序接口。简单说明一下就是这些东西都是写好的程序,你可以通过调用这些程序来获取一些数据,并且根据调用这些程序时的参数,来定制你想要的数据。上面的等这个字,其实就是生化文献中心(PubMed Central(PMC))APIs,可能是地方不够用了的缘故。
其次就是
代码库
(Code Libraries),用来维护国家生物信息中心数据的公开的软件库,就是很多软件啦。包括:
•
国家生物信息中心C++工具包
,C++是一种强大的编程语言,这个工具包是一个应用程序的框架,既然是框架那就不简单是一些可调用的函数和类啦,是一个脚手架,可以趴在上面用各种函数操作数据库中的内容。
•
SRA 工具包
,包含工具的可执行文件和源码,可以直接下载,这些工具主要是处理二代测序的结果,这些结果用国家生物信息中心SRA结构存储的,SRA是一种格式名称,如同word文档,就是用特定格式存储的文本文件,和txt的文本文件的类型是不一样的,必然强大了哦。
•
国家生物信息中心GitHub仓库(NCBI GitHub Repository)
,这个词要这样断,这是个在GitHub上面的仓库,里面放的国家生物信息中心的很多工具。GitHub是啥呢?是程序员们放自己写出来的代码的地方。放在那里有啥好处呢?就是可以做版本管理,每一次修改都给你存起来。如果使用免费的空间,那就必须要公开,谁都可以看和下载。有时候大牛看到了,可以拷贝一份帮你改一改,改过的你觉得太好了,就直接给大牛发一个「拉」请求,把大牛改的那个拷贝,拉过来覆盖你自己的版本。如果你使用私人的空间,或者公司用的,那就花钱租一个,公司的人自己用。总之,这是一个程序员扬名立万的地方。上面有很多好用的东西,Android的源码也在上面。
再次就是
数据格式
,由于各家的数据库使用不同的格式存储数据,那相互之间就无法自动读取,存储到另一个库中。所以为了统一标准,就规定了这些东西。
最后的链接就是
GitHub
,和前面的代码库中的重复。我表示始终对国家生物信息中心的分类之诡异佩服的很。最后还突然冒出来几个链接,开发视频教程,指导如何使用来开发使用E-UTILITIES的。
介绍文字为:
为你的数据分析任务选择一个国家生物信息中心工具。
里面可以看到,我们提供了好多好多的分析工具哦,你们都可以用来
操作(manipulate),排列(align),可视化(visualize)
和
评估(evaluate)
生物数据。
里面分了六个类:
文献类、健康类、基因组类、基因类、蛋白质类
和
化学类
。
基因组、基因和蛋白质三个类的工具最多。
这里面的分析工具和前面的提到的很多内容还是重复的,也就是说,这里是提供了一个目录,把很多相关的内容收集到一起,便于你使用。
介绍文字为:
展示了国家生物信息中心的研究和协作项目。
额,此文前文完整翻译过,名为国家生物信息中心计算生物学分支(NCBI Computational Biology Branch)。
再一次分类思想点赞,我已经晕了。










