
声明:文中所有文字、图片以及相关外链中直接或间接、明示或暗示涉及性别、颜值分数等信息全部由相关人脸检测接口给出。无任何客观性,仅供参考。
1 数据源
知乎 话题『美女』下所有问题中回答所出现的图片
2 抓取工具
Python 3,并使用第三方库 Requests、lxml、AipFace,代码共 100 + 行
3 必要环境
Mac / Linux / Windows (Linux 没测过,理论上可以。
Windows 之前较多反应出现异常,后查是 windows 对本地文件名中的字符做了限制,已使用正则过滤
),无需登录知乎(即无需提供知乎帐号密码),人脸检测服务需要一个百度云帐号(即百度网盘 / 贴吧帐号)
4 人脸检测库
AipFace,由百度云 AI 开放平台提供,是一个可以进行人脸检测的 Python SDK。可以直接通过 HTTP 访问,免费使用
5 检测过滤条件
-
过滤所有未出现人脸图片(比如风景图、未露脸身材照等)
-
过滤所有非女性(在抓取中,发现知乎男性图片基本是明星,故不考虑;存在 AipFace 性别识别不准的情况)
-
过滤所有非真实人物,比如动漫人物 (AipFace Human 置信度小于 0.6)
-
过滤所有颜值评分较低图片(AipFace beauty 属性小于 45,为了节省存储空间;再次声明,AipFace 评分无任何客观性)
6 实现逻辑
-
通过 Requests 发起 HTTP 请求,获取『美女』下的部分讨论列表
-
通过 lxml 解析抓取到的每个讨论中 HTML,获取其中所有的 img 标签相应的 src 属性
-
通过 Requests 发起 HTTP 请求,下载 src 属性指向图片(不考虑动图)
-
通过 AipFace 请求对图片进行人脸检测
-
判断是否检测到人脸,并使用 『4 检测过滤条件』过滤
-
将过滤后的图片持久化到本地文件系统,文件名为 颜值 + 作者 + 问题名 + 序号
-
返回第一步,继续
7 抓取结果
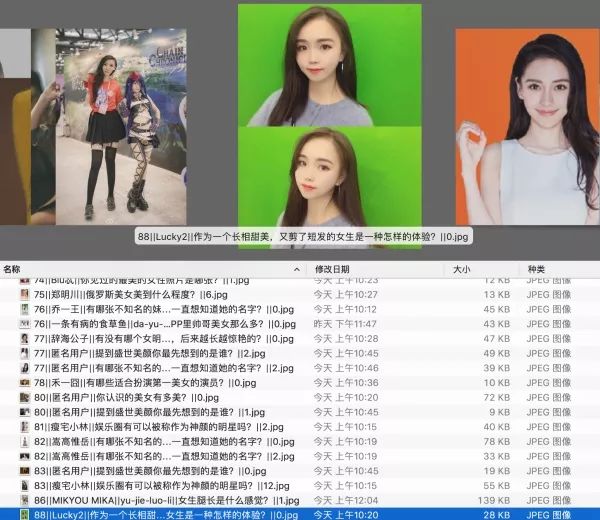
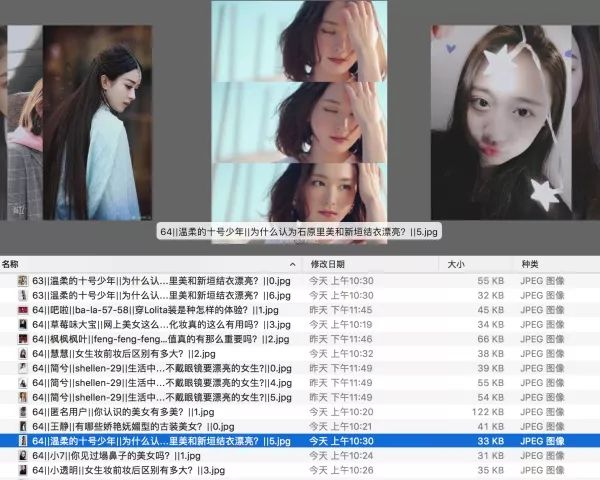
