自动化机器学习(AutoML)
如今已经成为一个相当有趣且重要的话题。本文将对AutoML做一个简要的解释,论证它的合理性和可用性,介绍几个关于AutoML的现代工具,并讨论AutoML的未来和方向。


什么是自动化机器学习?
自动化机器学习并不是自动化数据科学。虽然两者存在重叠,但是机器学习只是数据科学工具包中众多工具之一,它的使用实际上并没有考虑到所有数据科学任务。例如,如果预测是数据科学任务的一部分,那么机器学习将是一个有用的组件;但是,机器学习可能根本不适用于描述性分析任务。
即使对于预测性任务,数据科学也比实际的预测性建模包含更多的内容。数据科学家Sandro Saita在讨论AutoML和自动化数据科学之间的潜在混淆时,曾说过:
这种误解来自于整个数据科学过程(例如CRISP-DM)与数据准备(特征提取等)子任务以及建模(算法选择、超参数调整等)之间的混淆,我称之为机器学习…以及我称之为机器学习的建模(算法选择、超参数调整等)之间的混淆。
当你阅读有关自动化数据科学和数据科学竞赛工具的新闻时,没有行业经验的人可能会感到困惑,认为数据科学只是建模,可以完全自动化。
此外,数据科学家和自动化机器学习的领先拥护者Randy Olson指出,有效的机器学习设计要求我们:
· 不断地调整模型的超参数
· 不断地尝试多种模型
· 不断地为数据探索特征表示法
考虑到以上所有因素,如果我们把AutoML看作是算法选择、超参数调整、迭代建模和模型评估的任务,我们就可以定义AutoML是什么,但不会有完全一致的意见,不过,这足以让我们顺利地开始进行下一步工作了。
为什么需要它?
虽然我们已经完成了定义概念的工作,但AutoML有什么作用呢?让我们来看看为什么机器学习很困难。

人工智能研究员和斯坦福大学在读博士S.ZaydEnam在一篇题为“为什么机器学习很难”的博客文章中写道:
机器学习仍然比较难。毫无疑问,通过研究推进机器学习算法的科学是困难的。它需要创造性、实验性和韧性。即便为新的应用程序良好运行实现了现有的算法和模型,机器学习仍然是一个难题。
注意,虽然Enam主要指的是机器学习研究,但也涉及到用例中现有算法的实现。
Enam继续阐述机器学习的困难,并重点介绍算法的性质:
这个困难的一个方面涉及到建立一种直觉,能够正确选择优先使用哪种工具来解决问题。这需要了解可用的算法和模型,以及每个算法和模型的权衡和约束。
……
困难在于机器学习是一个基本上很难调试的问题。在两种情况下会进行机器调试:1)算法不起作用,2)算法工作得不好。……很少有一算法一次就起作用的,因此大多数时间都花在构建算法上。
然后,Enam从算法研究的角度对这个框架问题进行了详细的阐述。如果一个算法不起作用,或者做得不够好,并且选择和重新编译的过程是迭代的,这就可以使用自动化,因此可以使用自动化机器学习。
之前曾有人试图捕捉AutoML的本质,如下所示:
如果,正如Sebastian Raschka所描述的那样,计算机编程是关于自动化的,而机器学习是关于自动化的,那么自动化机器学习就是“自动化自动化自动化的自动化”。这里:编程通过管理死记硬背的任务来减轻我们的负担;机器学习允许计算机学习如何最好地执行任务。自动化机器学习允许计算机学习如何优化学习如何执行这些死记硬背的操作结果。
这是一个非常强大的想法;虽然我们以前需要担心参数和超参数的调整,但是自动化机器学习系统可以通过多种不同的可能方法来学习优化这些参数和超参数的最佳方法。
AutoML的基本原理源于这样一个想法:如果必须使用各种算法和许多不同的超参数配置来构建机器学习模型,那么这个模型构建可以自动化,模型性能和精度的比较也可以自动化。
很简单,对吧?
