前戏
半个月前,Amusi还费了九牛二虎之力安装了PyTorch v0.3.0,真的相当麻烦。前两天,PyTorch官网就发布了v0.4.0,官方支持Windows下的PyTorch安装,两行命令即可安装,实在方便!
github官网:
http://pytorch.org/
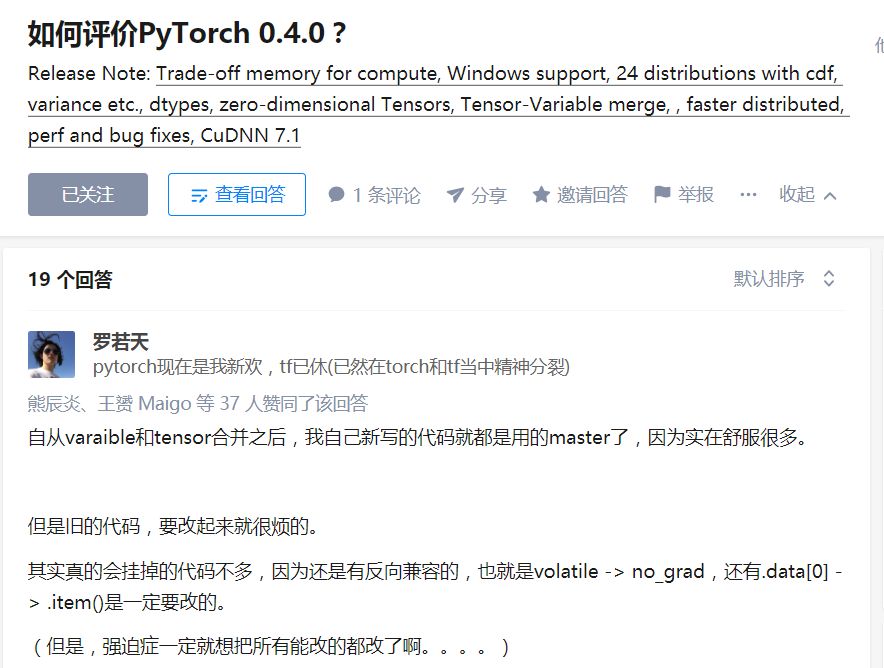
PyTorch v0.4.0一出,知乎就炸了~,来看一下大神们的评价

正文
以下为PyTorch v0.4.0更新内容目录:
主要核心变更
-
Tensor/Variable合并
-
零维张量
-
dtypes
-
迁移指南
新功能
-
张量
-
神经网络
-
torch.distributions
-
分布式训练
-
易于使用的Launcher utility
-
NCCL2后端
-
C ++扩展
-
Windows支持
-
ONNX改进
-
性能改进
-
Bug修复
主要核心变化
以下是用户每天使用的最重要的核心功能的更新。
主要变化和潜在的重要更新:
-
Tensors 和 Variables 已经合并
-
有些操作会返回0维(标量)Tensors
-
弃用了 volatile flag
改进:
PyTorch团队编写了一个迁移指南,帮助用户将代码转换为新的API和style。 如果您想要迁移以前版本的PyTorch中的代码。
迁移指南
:http://pytorch.org/2018/04/22/0_4_0-migration-guide.html
本部分的内容(主要核心变更)包含在迁移指南中。
合并 Tensor 和 Variable 类
torch.autograd.Variable 和 torch.Tensor 现在是同一类。更确切地说,torch.Tensor 能够跟踪历史并像旧的 Variable 一样运行;Variable 的换行继续像以前一样工作,但返回的对象类型变成 torch.Tensor。这意味着你不再需要将代码中的任何 Variable wrapper。
Tensor 的 type( ) 已经改变
还要注意 Tensor 的 type( ) 不再反映数据类型。使用isinstance()或 x.type()来代替:
1x = torch.DoubleTensor([1, 1, 1])
2print(type(x))
3<class 'torch.autograd.variable.Variable'>
4print(x.type()) # OK: 'torch.DoubleTensor'
5'torch.DoubleTensor'
6print(isinstance(x, torch.DoubleTensor))
7True
高潮
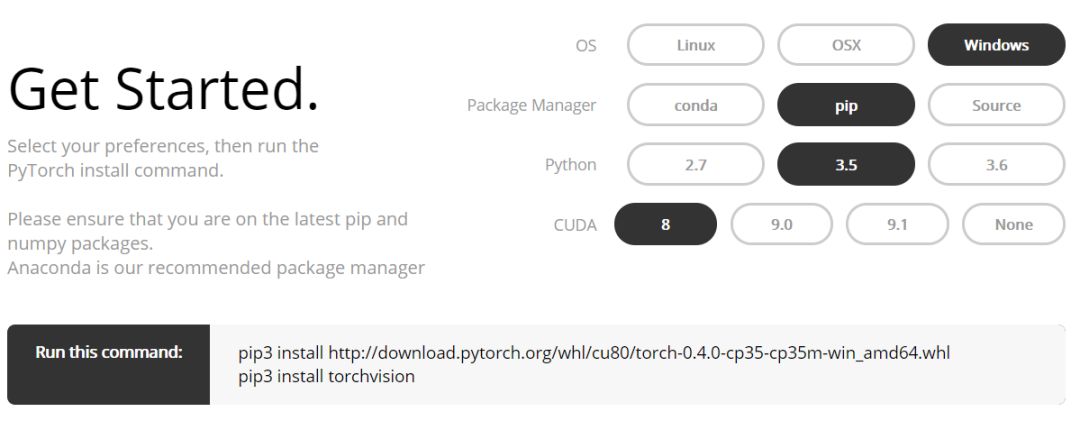
下面Amusi介绍一下在Windows下安装PyTorch0.4.0的教程
注意:建议先用Anaconda创建一个虚拟环境,再使用pip安装
下载安装
创建虚拟环境,命名为pytorch4
激活pytorch4
根据提示下载并安装pytorch4
测试安装是否成功
-
python
-
import torch
-
print(torch.__version__)
如果输出0.4.0,那么恭喜Windows下的PyTorch0.4.0安装成功!
