近年来,一个名叫Fintech的名词悄然兴起。互联网科技与传统金融行业的结合越来越深入,作为投行交易系统定海神针的市场数据平台,有着怎样的技术背景?其架构设计又是怎样的?
投行的Global Markets或Sales&Trading部门主要服务于大型机构客户,包括金融机构,企业,政府以及各种投资基金(私募基金,对冲基金等),从事包括做市商(Market Maker), 外汇(FX), 固定收益类交易(Currencies, Interest Rates and Credit), 股票交易(Equity Securities),衍生品交易(Derivatives)及结构化产品(Structured Products)等以满足机构客户及投行自营交易等各种金融需求。
08年金融危机或者Dodd-Frank法案以前,投行内部依靠良好的融资渠道和低成本优势,林立着各种高杠杆自营业务实体(类似对冲基金)从事量化交易,对冲,跨市套利,对赌等交易,如著名的高盛Global Alpha,大摩的PDT(Proess Driven Trading),这种高额暴利交易不但成就了投行本身,也成就了很多从Trading Floor直升的大佬,如花旗与大摩的前任CEO。
08年之后,美国政府明文规定投行停止自营交易,各大量化部门饱受打击,要么艰难的维持极小自营规模,要么销声匿迹。与此同时,也簇生,发展,兴盛了投行的专属做市商(Designated Market Maker)自动化交易,尤其是指数,期权,外汇,国债等,包括B2B(Broker-to-Broker)市场和B2C(Broker-to-Client)市场。
我们要介绍的系统平台,则跨越了从支持自营业务交易到支持做市商自动化交易。
华尔街大行之所以称之为大行,除了其金融业务实力之外,其技术功力也不可小嘘,实力不亚于硅谷互联网公司。纽交所,纳斯达克市场70%的交易都是来自于机器自动化交易,其中的高频交易系统更是大行必备之精良高端武器。如果你记得某年某月某日某行某Trader的弹指神功(Fat Finger),使得道琼斯指数分分钟闪崩1000余点(近10%左右),这可不是其头寸足够大,而是明显是机器系统算法的连锁反应导致的雪崩效果啊。不夸张的讲,整个华尔街都运行在IT系统之上,如果IT交易系统出个bug打个喷嚏,全球市场都要震荡一下。
各大行中,IT系统则又以大摩,前雷曼兄弟的基础设施著称,高盛则自成一派,从开发语言到数据库都是自创,架构方面则从一开始就大统一,所有交易数据都在其核心数据库中,所有后续的风控,清算,对冲,财务,监管,报表等都无后顾之忧。其它各行则少则数十,多则数百系统,各种交易数据传来传去,复杂异常。而成就大行这些顶级设计的则是全球顶尖名校的精英人才,不乏来自各数学,物理,计算机的P.h.D,更有甚者直接凭请业界大师,如大摩把Java之父招至靡下从而发挥其磁吸作用。
