来源 |
CSDN
作者 | 谢宜廷
开讲前,先给大家看个深度强化学习的例子,下面是深度学习cnn和强化学习结合玩吃豆人的游戏。
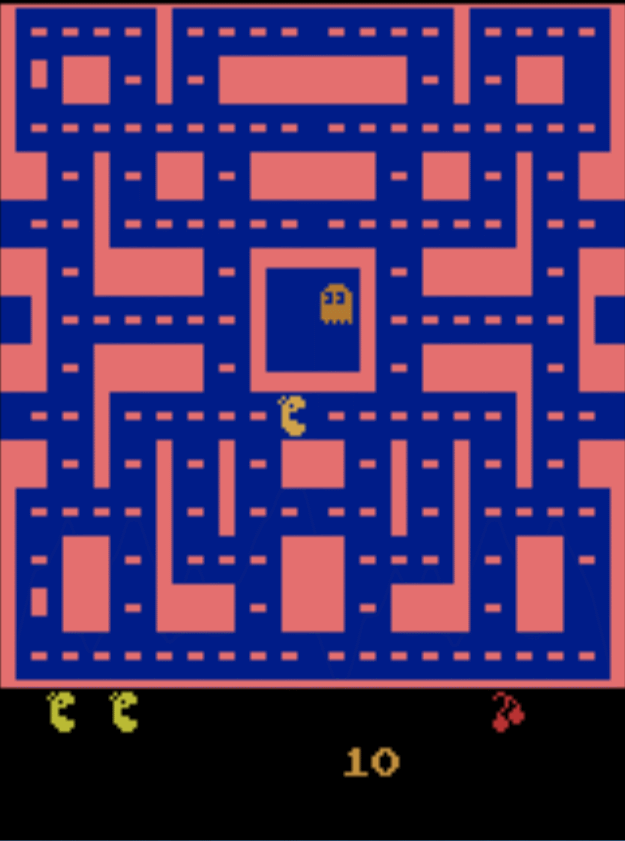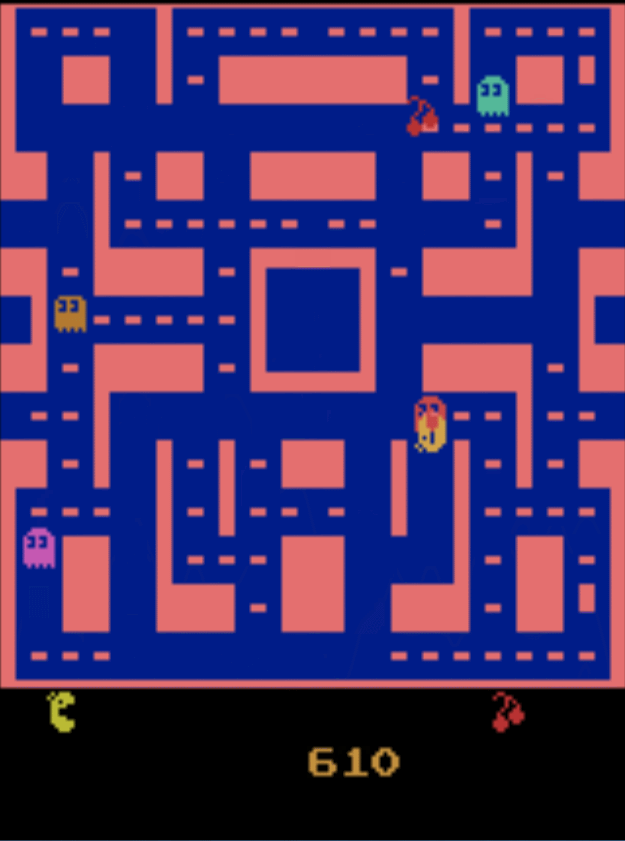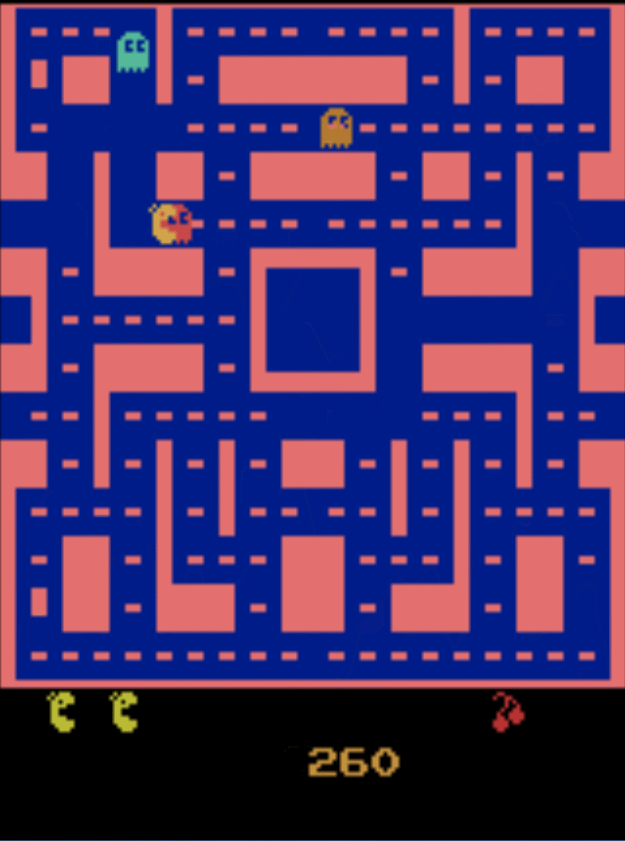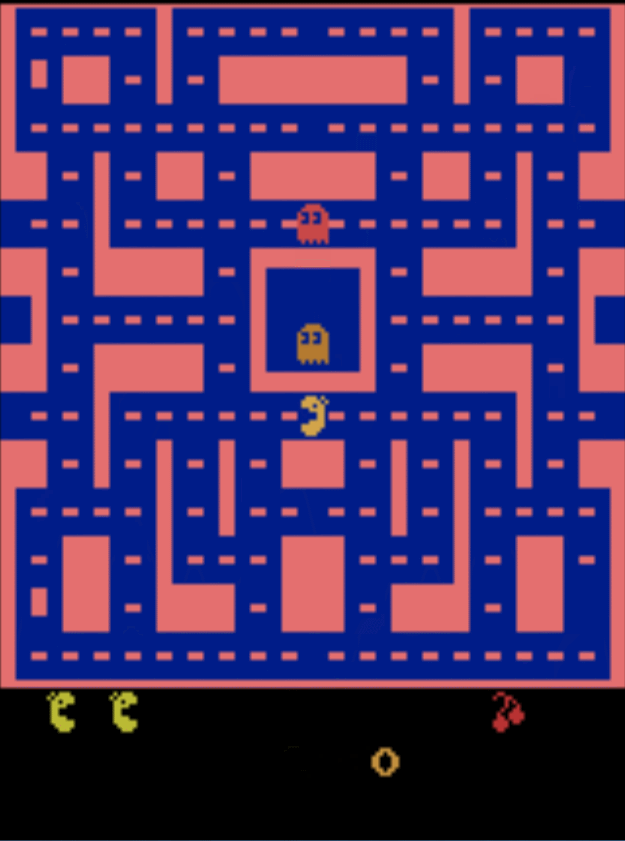
看图像我们会发现吃豆人会,吃掉一闪一闪的豆子来消灭怪物,仔细观察会发现,经过训练的吃豆人,甚至会停在某个角落来躲避怪物,这是一个非常有趣的现象,后面会附有个人深度强化学习项目地址。下面我们开始正式介绍强化学习。
强化学习的原理和解释
强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体而言:机器处在一个环境中,每个状态为机器对当前环境的感知;机器只能通过动作来影响环境,当机器执行一个动作后,会使得环境按某种概率转移到另一个状态;同时,环境会根据潜在的奖赏函数反馈给机器一个奖赏。综合而言,强化学习主要包含四个要素:状态、动作、转移概率以及奖赏函数。
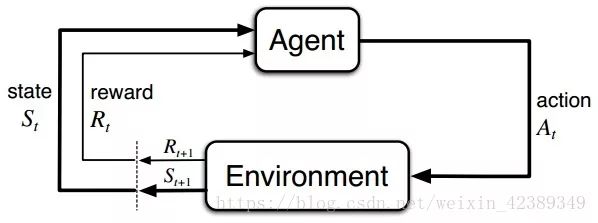
根据上图,agent(智能体)在进行某个任务时,首先与environment进行交互,产生新的状态state,同时环境给出奖励reward,如此循环下去,agent和environment不断交互产生更多新的数据。强化学习算法就是通过一系列动作策略与环境交互,产生新的数据,再利用新的数据去修改自身的动作策略,经过数次迭代后,agent就会学习到完成任务所需要的动作策略。
