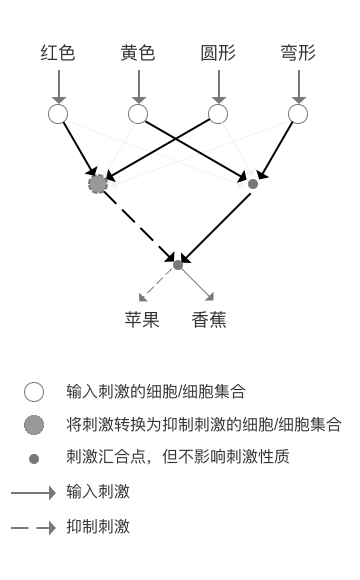
原创:
许铁
混沌巡洋舰
我在过去对人工智能简史的描述中,把人工智能的整个历史描述成围绕一张规则表, 本文是基于这一想法的总结和扩展。我们说,早期的AI发展史围绕如何人为构建这样一个规则表解决复杂问题, 而当下的AI则围绕如何让它在复杂的现象中自己归纳出这个规则表。
我们说,上帝通过制定规则从简单演绎出复杂。最初的原始人类在黑暗中摸索, 在众多的现象不知所措, 只能通过设立各色大神小神来缓解自己对不确定性的恐惧。 从多神宗教到一神宗教的跨度体现了一个从复杂中寻找简单的跨度, 这可能是基于一种隐隐的直觉,就是现象虽然多样, 但是背后的法则不应该如此复杂。 到了科学的时代, 这种思维在物理学里淋漓尽致起来,四大力学, 把分子原子间的作用力统一到电磁力, 把宏观物体的作用统一到引力和经典的动力方程, 已经是极致。 而后面的对这两者的统一构成了从广义相对论后的现代物理主线。
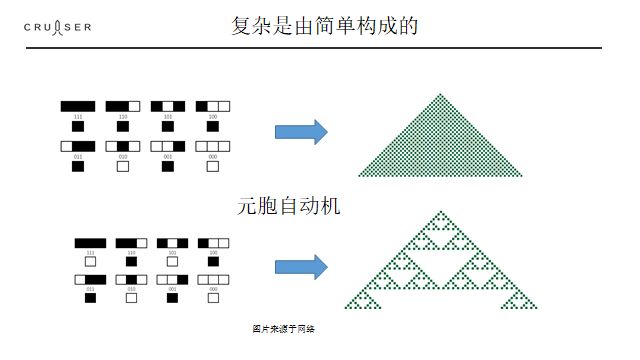
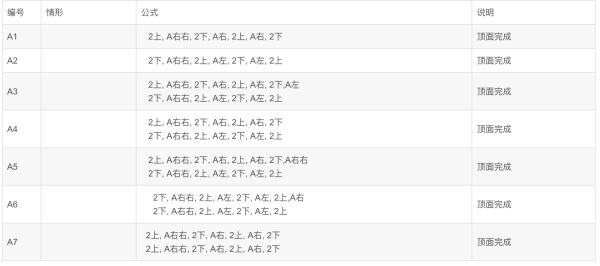
图: 简单规则生成复杂的极好例子, 元胞自动机, 每一步细胞的繁殖和扩散方法一定(左图黑格表述的, 从上一行到下一行的变化法则), 它最后形成的图案就定了, 规则可以很简单, 图案可以很复杂。
早期的智能: 制定规则表 - 迭代

另一方面,这样的思想从智能科学诞生之出,也贯穿出来。它在早期的可计算性中, 通过图灵机的构建。它认为存在这样的通用机器,能够和人类一样解决问题, 即使过程非常复杂, 你无非需要四个要素:
1, 输入 2, 中间状态 3, 规则表 4, 输出。
并在时间上进行大量迭代, 就可以实现这个过程。 通过这个过程, 我们可以把一个输入转化为一个想要的输出。 如果我们能够在在有限的步骤里将一个输入转化为一个输出,据此解决一个实际问题, 那么这个问题就是可计算的。
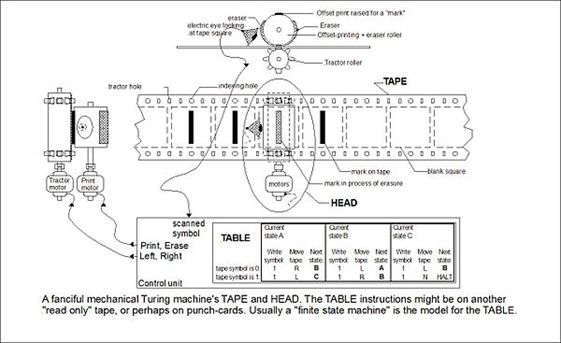
图: 图灵纸袋, 一个在纸袋上根据一定规则表行走的机械昆虫, 机械昆虫具有一个内部状态, 并接受外部的输入,最终通过规则表找到对应的下一步输出。
而冯诺依架构让它变成一个技术现实。 它通过可以存储程序的机器, 让人们通过把这些图灵规则表的指令变为计算机二极管的开合代码, 而让图灵纸袋的思想成为了一个每个工程师可以设计的现实,从此有了程序和程序员。
一个计算机程序, 最基本的部分包括一些简单的形式逻辑, 包括逻辑与或非, if else, for 循环这些。 其实本质上, if else 所描述的就是规则表, 规则里面通常涉及简单的逻辑, 最终通过for循环, 我们就可以得到我们要的东西。 比如一个中学生都会的排序算法, 我们无非需要做的是前面和后面的数比较大小, 然后一个if else进行换位, 最后一个for循环, 多长的序列都可以瞬间搞定。
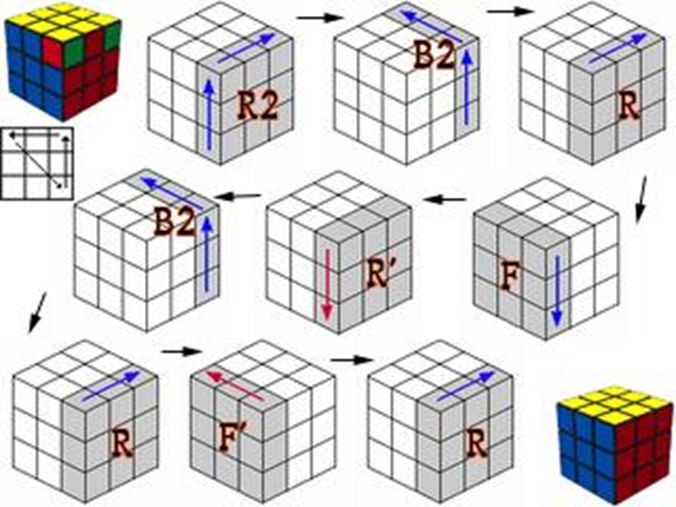
这就是用程序解决问题的核心思维, 给你一个再复杂手忙脚乱的问题, 只要这个问题可计算, 那么我们只需要设定好我们需要的规则表, 在有限的步骤里迭代, 最终机器总会给你解决。