比较不同的自动化机器学习工具
既然我们了解了什么是AutoML,以及它的作用,我们如何实现呢?下面是一些当代Python AutoML工具的概述和比较,这些工具采用不同的方法,试图实现与机器学习过程自动化相同的目标。
Auto-sklearn
Auto sklearn是“一个自动化机器学习工具包和一个scikit-learn评估工具的替代品”,它也恰好是kdruggets最近的自动化数据科学和机器学习博客竞赛的赢家。
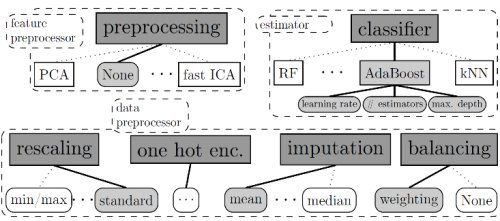
auto-sklearn使机器学习用户从算法选择和超参数调整中解放出来。它利用了贝叶斯优化、元学习和集成构造的最新优势。
正如上述,auto-sklearn通过贝叶斯优化来执行超参数优化,然后重复以下步骤:
· 建立概率模型,以捕捉超参数设置与其性能之间的关系。
· 使用该模型选择有用的超参数设置,然后通过权衡勘探(在模型不确定的部分空间中搜索)和开发(聚焦于预计性能良好的部分空间)来尝试下一步。
· 使用这些超参数设置运行机器学习算法。
对该过程的进一步解释如下:
这一过程可以概括为联合选择算法、预处理方法及其超参数:分类器/回归器和预处理方法的选择是顶级的、分类的超参数,并且根据它们的设置,所选方法的超参数变灵活。然后,可以使用处理这种高维条件空间的贝叶斯优化方法搜索组合空间;使用基于随机森林的SMAC,这已被证明对这种情况最有效。
就实用性而言,由于Auto-sklearn是scikit-learn估算器的替代品,因此需要使用scikit learn的功能性安装。Auto-sklearn还支持通过共享文件系统上的数据共享来并行执行,并且可以利用Scikit-Learn的模型持久性。根据作者的观点,有效地使用Auto-sklearn替换估计量需要以下4行代码,以便获得机器学习pipeline:
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
y_hat = cls.predict(X_test)
使用mnist数据集的auto sklearn的更稳定示例如下:
import autosklearn.classificationimport sklearn.cross_validationimport sklearn.datasetsimport sklearn.metrics
digits = sklearn.datasets.load_digits()
X = digits.data
y = digits.target
X_train, X_test, y_train, y_test = sklearn.cross_validation.train_test_split(X, y, random_state=1)
automl = autosklearn.classification.AutoSklearnClassifier()
automl.fit(X_train, y_train)
y_hat = automl.predict(X_test)
print("Accuracy score", sklearn.metrics.accuracy_score(y_test, y_hat))
另外值得注意的是,Auto Sklearn赢得了Chalearn AutoML挑战赛的Auto和Tweakaton赛道。Auto-sklearn可在其官方Github存储库
(https://github.com/automl/auto-sklearn)
中获得。
TPOT
TPOT被“推销”为“你的数据科学助手”(请注意,它不是“你的数据科学替代品”)。它是一个python工具,“使用基因编程自动创建和优化机器学习pipeline”。TPOT和auto-sklearn一样,与scikit-learn一起工作,将自己描述为scikit-learn包装器。
正如本文前面所提到的,2个突出显示的项目使用不同的方法来实现类似的目标。虽然这两个项目都是开源的,用python编写,旨在通过AutoML简化机器学习过程,但与使用贝叶斯优化的auto-sklearn相比,TPOT的方法是基于遗传编程的。
然而,虽然方法不同,但结果是相同的:自动超参数选择,用各种算法建模,以及探索许多特征表示,都会实现迭代模型构建和模型评估。
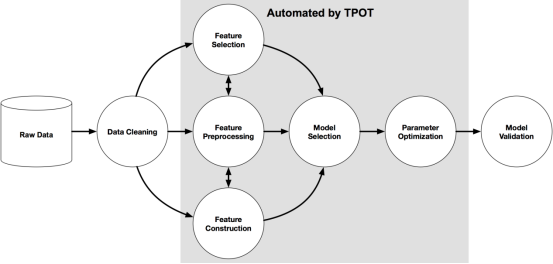
TPOT的一个好处是,它以scikit学习pipeline的形式,为性能最佳的模型生成可运行的独立python代码。然后,可以修改或检查该代码,以获得更多的洞察力,从而有效地充当起点,而不是仅仅作为最终产品。
TPOT在MNIST数据上运行的示例如下:
from tpot import TPOTClassifierfrom sklearn.datasets import load_digitsfrom sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75, test_size=0.25)
tpot = TPOTClassifier(generations=5, population_size=20, verbosity=2)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot-mnist-pipeline.py')
本次运行的结果是一条达到98%测试精度的pipeline,同时将所述pipeline的python代码导出到tpot-mnist-pipeline.py文件,如下所示:
import numpy as np
from sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.pipeline import make_pipeline
# NOTE: Make sure that the class is labeled 'class' in the data file
tpot_data = np.recfromcsv('PATH/TO/DATA/FILE', delimiter='COLUMN_SEPARATOR')
features = tpot_data.view((np.float64, len(tpot_data.dtype.names)))
features = np.delete(features, tpot_data.dtype.names.index('class'), axis=1)
training_features, testing_features, training_classes, testing_classes = train_test_split(features, tpot_data['class'], random_state=42)
exported_pipeline = make_pipeline(
KNeighborsClassifier(n_neighbors=3, weights="uniform"))
exported_pipeline.fit(training_features, training_classes)
results = exported_pipeline.predict(testing_features)
TPOT可以通过其官方Github报告获得。