强化学习和机器学习
强化学习是机器学习的分支之一,但是又区别于其他机器学习,主要体现在:

-
无特定数据,只有奖励信号
-
奖励信号不一定实时
-
主要研究时间序列的数据,而不是独立同分布的数据
-
当前行为影响后续数据
从1.1基本原理我们可以看的强化学习和其他机器学习算法监督学习和无监督学习的差别。监督学习和无监督学习都需要静态的数据,不需要与环境交互,数据输入到相关函数训练就行。而且对于有监督学习和无监督学习来说,有监督学习强调通过学习有标签的数据,预测新数据的标签,无监督学习更多是挖掘数据中隐含的规律。
主要算法和相关分类
根据上面的原理,其实我们可以得到,强化学习关键要素:agent(智能体),reward(奖励),action(行为),state(状态),environment(环境)。
强化学习算法按照agent分类,可以分为下面几类:
-
关注最优策略(Policy based)
-
关注最优奖励总和(Value based)
-
关注每一步的最优行动(Action based)
从不同角度也可以继续细分,具体可以看下图:
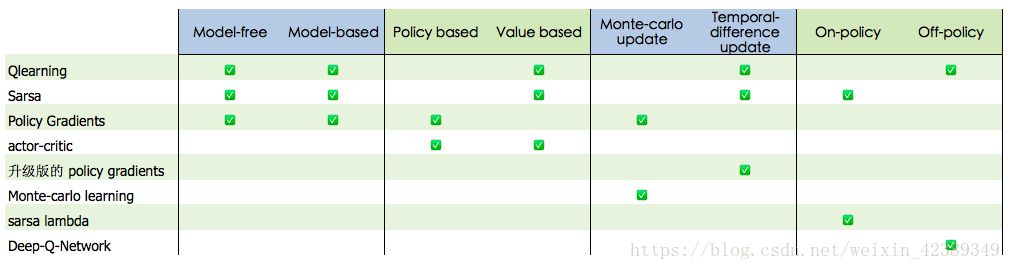
下面我们简单介绍分析一下Qlearning和Sarsa
(1) Qlearning

(2)Sarsa

从表格我们知道,Qlearning是on-policy,而Saras是off-policy。 对于Saras,当agent处于状态s时,根据当前Q网络以及一定的策略来选取动作a,进而观测到下一步状态s',并再次根据当前Q网络及相同的策略选择动作a',而Qlearning则是,根据当前Q网络计算出下一步采取哪个动作会得到maxQ值,并用这个Q值作为当前状态动作对Q值的目标。