比如魔方问题, 一般的聪明小孩都很难在短时间解决问题, 但是, 事实上解决魔方问题有一套非常整齐的规则表(你想象打乱一个魔方其实比较容易的, 把它弄整齐是打乱的逆运算,但是破镜重圆总是难的)。 如果按照这个规则表执行若干步, 再困难的魔方也给你整出来。
我们说规则表, 加上迭代等操作的思路可以解决大量的工程问题。我们曾经认为按照这样的思路我们可以解决整个智能的问题。 只是填入一张越来越大的表格。
但是它在通向智能的关键位置, 却停住了, 这个元凶 -就是-
不确定性
。日常生活中很多东西无法轻易的总结出规则表来, 因为细小的规则实在太多了。 你可以想象我们有无数尺寸和规格各不相同的螺钉螺母。 每一种规格我们都要想一条if else,可悲的是这些螺钉和螺母几乎没有哪两对完全相同, 穷尽一个程序员一生也写不完这些程序。现实生活中的大部分问题属于这一类问题, 比如你无法轻易的写出一段程序来判断A男和B女是否合适结婚。
中期的智能: 让机器学会归纳规则表
统计机器学习 - 机器判断规则
这个问题的解决方法十分自然又十分了不起: 能不能让机器自己学会这个表格, 而不是认为设定它呢? 这就是整个智能问题的第二步 - 学习。
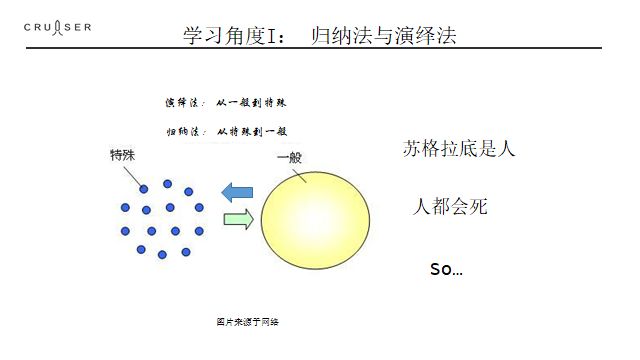
整个学习问题的基石其实是古希腊人提出的归纳法和演绎法。
伟大的希腊哲学家早就对学习的本质展开过探讨,它们把学习分类为
归纳法和演绎法
。所谓演绎法, 就是从用一定规则进行推理的过程。 苏格拉底是人,人都是会死的, 因此苏格拉底会死。这就是三段论, 或者称为演绎法的根基。 而真正学习的过程,是这个演绎法的逆过程。我们先知道一个特例,然后通过特例,得到这个“人都是会死的” 知识,再指导自己的行动。 学习是知识在脑子或者机器里面形成的过程, 怎么形成? 这个过程被称为归纳法,也就是根据搜集到的特例比如苏格拉底死了这个事情,来归纳更一般的知识。
让机器实现归纳法, 我们来看我们需要提供给机器怎样的佐料来解决这个问题。
我们想象这样一台机器, 这个机器和之前说的规则机器类似, 唯一的区别是, 我们把大量的假设放在那里,让机器来连线。 我们要让它学习一个知识, 比如-什么人是否会死的。我们把人按照几个特征进行分类, 一个特征对应一个问题, 比如是否是哲学家, 是男还是女, 是白种人还是黄种人。 这些特征, 都对应会死或不会死这两个结论。 这样,你会得到多少个假设呢? 组合数学告诉我们16种, 于是学习的任务就是给这16个假设和真或者假连接起来。 一旦一条线连起来, 我们就得到了一个新的知识,可以被用于在真实的世界做判断! 就和之前说的规则机器一样。

我们首先给这个机器灌入所有的可能性, 那16种假设。 然后我们让机器来收集案例!比如机器收集到一个苏格拉底死了, 那么苏格拉底是什么? 男性,白种人, 哲学家, 于是机器得到男性, 白种人, 哲学家,会死。 于是机器给机器输入亚里士多德, 柏拉图, 大卫休谟,机器都会告诉你会死。然后我们继续收集样例, 比如居里夫人死了, 然后机器会得到女性,白种人, 非哲学家,死了。 这样它能够做的判断就又多了很多!
