选自add-for
作者:Pedro Gusmão
机器之心编译
参与:李泽南、黄小天
最近,Pedro Gusmão 等人对于英伟达的四种 GPU 在四种不同深度学习框架下的性能进行了评测。本次评测共使用了 7 种用于图像识别的深度学习模型
。
第一个评测对比不同 GPU 在不同神经网络和深度学习框架下的表现。这是一个标准测试,可以在给定 GPU 和架构的情况下帮助我们选择合适的框架。
第二个测试则对比每个 GPU 在不同深度学习框架训练时的 mini-batch 效率。根据以往经验,更大的 mini-batch 意味着更高的模型训练效率,尽管有时会出现例外。在本文的最后我们会对整个评测进行简要总结,对涉及到的 GPU 和深度学习架构的表现进行评价。
GPU、深度学习框架和不同网络之间的对比
我们使用七种不同框架对四种不同 GPU 进行,包括推理(正向)和训练(正向和反向)。这对于构建深度学习机器和选择合适的框架非常有意义。我们发现目前在网络中缺乏对于此类研究的对比。
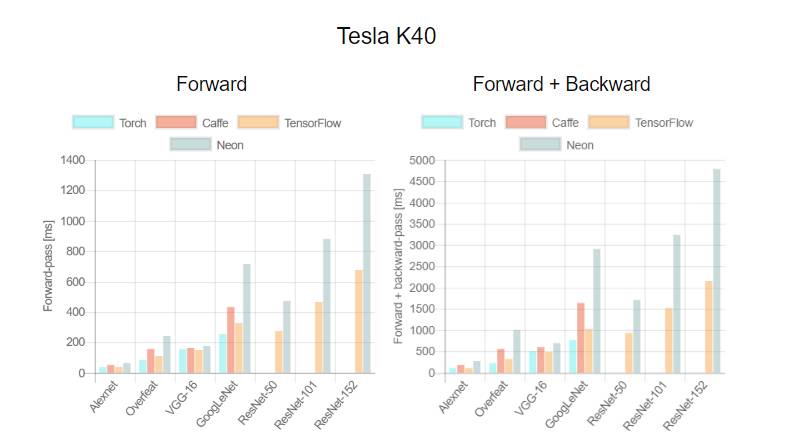
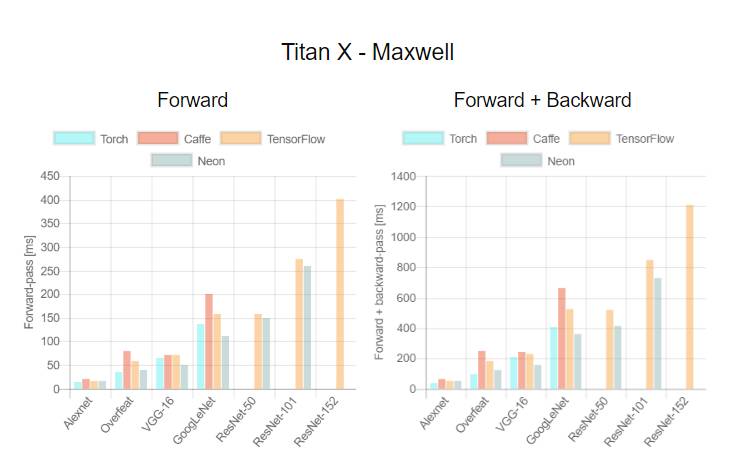
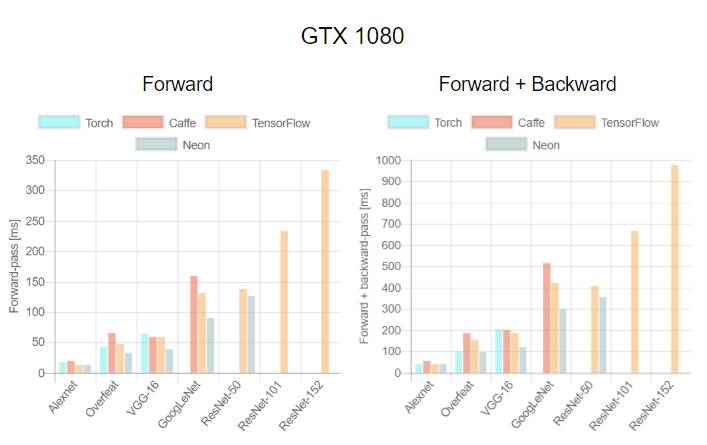
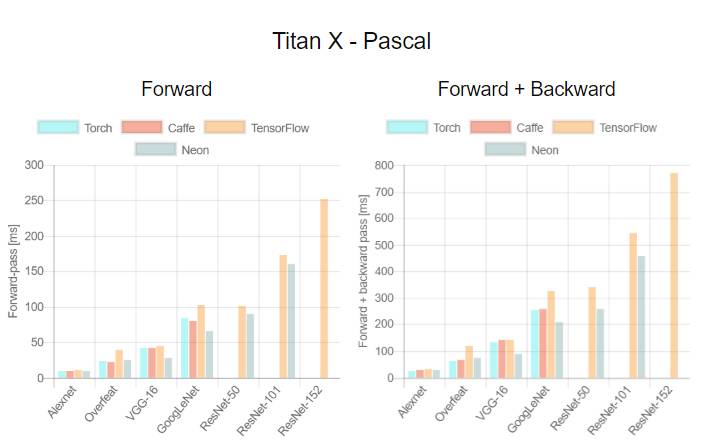
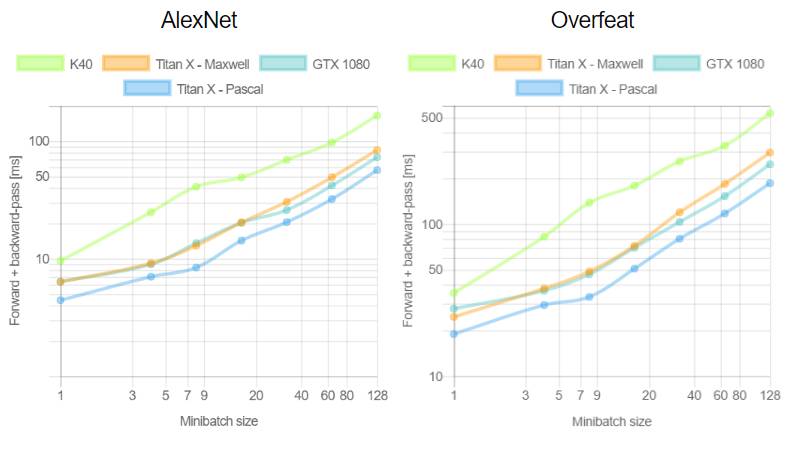