简单来说,Saras是agent处于新状态s',就知道要采取行动a',并且执行了,行动的选择根据策略,Q值的计算是根据动作a',而Qlearning是agent处于新状态s',只能知道采取哪个行动可以得到maxQ,并没有采取对应行动,它是根据当前Q和策略来采取行动的。在后面我们会做详细分析。
传统的强化学习局限于动作空间和样本空间都很小,且一般是离散的情境下。然而比较复杂的、更加接近实际情况的任务则往往有着很大的状态空间和连续的动作空间。当输入数据为图像,声音时,往往具有很高维度,传统的强化学习很难处理,深度强化学习就是把深度学习对于的高维输入与强化学习结合起来。
2013和2015年DeepMind的Deep Q Network(DQN)可谓是将两者成功结合的开端,它用一个深度网络代表价值函数,依据强化学习中的Q-Learning,为深度网络提供目标值,对网络不断更新直至收敛。2015 DQN nature算法可以看下图:

DQN用到了两个关键技术涉及到了两个关键技术:
1、样本池(Experience Reply):将采集到的样本先放入样本池,然后从样本池中随机选出一条样本用于对网络的训练。这种处理打破了样本间的关联,使样本间相互独立。
2、固定目标值网络(Fixed Q-target):计算网络目标值需用到现有的Q值,现用一个更新较慢的网络专门提供此Q值。这提高了训练的稳定性和收敛性。
DQN在Atari games上用原始像素图片作为状态达到甚至超越人类专家的表现、通过左右互搏(self-play)等方式在围棋上碾压人类、大大降低了谷歌能源中心的能耗等等。当然DQN也有缺点,它是高维输入,低维输出的,当涉及到一次性输出连续动作时,即高维度输出,就束手无策了,DeepMind也在后续提出了DDPG。