我们直接把规则转化为了可以学习的对象。输入样例,得到一个是非的知识, 这个样例我们换个词叫数据, 这个机器我们换个词– 叫做分类器。
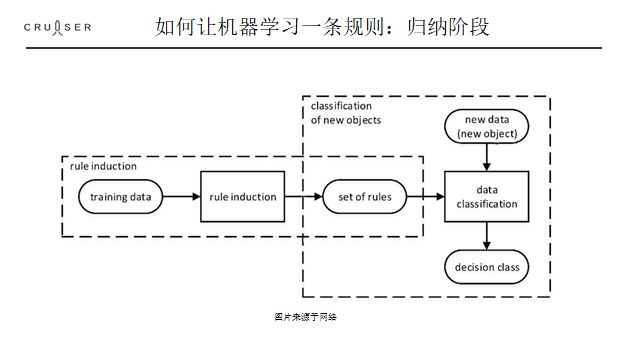
整个有关统计的机器学习, 都可以看成让机器学习有效归纳的方法, 从数据里得到规则表, 再用规则表进行判断。前面的过程叫训练, 后面的过程叫测试。
如果这些规则是有关一个是非的命题, 它就是一个分类器, 如果它是一个连续数值的预测, 就是回归。 但是规则表的本质是不变的, 它就是让你填表,表格的横排和竖排已经有了, 一个叫特征, 一个叫实例。 特征是人为归纳好的, 而实例是我们人为收集的, 表格中有些地方是空的, 就是我们想要判断的东西, 需要机器来填的部分。 比如给你一百幸福和不幸的人的案例, 让你判断第101个人的情况。
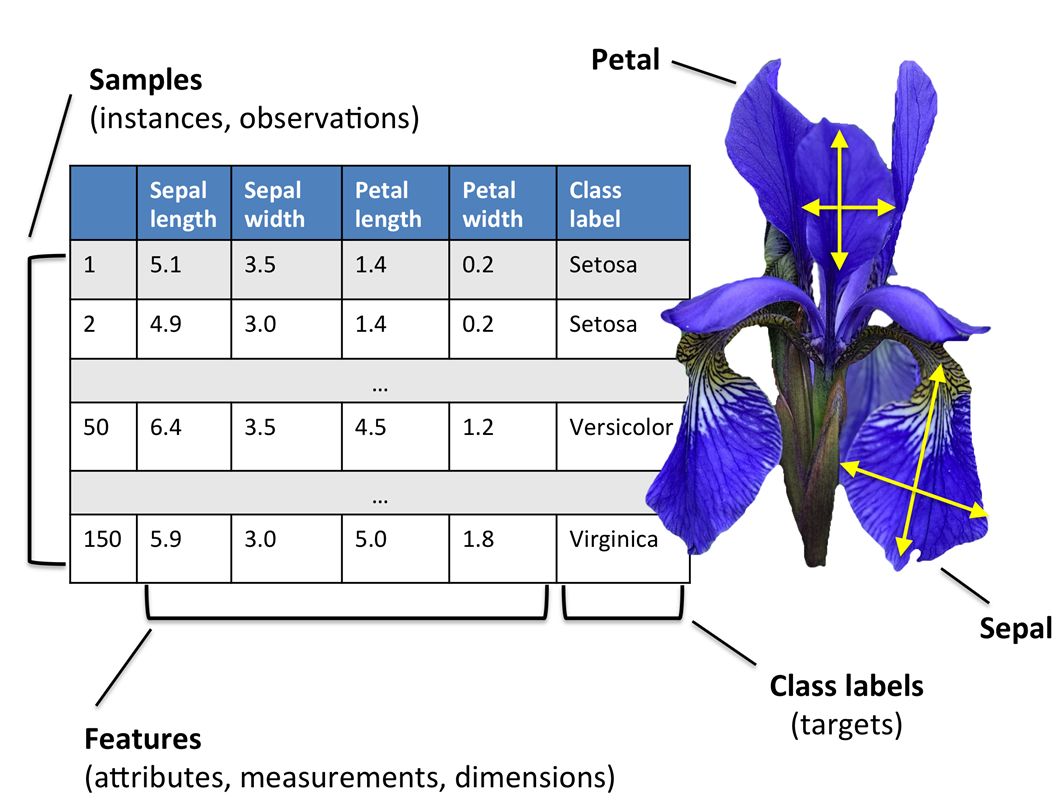
图:机器从实例中学到分类的方法: 机器学习
刚刚的那个例子你应该已经体会到, 这个命题验证过程其实是一个组合爆炸的问题。我们把关于这个世界的互相矛盾的假设都丢尽机器。即使最简单的问题也会有无穷多的情况要判断 (特征的n次方)这种假设的数量随着问题的复杂度急速指数上升的过程,我们称之为维度灾难。

而机器学习的各个算法, 让我们通过加入更多的假设, 来偷懒解决这个问题, 此处没有比决策树更典型的, 它的高阶版本xgboost成为机器学习竞赛的杀手锏。
而决策树得核心智慧就是优先级算法简化命题数量。 虽然特征很多, 但是并不是每个特征都一样重要, 我们如果先按照最重要得特征进行判断, 依此往下, 你可能不需要2得N次方个情况, 而是按照树结构做N次判定即可。 优先级, 也是人类智慧得核心。事实上, 我们永远在抓轻重缓急,在抓主要矛盾, 无论是有意的还是无意的,当然大部分人的轻重缓急是按照时间来的,时间比较近的就是比较重要的, 这也是为什么很多人有拖延症。