MNIST测试示例
新建PyTorch_MNIST.py,写入
1
2
3
4
5
6from __future__ import print_function
7import argparse
8import torch
9import torch.nn as nn
10import torch.nn.functional as F
11import torch.optim as optim
12from torchvision import datasets, transforms
13from torch.autograd import Variable
14
15
16parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
17parser.add_argument('--batch-size', type=int, default=64, metavar='N',
18 help='input batch size for training (default: 64)')
19parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
20 help='input batch size for testing (default: 1000)')
21parser.add_argument('--epochs', type=int, default=10, metavar='N',
22 help='number of epochs to train (default: 10)')
23parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
24 help='learning rate (default: 0.01)')
25parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
26 help='SGD momentum (default: 0.5)')
27parser.add_argument('--no-cuda', action='store_true', default=False,
28 help='disables CUDA training')
29parser.add_argument('--seed', type=int, default=1, metavar='S',
30 help='random seed (default: 1)')
31parser.add_argument('--log-interval', type=int, default=10, metavar='N',
32 help='how many batches to wait before logging training status')
33args = parser.parse_args()
34args.cuda = not args.no_cuda and torch.cuda.is_available()
35
36torch.manual_seed(args.seed)
37if args.cuda:
38 torch.cuda.manual_seed(args.seed)
39
40
41kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
42"""加载数据。组合数据集和采样器,提供数据上的单或多进程迭代器
43参数:
44dataset:Dataset类型,从其中加载数据
45batch_size:int,可选。每个batch加载多少样本
46shuffle:bool,可选。为True时表示每个epoch都对数据进行洗牌
47sampler:Sampler,可选。从数据集中采样样本的方法。
48num_workers:int,可选。加载数据时使用多少子进程。默认值为0,表示在主进程中加载数据。
49collate_fn:callable,可选。
50pin_memory:bool,可选
51drop_last:bool,可选。True表示如果最后剩下不完全的batch,丢弃。False表示不丢弃。
52"""
53train_loader = torch.utils.data.DataLoader(
54 datasets.MNIST('../data', train=True, download=True,
55 transform=transforms.Compose([
56 transforms.ToTensor(),
57 transforms.Normalize((0.1307,), (0.3081,))
58 ])),
59 batch_size=args.batch_size, shuffle=True, **kwargs)
60test_loader = torch.utils.data.DataLoader(
61 datasets.MNIST('../data', train=False, transform=transforms.Compose([
62 transforms.ToTensor(),
63 transforms.Normalize((0.1307,), (0.3081,))
64 ])),
65 batch_size=args.batch_size, shuffle=True, **kwargs)
66
67
68class Net(nn.Module):
69 def __init__(self):
70 super(Net, self).__init__()
71 self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
72 self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
73 self.conv2_drop = nn.Dropout2d()
74 self.fc1 = nn.Linear(320, 50)
75 self.fc2 = nn.Linear(50, 10)
76
77 def forward(self, x):
78 x = F.relu(F.max_pool2d(self.conv1(x), 2))
79 x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
80 x = x.view(-1, 320)
81 x = F.relu(self.fc1(x))
82 x = F.dropout(x, training=self.training)
83 x = self.fc2(x)
84 return F.log_softmax(x)
85
86model = Net()
87if args.cuda:
88 model.cuda()
89
90optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
91
92def train(epoch):
93 model.train()
94 for batch_idx, (data, target) in enumerate(train_loader):