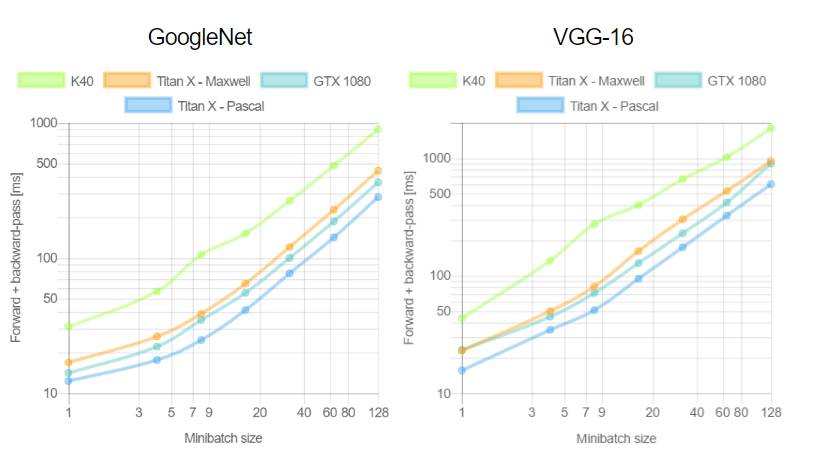
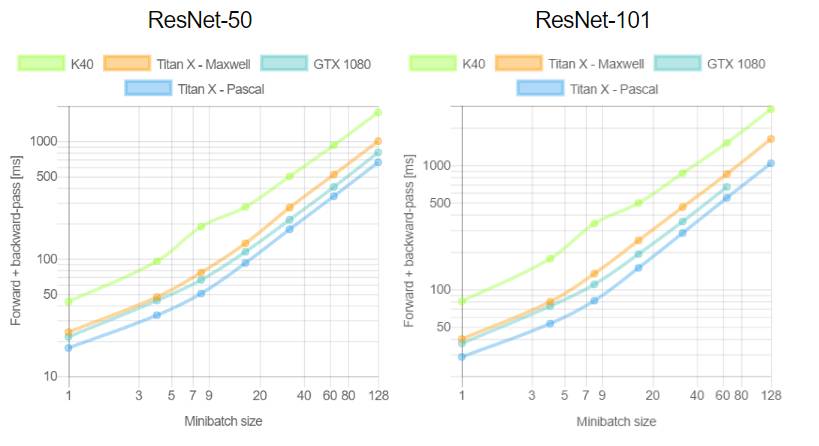
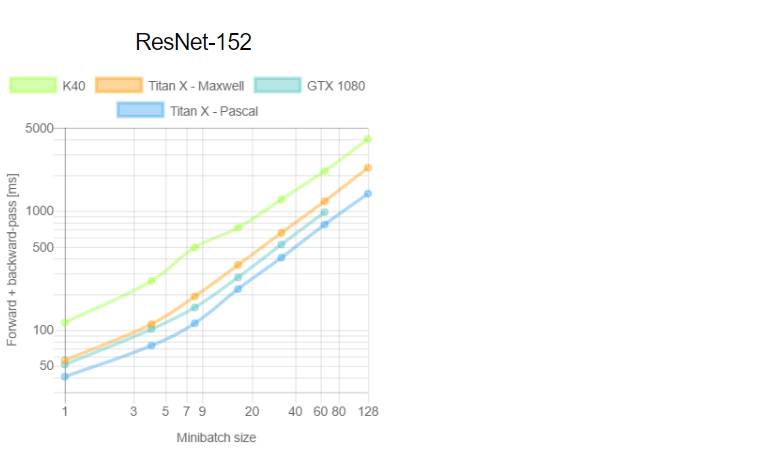
这是首次针对不同 GPU(Tesla K40,Titan-X Maxwell,GTX 1080 和 Titan-X Pascal)与不同网络(AlexNet,Overfeat,Oxford VGG,GoogLeNet,ResNet-50,ResNet-101 和 ResNet-52)在不同深度学习框架下(Torch,Caffe,TensorFlow 和 Neon)的评测。在评测中,除了 Neon,所有框架都使用了英伟达 cuDNN 5.1。我们在每个 minibatch 里使用了 64 个取样,每次进行超过 100 次推理和训练。图表中缺失的数据意味着该次测试遭遇内存不足。
用于 TensorFlow 的 Minibatch 效率
训练深度学习框架时知道每个 minibatch 中的样本数量将会加快训练。在第二个测评中,我们分析了 minibatch 尺寸与训练效率的对比。由于 TensorFlow 1.0.0 极少出现内存不足的情况,我们只使用它进行这项评测。这次实验中我们重新评估了 100 次运行中的平均正向通过时间和和正向+反向通过时间。
测评分析