很多人说到优先级算法很想到相亲, 其实这也是一种人类思维自然使用的决策树, 比如女生找男朋友通常心理都有一个优先级构成的树, 首先, 对方的年龄多大? 如果对方年龄大于50岁直接pass, 然后看工资,如果工资小于20万直接pass,工资在20和30万间看下学历, 学历小于本科直接pass。 这其实就是一个决策树的结构。 每次pass, 就减少掉了一半需要判定的命题。 通过这种预设的二叉树逻辑, 一个本来需要2的n次方的步骤解决的事情, 可能只要n步了。
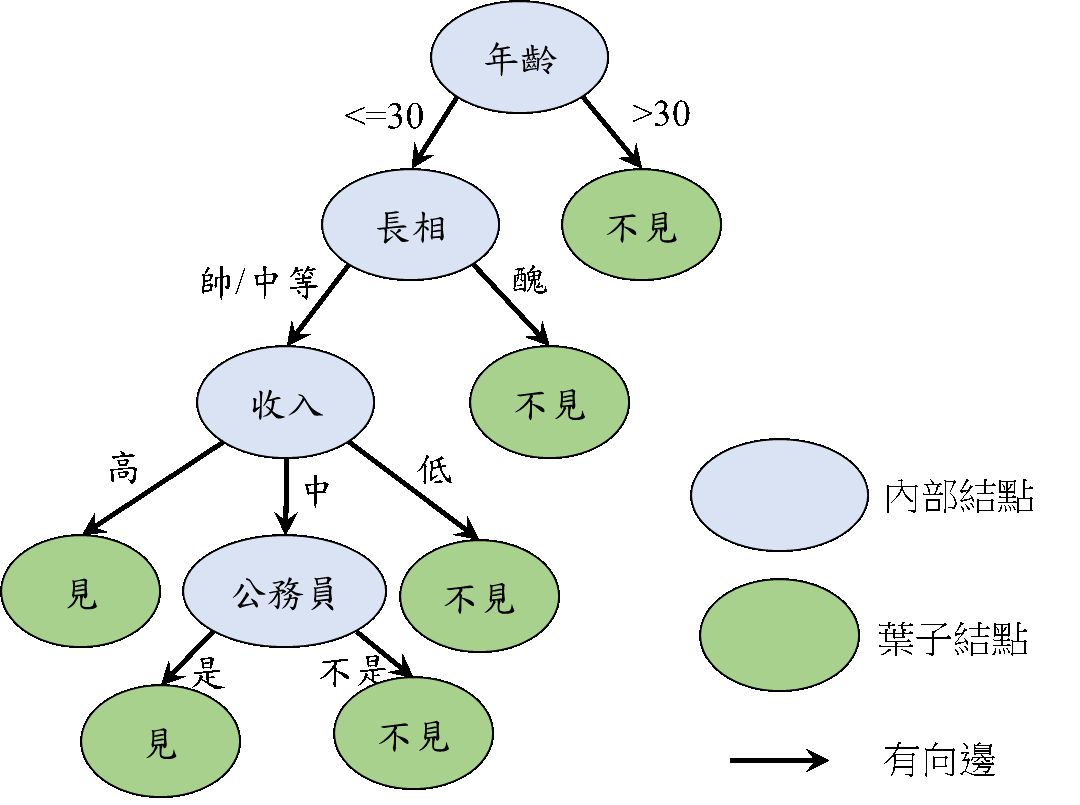
具体如何来学,树的根部是你选择的第一个特征, 更好的角度是把特征看成一个问题,树的根部是你要问的第一个问题, 根据这个问题的回答, 数据会在左边右边分成两组。 然后在每个答案的基础上, 你继续问下一个问题, 所谓的决策树的分叉, 每个枝杈就是一个新的问题。
如此,就会形成一个树的结构。构建这个树的主要难点, 在于要由机器决定哪个问题先问, 哪个问题后问, 如何选择这个优先顺序?我的要求就是, 每一次分化,我们都希望取得最多的信息,如分叉后一个树杈全是yes,一个全是no就是最好的效果, 如果达不到, 也让它尽可能接近这个效果。 这样一个一个问题问下去, 最终达到稳定后过程停止。 这样形成的决策树, 我们会形成任何一个情况下的优先级。 或许长的帅的人工资不重要。 或许学历高的人年龄不重要。 这种不同情况不停调整优先级的思维, 真的是被决策树利用到了极致! 从原始数据里提炼的决策树, 可以对无限的新情况进行预测。
另一个得到这样的一个规则表的方法是线性假设。 线性分类器通过假定特征之间的相互独立, 使得命题的成立与否可以通过一个加权求和的关系表达, 即f=wx+b 。最后f如果大于0就是是, 小于0就是否。 线性分类器也是一种特别符合人认知习惯的模型:一般人在决策时候做的事情就是加权平均,比如你平时做分类(决策), 你最想的一种状态是什么?你要把几个核心的要素放到一起, 按照他们的重要性加和,比如你今天要不要去看电影,可能取决于你的女朋友free否, 下不下雨和电影好不好看, 这个时候,我们可以把这些因素加权在一起, 在和一个我们给定的阈值做比较,大就去, 不大就不去, 这正权衡得失的做法, 就是线性分类器。线性分类器看上去是一个数学公式, 本质还是一个规则表, 只不过这里要学习的规则无非是每个特征给多少权重。最后在表格最后一列得到yes or no。