本文以某大行的Global Market Data(市场数据平台)来探讨其内部交易系统的基石,市场数据平台。之所以称之为定海神针,是因为所有的交易少不了市场数据,报价等支持,如外汇(FX),Rates, Credit, 当然此系统主要支持固定收益以及外汇交易(股票市场数据在各行中一般有独立系统支持)。固定收益交易及外汇占了全球交易量的2/3,其交易量之大可见一斑。每日全球产生的市场数据超过千万,包括实时Ticker(报价)数据等。

交易楼层(Trading Floor)
作为投行重要的底层基础支柱之一,衡量其重要可用及成功因素包括如下:
-
支持高并发,高吞吐,快速访问,查询市场数据,并且数据可以持久化保存
-
支持全球多个数据中心,临近访问,数据中心之间数据一致性
-
支持多个数据中心之间高可用HA 7*24, 自动Failover
-
支持低延迟实时市场数据报价访问
-
支持历史数据访问查询
-
支持客户端多种协议访问,如RPC, REST, Web, .Net, Excel等
-
支持实时系统状况监控,自动运维/部署平台
-
主要数据来源更新来自路透社(Thomson Reuters),彭博(Bloomberg),各大期货交易所如CBOT(芝加哥期货交易所)等。
-
每日新增市场数据大概20g;
-
每日新增Snapshot/EOD大概20-40g;
-
系统需要在缓存中维护1-2个月的EOD Sanpshot,大概100-150g左右;
-
每日全球市场报价数据流量为20-100g,当然大多数是Ticker, 其中高频段为100000次/分更新,或者高峰达到1500-10000次/秒更新(Ticker数据多为机器策略交易提供服务,无须持久化)总体来看,缓存需要支撑大概200g左右,考虑到数据安全性及冗余,共需要500g左右。
听起来每个需求都合情合理,然而如果你是架构师,请问如何下手?笔者也并非此系统原始架构师,而平台也早已经过多年自然演进,我们今天尝试庖丁解牛,倒序分析,一步步逼近事实真相。另因涉及敏感信息,一些名称/架构等进行脱敏,但保留整体设计思想。
根据上述之需求,其实我们大体可以想到方向应该是分布式 + 缓存 + 数据库/文件+数据仓库/大数据分析等。
目前业界比较成熟,流行的大型分布式缓存有Oracle Coherence, GemFire, Redis, Memcached以及Apache Ignite等,我们用表格罗列对比分析其主要特性。
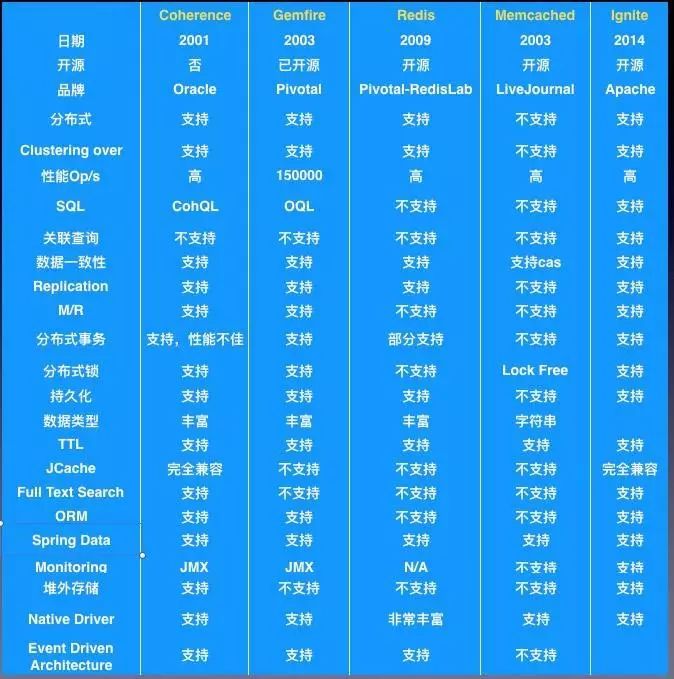
分布式缓存比较
其实,按照上述业务及数据需求分析,首先排除Ignite, 为啥?2014年才诞生,来不及啊。抛开时间不谈,Ignite诞生于大数据时代,天生与Hadoop, Spark有着良好的集成,冉冉新星。
对于Redis这把“瑞士军刀”,我们想要的需求大多可以满足,可惜在3.0前无法很好支持服务端集群以及全球化多站点部署,Memcached之锋利则更适用于互联网缓存;