根据前面知识可以意识到强化学习本身是非常通用了,智能体可以自己学习,如果和深度学习结合岂不是万能?错了,当前深度强化学习也有许多难点:
-
样本利用率低,需要长时间训练
-
很难设计奖励函数
-
对环境过拟合,比如去玩打砖块很擅长,却很难去适应俄罗斯方块
-
不稳定,函数对参数很敏感,参数的变动,模型会千差万别
未来可能方向:
-
与迁移学习结合,适应不同环境
-
硬件提升
-
融合更多的模型学习,充分利用样本
-
自主设定奖励函数
强化学习用例
强化学习适用于许多行业,包括互联网广告和电子商务、金融、机器人和制造业。让我们仔细看看这些用例。
个性化
新闻推荐
。
机器学习通过分析客户的偏好、背景和在线行为模式的数据,使企业能够大规模地个性化客户交互。然而,推荐像在线新闻这样的内容类型仍然是一项复杂的任务。新闻特写本质上是动态的,很快就会变得不相关。主题中的用户首选项也会发生变化。
DRN:新闻推荐研究论文的深度强化学习框架的作者讲述了与新闻推荐方法相关的三个主要挑战。
首先,这些方法只尝试模拟当前(短期)奖励(例如,显示页面/广告/电子邮件浏览者点击链接的比率的点击率)。
第二个问题是,当前的推荐方法通常将点击/不点击标签或评级作为用户反馈来考虑。
第三,这些方法通常会继续向读者推荐类似的新闻,这样用户就会感到厌烦。研究人员使用了基于深度q学习的推荐框架,该框架同时考虑了当前奖励和未来奖励,以及用户反馈而不是点击数据
。
个性化的游戏。
游戏公司也加入了个性化派对。真的,为什么不考虑个人玩家的技能水平、游戏风格或偏好的游戏玩法来定制电子游戏体验呢?