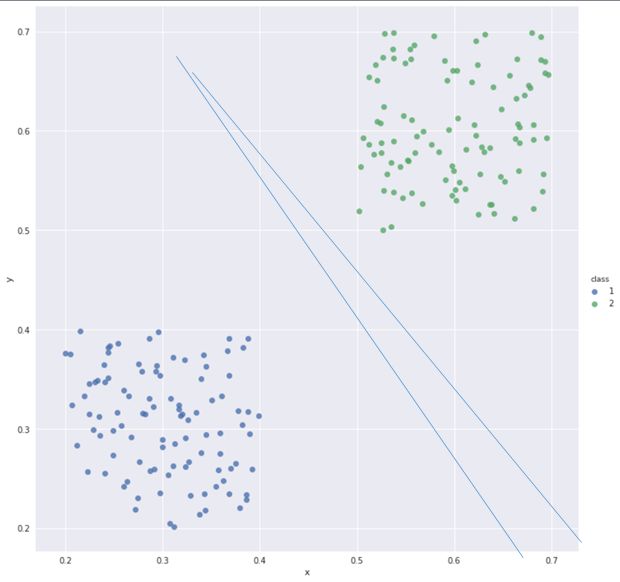
图: 线性分类器, 一条直线代表一组权重, 把两组数据分的越开越好。
具体学习的过程, 我们从实例里归纳出每个特征对应的权重参数,然后进行判断。 只要参数都确定了, 也就是一次解决了所有的问题。 线性分类器的高级版本SVM已经超越了线性假设。 也是小数据下生成有效规则的大杀器。
近期的智能: 让机器生成有效的规则
连接主义机器学习, 产生规则
刚刚说的那一套, 有一个问题你有没有注意到? 我们最先提出的问题是让机器产生一个规则表, 而刚刚说的统计机器学习里, 更多的是让机器根据定好的特征收集数据进行命题判断。 这其实离我们说的让机器自己得到规则表只进行了0.5步。
大家想象下, 在真正的实践活动里, 你无法一开始就设定出一堆特征让它进行逻辑判断,在这个情况下如何得到我们所说的“规则”呢?
如何让机器自己生成战胜“复杂”的程序呢? 连接主义机器学习在一定程度解决了这个问题。 因为, 人类认识事物,生成规则, 其实是通过“
概念
”来的, “概念”是一个浓缩的信息载体, 通过它我们能够进行任何更复杂的推理。 那么“概念”是如何生成的呢? 它的载体正是下面说的联结主义的代言人神经网络。
神经网络
首先,神经网络是由神经细胞组成的。 一个神经细胞就是一个最小的认知单元, 何为认知单元,就是把一定的数据组成起来,对它做出一个判断, 我们可以给它看成一个具有偏好的探测器。 联系机器学习,它就是刚刚说的线性分类器。
正确的分类,是认知的基础,我们对事物的感知比如色彩,物体的形状等,其实都是离散的,而物理信号是连续的,比如光波,声波。这里面的中间步骤就是模数转化,把连续的信号转化成离散的样子,这正是一个分类器干的事情。一个单个神经元可以执行一个简单的基于感知信号的if else语句。 先收集一下特征做个加和,if大于一个值我就放电,小于我就不放电,就这么简单。晶体管当然也在干这个事情。 神经细胞与晶体管和计算机的根本区别在于可塑性。或者更准确的说具有学习能力。从机器学习的角度看, 它实现的是一个可以学习的分类器,就和我们上次课讲的一样, 具有自己调整权重的能力, 也就是调整这个w1和w2.