剩下的Coherence与Gemfire,集王者之大成,如何选?其实,Gemfire已于早些年大举进军华尔街,全心专注投行需求,如全球化多站点部署等,同时又与时俱进,从并行计算到MapReduce无所不能,2008金融危机后,更是激流勇进,垄断大行缓存平台,据统计全球2/3以上的Gemfire服务运行于华尔街。
Gemfire水到渠成,况且在大公司有时候很多产品策略早已定好(基于产品的成熟性,可用性以及可维护性)。好的产品是成功基石,至于后来被证明在“全球最大在线交易系统12306”中卓越表现也再次被证明,然而一个好产品也并非万能可以适应所有场景。
高并发,快速访问是采用缓存的主要目的之一。而要做到这些必须对我们应用的需求了解,对我们的数据进行妥善管理,正所谓知己知彼才能百战不殆。
数据管理的首要问题包括如了解应用需要管理多少数据, 如100g;数据类型及大小,如文本,500k文件大小;数据之间有依赖否?数据的生命周期,如是否需要持久化等。另一方面,我们也需要了解这些数据会如何被使用,如多少并发客户,用户访问数据的模式,如持续查询还是事件订阅等。
我们来看一张图表来梳理一下:
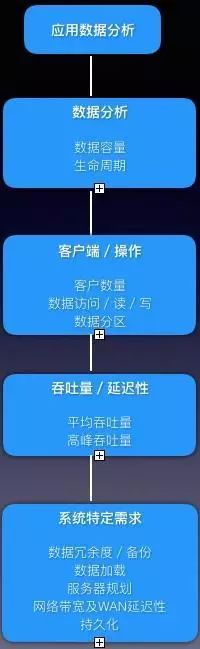
缓存数据分析
数据容量
对于我们市场数据缓存的需要,上文分析大概需要200g左右,考虑到数据安全性及冗余,共需要500g左右。
至于磁盘与数据库持久化的容量,磁盘应该不是大问题,数据库则每个数据中心实时数据库需要500g到1T以上,历史数据库则5T - 10T左右,实时数据库需要定时定期归档。
服务器规划
对于64位的平台(Linux),考虑到目前操作系统实际能支持的内存为大概192G左右(理论上限为16.8TB),以及JVM GC(1.6/1.7)本身推荐管理内存大小,我们设定一个Data/Snapshot节点内存为10-16g,则单一数据中心一共需要30-50个nodes,3台物理服务器作为数据服务器;
值得注意的是,建议上述服务器作为数据专用服务器,数据与其它应用分离,便于扩展同时也更加避免相互影响,尤其分布式中各服务需要相互通信。
数据冗余
数据冗余方面,如果对数据有严格容错要求,建议采用3个备份(基数),3是个神奇的数字,即做到了数据的充分备份可靠,又兼顾了资源。当数据出问题时候,一个copy可以用来恢复数据,另一个可以继续实时服务。鉴于我们市场数据主要以报价以及EOD为主,我们采用1个数据冗余即可(省钱),当然即便如此,后来也遇到了非常艰难的性能及稳定性问题,我们先埋个伏笔。
数据分区
有了数据的集群,存储无忧。然而想要做到支持高并发,低延迟访问,数据布局的内功不可少。分布式缓存中较常用的数据分区有Partioned与Replicated。Replicated分区适用于数据量相对较小但高频读的数据,其数据会自动镜像到所有集群member;Partioned则适用于通常大数据量,写相对要求高,内部则划分成类似ConcurrentHashMap的Bucket或者Redis中的Hash Slot来存储。