游戏体验的个性化是通过玩家建模来实现的,其目的是增加玩家的乐趣。
玩家模型是基于玩家在游戏中的行为对其进行的抽象描述。可以改编的游戏组件包括空间、任务、角色、叙事、音乐和声音、游戏机制、难度缩放和玩家匹配(在多人游戏中)。
RL可用于实时优化游戏体验。在边缘设备的游戏个性化强化学习中,研究人员以Pong游戏为例,展示了这种机器学习技术的能力。
Unity为研究人员和开发人员提供了一个ML工具集,它允许通过一个简单的Python API通过强化学习和演进方法来训练智能。值得一提的是,我们还没有发现RL智能体在生产中的任何应用。
电子商务和互联网广告
专家们正在试验强化学习算法,以解决eBay、淘宝或亚马逊(Amazon)等电子商务网站的印象分配问题。印象是指访问者看到网页、广告或带有描述的产品链接的某些元素的次数。印象通常用来计算广告客户在网站上展示自己的信息需要支付多少钱。每次用户加载一个页面并弹出广告时,它都被视为一种印象。
这些平台的目标是最大限度地从交易中获得总收入,这就是为什么它们必须使用算法,将买家印象(显示买家对商品的要求)分配给最合适的潜在商户。
大多数平台使用协作过滤或基于内容的过滤等推荐方法。这些算法使用依赖于卖家交易历史的历史分数,对具有相似特征的客户进行排名。卖家通过实验价格来获得更高的排名位置,而这些算法没有考虑定价方案的变化。
为了解决这一问题,研究人员应用了一种通用的强化机制设计框架。该框架使用深度强化学习来开发评估卖家行为的有效算法。网上商家还可以通过欺诈交易来提高自己在电子商务平台上的排名,吸引更多的买家。据研究人员称,这降低了利用买家印象的效率,并威胁到商业环境。
但是,通过强化学习,可以在提高平台利润、减少欺诈活动的同时,完善平台的印象分配机制。在关于AI和DS的进展和趋势的文章中,我们讨论了另一个RL用例实时投标策略优化。它允许企业动态分配广告活动预算在所有可用印象的基础上,即时和未来的奖励。在实时竞价过程中,广告客户对一种印象进行竞价,如果他们中标,他们的广告就会显示在出版商的平台上。
金融行业交易
金融机构使用人工智能驱动的系统来自动化交易任务。
通常,这些系统使用监督学习来预测股票价格。他们不能做的是决定在特定情况下采取什么行动:买进、卖出或持有。交易员仍然需要制定业务趋势跟踪、基于模式或反趋势的规则来管理系统选择。另一个问题是,分析人员可能以不同的方式定义模式和确认条件,因此需要一致性。
宾夕法尼亚大学计算机科学教授迈克尔卡恩斯(Michael Kearns)于2018年6月被摩根士丹利(Morgan Stanley)股票交易公司聘用。
此外,交易员还可以了解到最合适的行动时间和/或最佳的交易规模。IBM在其数据科学体验平台上构建了一个利用强化学习的金融交易系统。
IBM的艾西瓦娅•斯里尼瓦桑说:“该模型利用每一步的随机行为对历史股价数据进行训练,我们根据每笔交易的盈亏来计算回报函数。”开发人员使用积极的投资回报来评估model s的性能。主动回报是基准与实际回报率(以百分比表示)之间的差异。
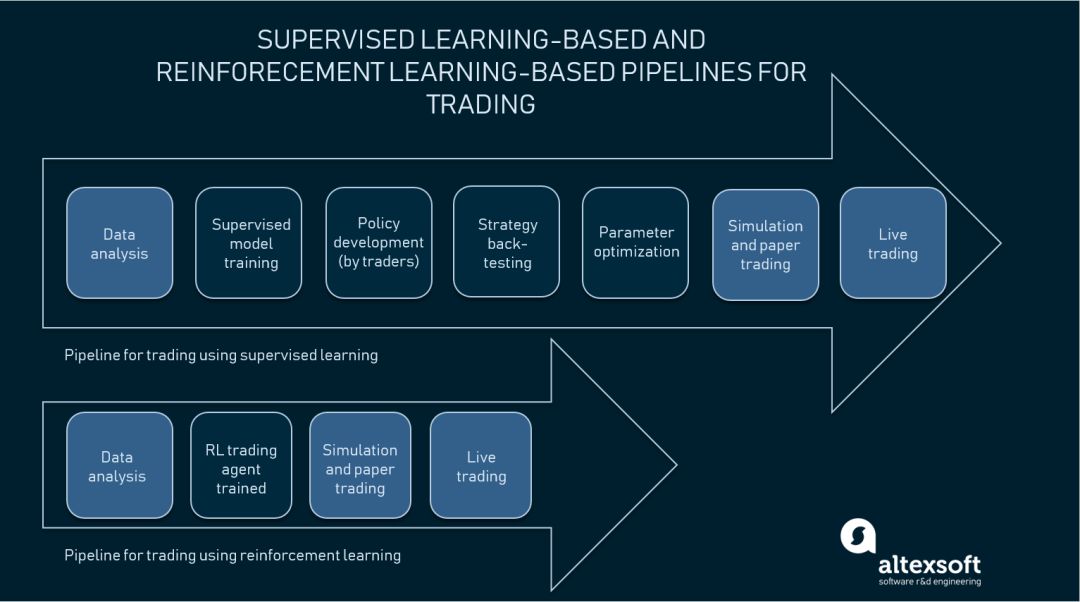
基于监督学习和强化基于学习的交
易管道
图片模版:
IBM Analytics/Inside Machine Learning on Medium
专家们还根据代表市场总体走势的市场指数来评估投资的表现。最后,我们以简单的买入持有策略和ARIMA-GARCH策略来评估模型。斯里尼瓦桑说:“我们发现,这个模型可以根据市场走势进行非常精确的调整,甚至可以捕捉到头部和肩部的模式,这些都是可以预示市场反转的重要趋势。”
自主车辆的训练
强化学习已被证明是一种有效的方法,用于训练为自动驾驶汽车系统提供动力的深度学习网络。英国公司Wayve声称是第一家在RL的帮助下开发无人驾驶汽车的公司。
开发人员通常会编写大量手写规则来告诉自动驾驶车辆如何驾驶,这导致开发周期变慢。Wayve的专家选择了另一种方式。他们只花了15-20分钟的时间教会一辆汽车从零起步,经过反复试验。
在一次实验中,一名人类驾驶员坐在车里,当算法出错,一辆车偏离轨道时,他进行了干预。该算法在不进行干预的情况下进行长距离驾驶。通过这种方式,汽车在虚拟世界中学会了在每次探险中安全驾驶。研究人员在他们的博客中解释了训练方法的技术细节。
机器人
机器人学中的许多问题可以表述为强化学习问题。机器人通过探索,从环境中获得反馈,学习最优的连续动作,以最大的累积回报完成任务。开发人员不会给出解决问题的详细说明。
《机器人研究中的RL》的作者指出,强化学习为复杂和难以设计的行为设计提供了一个框架和一系列工具。来自谷歌Brain Team和X公司的专家介绍了一种可伸缩的强化学习方法,用于解决训练机器人基于视觉的动态操作技能的问题。其具体目标是训练机器人掌握各种物体,包括在训练过程中看不见的物体。
他们将深度学习和RL技术相结合,使机器人能够不断地从他们的经验中学习,提高他们的基本感觉运动技能。专家们不必自己设计行为:机器人会自动学会如何完成这项任务。专家们设计了一种深度Q-learning算法(QT-Opt),该算法利用了过去训练期间收集的数据(抓取尝试)。
在四个多月的时间里,7个机器人在800个小时内接受了1000多个视觉和物理上不同的物体的训练。通过对摄像机图像的分析,提出了机器人应该如何移动手臂和抓手的建议。

机器人正在收集抓取数据。来源:
Google AI Blog
这种新颖的方法使得在700次测试中,对先前看不见的物体进行抓取的成功率达到96%。专家们之前使用的基于监督学习的方法显示成功率为78%。结果表明,该算法在不需要太多训练数据的情况下也能达到这样的精度(尽管训练时间更长)。
工业自动化
RL具有广泛应用于机械和设备调优的工业环境的潜力,以补充人类操作员。
Bonsai是提供深度强化学习平台的初创企业之一,为建立自主的工业解决方案以控制和优化系统的工作提供了一个深度强化学习平台。
例如,客户可以提高能源效率,减少停机时间,增加设备寿命,实时控制车辆和机器人。您可以收听O Reilly Data Show播客,在该播客中,
Bonsai
首席执行官和创始人描述了公司和企业各种可能的RL用例。
谷歌利用强化学习的力量变得更加环保。科技公司 IA research group, DeepMind,开发和部署了RL模型,该模型帮助冷却数据中心减少了高达40%的能源消耗和15%的总能源开销。
5.在商业中实施强化学习的挑战