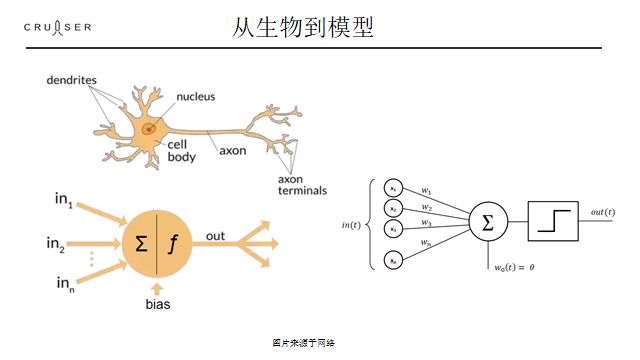
我们这个简化出来的模型,正是所有人工神经网络的祖母-感知机。从名字可以看出,
感知机算是最早的把连接主义引入机器学习的尝试。
它直接模拟Warren McCulloch 和 Walter Pitts 在1943 提出而来神经元的模型, 它的创始人 R 事实上制造了一台硬件装置的跟神经元器件装置。
单个的感知机并不能比传统的机器学习多做一丁点的事情, 还要差一些。 但是把很多个感知机比较聪明的联系起来,就发生了一个质变。
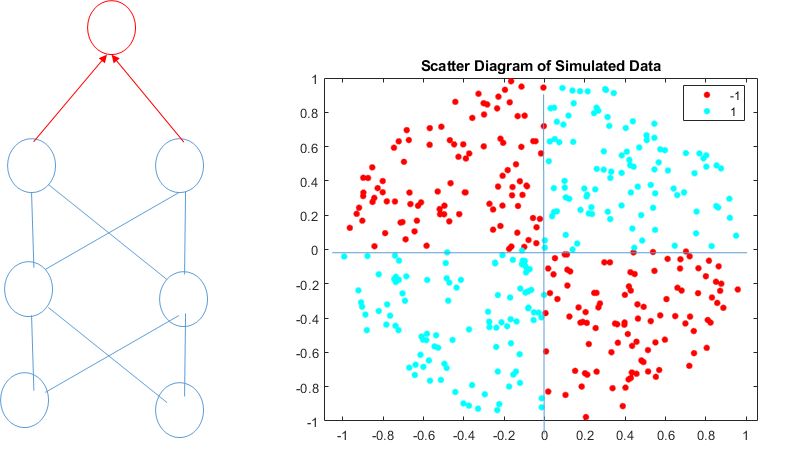
首先, 每个线性分类器, 刚刚讲过都是一个小的特征检测器, 具有自己的偏好,这个偏好刚好用一个直线表示,左边是yes,右边是no, 那么多个神经元表达的是什么呢? 很多条这样yes or no的直线! 最终的结果是什么呢?我们得到一个被一条条直线割的四分五裂的结构, 既混乱又没用! 这就好比每个信息收集者按照自己的偏好得到一个结论。所以, 多个神经之后,我们还要在头顶放一个神经元, 它就是最终的大法官, 它把每个人划分的方法, 做一个汇总。 大法官并不需要什么特殊的手段做汇总,
它所做到的,无非是逻辑运算, 所谓的“与”, “或”, “非”, 这个合并方法,把哪些被直线分开的四分五裂的块,就可以得到一个非常复杂的判决结果。
你可以把大法官的工作看成是筛选, 我们要再空间里筛选出一个我们最终需要的形状来, 这有点像是小孩子玩的折纸游戏,每一次都这一条直线, 最终会得到一个边界非常复杂的图形。 其实这里面做的事情, 正是基础的逻辑运算, 一个简单的一层神经网络可以执行与或非这些基本的逻辑操作。事实上它的本质就是把简单的特征组合在一起形成一些原始的概念。
它是怎么做到的呢? 学习。 生物神经网络的学习, 是通过一种叫做hebbian可塑性的性质进行调节的。 这种调控的法则十分简单。说的是神经细胞之间的连接随着它们的活动而变化, 这个变化的方法是, 如果有两个上游的神经元同时给一个共同的下游神经元提供输入, 那么这个共同的输入将导致那个弱的神经元连接的增强, 或者说权重的增强。 这个原理导致的结果是, 我们会形成对共同出现的特征的一种相关性提取。 比如一个香蕉的特征是黄色和长形, 一个猴子经常看到香蕉, 那么一个连接到黄色和长形这两种底层特征的细胞就会越来越敏感, 形成一个对香蕉敏感的细胞,我们简称香蕉细胞。 也就是说我们通过底层特征的“共现” 形成了一个简单的“概念”。 上述过程被总结hebian学习的一个过程。 我们可想象,一个两层以上的神经网络, 就可以表述香蕉, 苹果, 菠萝这些水果了, 它们无非是底层特征颜色,形状的不同组合而已。 而这些不同水果的概念, 就可以帮助我们形成更加复杂的规则表 ,比如让它根据客户的信息帮它推荐一个水果拼盘。 由此可见, 神经网络通过与或非进行简单特征的组合 ,再通过if esle进行判断选择合适的特征得到概念, 再通过下一层迭代得到概念有关的命题。 就可以生成比之前的传统机器学习复杂的多的规则表。而且我们可以想象出来, 迭代的层数越多,它生成的“概念”和“规则”就越复杂。