按照此思路,我们将一些常用的配置信息作为Replicated来存储,而真正市场数据则用Partioned分布到各个节点存放。
磁盘持久化
数据持久化,我们需要支持缓存的Overflow to Disk以及数据库的持久化。磁盘持久化大多数分布式缓存已经支持做到LRU算法,并且支持磁盘get/put等操作,需要配置一些Eviction的触发阀值,阀值触发后根据LRU算法把最近最少用数据移除内存缓存放置到磁盘。
数据库持久化
至于缓存数据库的持久化,经典的算法大概分为Write-Through与Write-Behind。
Write-Through主要是指当更新完缓存数据后,系统会同步更新数据库,直至全部完成结束。
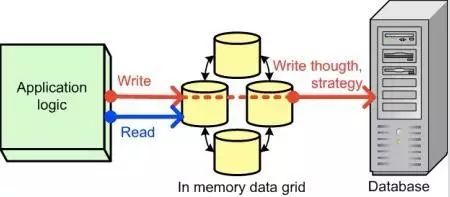
Write-Through Cache
可以看出Write-Through可以精确做到数据的一致性,当然其带来的弊端是会影响性能。
Write-Behind 则指当更新完缓存数据后,系统把更新写入消息中间件或者队列,无需等待最终更新至数据库即返回,随后由消息中间件延迟更新至数据库。
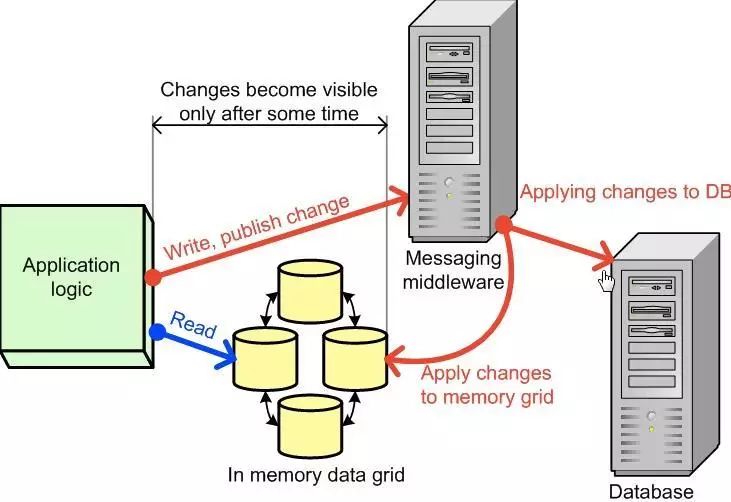
Write-Behind Cache
Write-Behind所采用的数据策略为最终一致性(Eventual Consistency), 在带来性能提升的同时,当然需要承担一定数据丢失以及延迟的成本。
多数分布式缓存系统也同时提供了缓存数据的监听器(Listener)便于定制化实现数据更新通知,以及其它如Write-Behind更新策略。下图为Gemfire/Geode缓存监听器,提供了before/after事件。通常可以使用Cache Writer来实现Write-Through策略,使用Cache Listeners来实现Write-Behind策略。
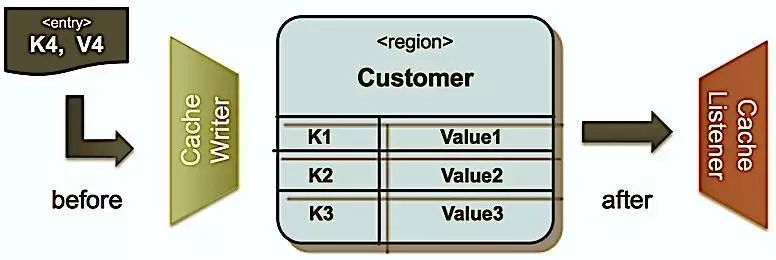
Cache Listener
考虑到市场数据的敏感及时效性,以及持久化主要以报表,分析,归档为主,所以我们的采用EMS消息中间件来实现Write-Behind缓存更新策略。
支持全球多个数据中心,临近访问,数据中心之间数据一致性
这个需求是大行的入门级,分行分布全球,通常需要搭建纽约,伦敦,东京,香港/新加坡等4地作为数据中心,做到4地皆可访问当地应用,数据中心之间数据则需要相互备份,如果某个数据中心出问题,自动切换至其他几个数据中心,做到全球24小时不间断交易,事实上正如全球市场一样,澳洲,东京最早开市,随后香港/新加坡,当亚洲闭市后伦敦开市,随后纽约开始直至第二天。
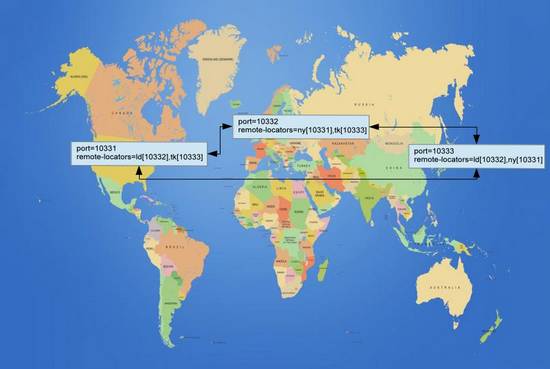
全球多数据中心(WAN)
上图为全球多数据中心的事例,我们系统需要做到支持4个数据中心(伦敦,纽约,东京,香港)。
各种分布式缓存产品大都支持全球多数据中心(WAN)结构,数据中心多个Site之间的通信协作配置,Gemfire/Geode的多数据中心即本配置如下图。