关于第一个测评,我们注意到,Neon 几乎总是能为 Titans 和 GTX 1080 导出最好的结果,而对 K40 的优化最差。这是因为 Neon 针对 Maxwell 和 Pascal 架构做了优化。Tesla K40,作为一个 Kepler GPU,缺少这样低层级的优化。Torch 在所有架构中都可以输出好结果,除了被用在现代 GPU 和更深的模型时。这又一次成了 Neon 发挥作用的时候。最后,我们指出 TensorFlow 是唯一一个可以训练所有网络的框架,并且不会出现内存不足的情况,这是我们继续使用它作为第二个测评的框架的原因。
关于第二个测评,一般来说更大的 minibatch 可以减少每个样本的运行时间继而减少每个 epoch 的训练时间。正如我们在上图看到的,当使用 VGG 网络时,GTX 1080 需要 420.28 毫秒为一个 64 样本的 minibatch 运行正反向通过;相同的配置训练 128 个样本需要 899.86 毫秒,是前者的两倍还要再多出 60 毫秒。此外,我们注意到对于所有大小为 8 的 minibatch 中的网络,Tesla K40 有一个下凹曲率; Titan X Pascal 在使用相同 batch 大小的更浅架构上(例如 AlexNet 和 Overfeat)表现出上凹曲率。下凹曲率表明有效率在下降而上凹曲率则相反。更有趣的是 minibatch 大小的特殊取值也意味着更明显的效率。分析两个 GPU 将有助于解释这为什么会发生。
附录
以下是对测评中使用的 GPU 还有架构和框架版本的扼要介绍。
GPU