当然真实训练中我们用到的不是模仿生物版本的hebbian学习, 而是强大的多的反向传播算法。
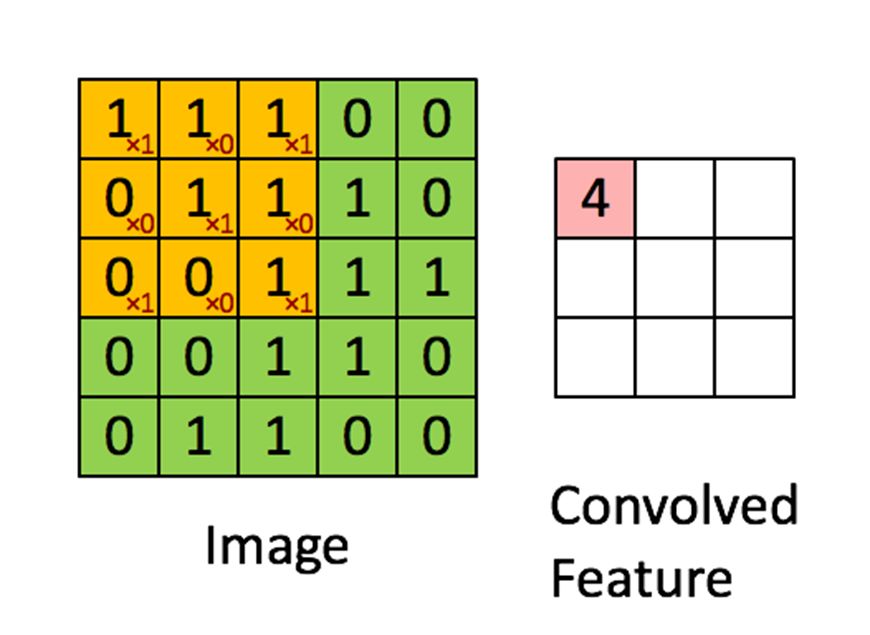
事实上为了让这种生成“概念”得到“规则”的方法更加有效, 我们会加入一些无比强大的先验假设。 其中最有名的一组, 就叫CNN,它所做的,其实是针对于图像这类巨大无比而局部特征不断重复的数据形式, 你可以写一个循环, 来让你的程序更有效。 循环里的每一步都对图像的局部特征进行提取, 由一个可以共用的卷积核实现。 卷积核一点点的卷过图像上的每个小块, 也就是循环的总体。 卷积核在每个图像局部做的, 事实上都是一个小的if esle 语句。 if像素之间符合某个关系,就是yes,否则No。这个结果, 最后被综合出来, 给下一层合成更复杂的图像特征。我们事实上通过学习的过程,让机器自动补全了循环每一步的这个if else语句。
好了,到目前为止, 说的都是和时间无关的规则。 而一开始讲到的真实的图灵机, 是和时间有关的规则。 那么如何得到一个和时间有关的规则表呢? 如果要处理和时间相关的信息, 你必须要引入记忆,引入内部状态, 而和刚刚说的一样, 这些含时间的规则要是可以学习的,用数学的语言说, 就是要有一个连续可微的载体, 这个东西就是RNN。
def step
(self, x):
# update the hidden state
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
# compute the output vector
y = np.dot(self.W_hy, self.h)
return
y
以上是RNN的python程序定义。 它说的无非是你有一个刚刚说的线性分类器组成的单隐层神经网络,但是这一回,神经网络的输出,要作为输入,重新回到神经网络的隐层里, 这个关键的增加, 就使得它具有了处理复杂时间信息的能力。
这个结构,非但优雅,而且有效。一个非常重要的点是, 你知道信息的传播是有损耗的, 如果把RNN展开, 它事实上相当于一个和历史长度一样长的深度网络, 信息随着每个时间步骤往深度传播, 这个传播的信息是有损耗的, 到一定程度我就记不住之前的信息了, 当然如果你的学习学的足够好, Wij还是可以学到应该学的记忆长度。
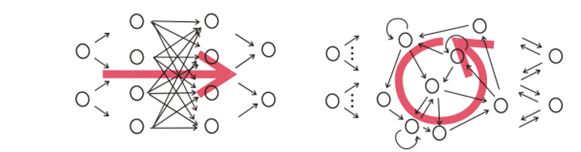
事实上叫做“循环神经网络” 循环的本质是什么呢? 它其实正是你的程序里的for循环啊! RNN的本质是, 在每个时间步里进行同样的操作, 这个操作无非是, 当下的输入, 和神经网络的状态两部分特征的逻辑组合(与或非)然后, 这个组合的结构进行一个if else的逻辑判断, yes or no, 根据这个,生成一个输出的结果, 这个结果, 要回传给神经网络隐层, 生成下一个隐层状态。 大家看这其实就是图灵机的定义啊, 而RNN的本质, 就是一个可以通过微分方法学习的图灵机啊。 虽然每个步骤的规则和执行足够简单, 但是只要步数足够多, 却可以产生非常复杂的结果。