WAN Site XML配置信息
其中每个数据中心自成分布式集群,数据中心之间则通过上述基本配置来连接共享。
各个数据中心之间则通过Locator,Sender, Receiver来实现TCP/IP发现,异步通信,Replication等,每个数据中心或者集群既有Sender作为发送端也有Receiver作为接受端。
Sender通过Locator定位到远端集群的Locator,远端Receiver则接受请求并发送远端host/port信息。也可配置多个并行Sender(Parallel Gateway Sender)。
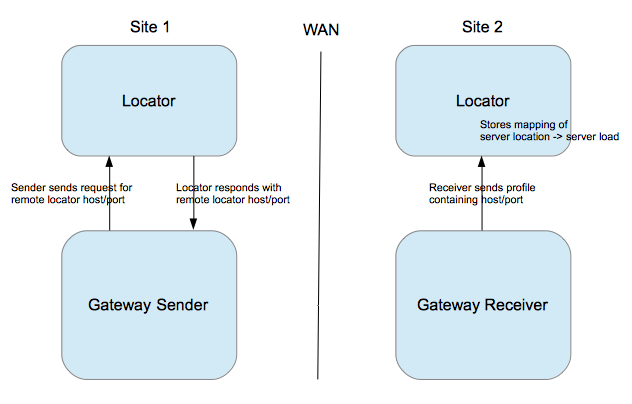
WAN Sender / Receiver
而且内部则使用Queue作为缓存异步通信渠道,通过Ack机制,两个数据中心保证了数据的完整性,同时Queue则化同步为异步,提升效率同时接耦合,一个数据中心出问题不会影响其它数据中心。多个数据中心可以通过环路或者全网络拓扑来连接。
通常垮多个数据中心,比较棘手的问题主要有如何在并发下保证数据一致性以及本身由于垮WAN导致的数据延迟性。
多数据中心采用最终一致性策略来保证多数据中心数据的统一,默认情况,在多个数据中心并发更新某一Entry的情况下,系统会根据事件的时间戳选择较新的更新作为最终数据;极端情况下,如果完全相同时间戳,则默认会各自选择远端的更新(有可能导致数据不一致)。系统也可以自己定义策略来选择更新。
鉴于市场数据的精准性要求,我们从业务上规定某一种数据在某一个数据中心为主,即定制冲突优先级策略来解决。
跨全球数据中心的数据传输,Replication往往受限于多种因素,如网络,流量以及本身传输大小等,从毫秒到数秒不等,数据延迟性面临很大挑战和不可控。
然而令人略微欣慰的是,业务上面每个数据中心大多只需要自治,如东京开盘时间主要访问东京数据中心获取市场数据为主;每个数据中心只要在每日闭市后,把当日的EOD数据同步Replicated到全球其它数据中心即可,延迟性方面还好。
然而考虑到全球外汇市场主要以伦敦为主(外汇中心),东京,新加坡很多FX系统需要实时市场报价,目前方案有两种:
其一,对于延迟性要求略微低一些的系统,直接连接伦敦数据中心。
其二,对于实时报价等低延迟数据则通过TIBCO RV(Rendezvous) Routing通过UDP协议,牺牲可靠性从而达到高实时性需求,直接从伦敦路由东京,东京到香港之类的。TIBCO公司的两大旗舰产品EMS和RV专攻消息中间件,RV则采用UDP协议适合小消息,高实时性场景。使用TIBCO RV Reliable模式已经可以做到消息发布150万/秒,50万/秒接受的性能。
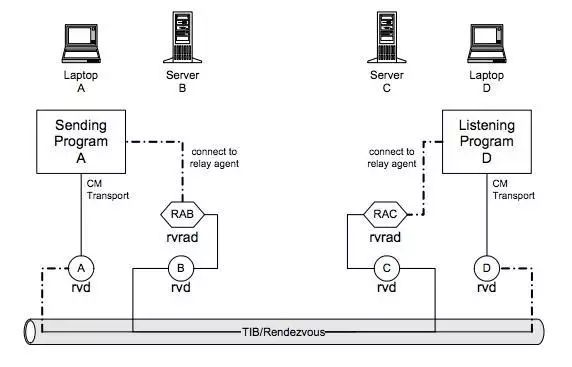
TIBCO RVRD(Rendezvous Routing Daemon)
按照如上两种解决方案,目前暂时可以应对业务需求。