RNN学习的本质, 就是给你那个足够复杂的结果, 让你反演出那个足够简单的规则, 然后让它在新的环境下再去做预测与决策。 我们可以看到, 这已经非常接近智能的本质了。 那么RNN有没有可能学到真正类似人类的抽象思考能力, 具备人类类似的生成规则的能力呢? 这可能才是后面真正的问题。
让机器生成有关未来的规则-强化学习
强化学习
果说监督学习的基本框架已经是在生成用于判断(分类)的规则表, 那么强化学习, 就是生成一套直接用于行动的规则表, 这套语言的元素包括
状态, 行为, 观测, 奖励
。 事实上, 强化学习所做的事情是从成功或失败的经历里去归纳行为的准则。
我开头讲的解魔方的问题, 如过让机器自己找到最短时间完成它的方法, 这就是强化学习所做的事情。
首先看
状态
s, 状态是什么呢? 它指的是智能体(agent)所在的环境里所有和游戏有关的信息,
再来看行为,所谓行为,是指智能体的
决策
,某种情况下我们可以认为它就是监督学习要求的那个y, 或者预测, 但一个决策与预测不同的是,我们并不能马上取得一个信号告诉我们这个决策对不对, 只有在游戏的最后 ,我们才能从整个游戏的收益反观当时的决策好坏。
寻找到从根据当下的状态s行动的一张规则表, 让我有最好的机会拿到奖励, 就是强化学习在做的事情。
而深度强化学习呢? 它就是把刚说的连接主义通过概念生成规则的方法,和此处的决策联系起来得到的框架。
我们还差很远
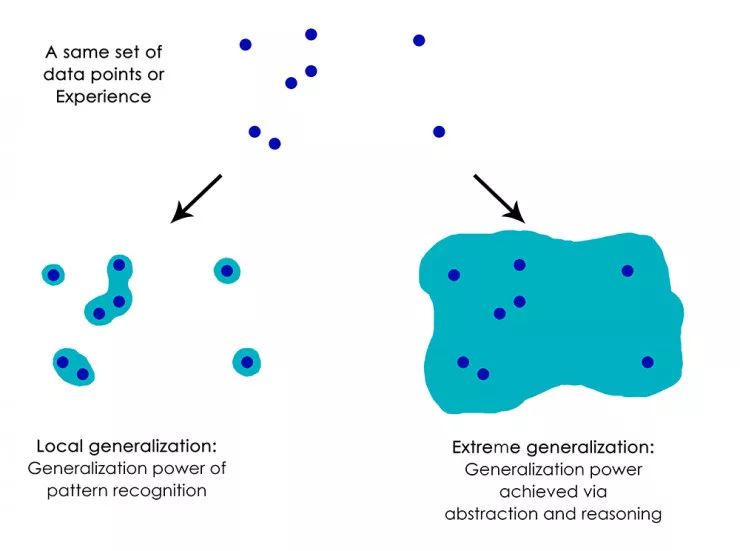
说到所有上述的东西, 你会觉得我们已经无所不能, 既然机器能够自己填写程序, 自己生成规则表来适应多变的世界, 那我们还差什么呢? 我们说都是生成规则, 不同的规则效力差距万千,而目前的AI在此处也就是个小学生。 亚里士多德和牛顿都观测力学现象, 亚里士多德看到的是轻的气体向上飘,重的东西向下沉。 牛顿看到的是受力与加速度的关系。 这两种规则的归纳即使都能解释现象, 但是它们的泛化能力确是千差万别, 一个可以解释全宇宙, 另一个也就适应一些物体吧。 如同下图所示, 坏的规则总结只能解释数据实例周边一丁点的地方, 而好的规则呢, 它可以把点连城片!
我们说人类总结的规则解释力最强的地方是物理 ,因为物理里描述了客观实体间作用的因果联系,而非简单的相关性。 这恰恰是目前AI所不足的。
有关物理的世界和智能的世界
上面的这些思考无疑开始让人们想象我们所说的包含了逻辑推理, 情感,甚至意识的问题与物理世界的关系到底是什么。 我们说物理的世界里, 主宰一切的是微分方程。 一切因果关系, 都由微分方程所承载。 你有了不同不同微观粒子电磁力的描述,把它们放入薛定谔和狄拉克方程, 你就可以推出原子的不同性质。 这其实可以说是因果推理的极致了。 它甚至导致了机械的宿命论思想。当一切初始的原因输入系统, 那么它就回归于一个必然的结果。