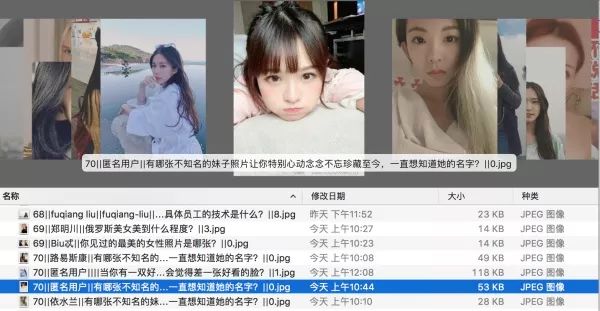
直接存放在文件夹中(angelababy 实力出境)。另外说句,目前抓下来的图片,除 baby 外,88 分是最高分。个人对其中的排序表示反对,老婆竟然不是最高分

8 代码
本文代码长达百行,鉴于微信公众号上代码阅读体验实在不佳,小编已将源代码进行保存,请前往微信公众号后台回复关键字
「知乎爬虫」
获取。

微信后台传送门
9 运行准备
要求登录,百度帐号可以直接使用(贴吧/网盘通用),没有只能注册
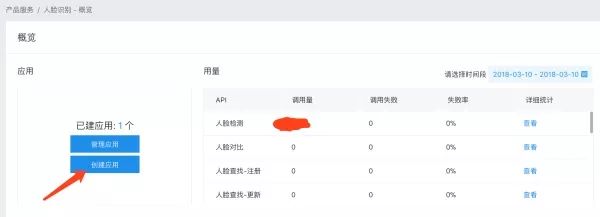
点击创建应用
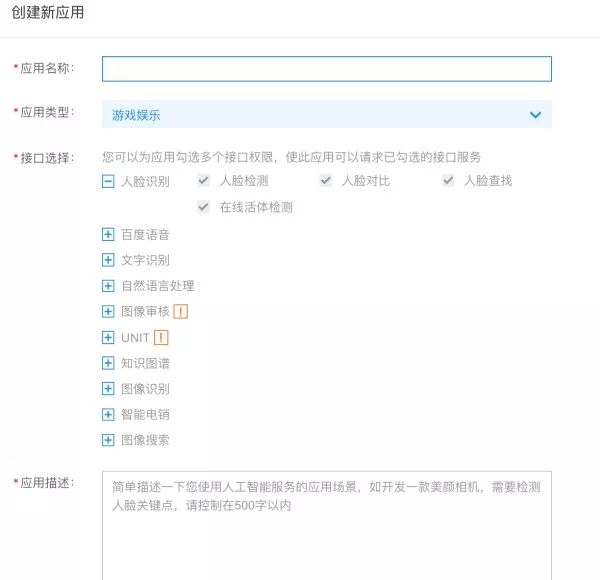
随便填下
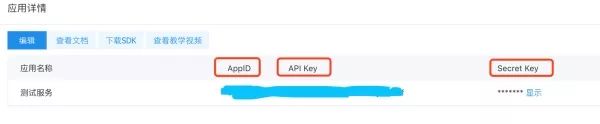
将 AppID ApiKek SecretKey 填写到 代码 中
{
"error": {
"message": "ZERR_NO_AUTH_TOKEN",
"code": 100,
"name": "AuthenticationInvalidRequest"
}
}
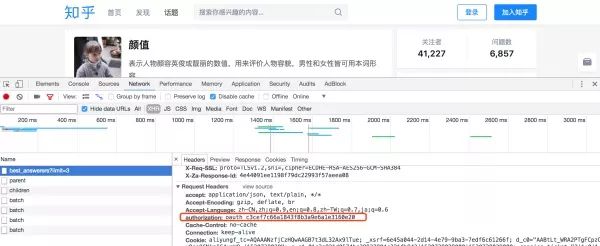
Chrome 浏览器;找一个知乎链接点进去,打开开发者工具,查看 HTTP 请求 header;无需登录
10 结语
-
因是人脸检测,所以可能有些福利会被筛掉。百度图像识别 API 还有一个叫做色情识别。这个 API 可以识别不可描述以及性感指数程度,可以用这个 API 来找福利(逃
-
如果实在不想申请百度云服务,可以直接把人脸检测部分注释掉,当做单纯的爬虫使用
-
人脸检测部分可以替换成其他厂商服务或者本地模型,这里用百度云是因为它不要钱
-
抓了几千张照片,效果还是挺不错的。有兴趣可以把代码贴下来跑跑试试
-
这边文章只是基础爬虫 + 数据过滤来获取较高质量数据的示例,希望有兴趣者可以 run 下,代码里有很多地方可以很容易的修改,从最简单的数据源话题变更、抓取数据字段增加和删除到图片过滤条件修改都很容易。如果再稍微花费时间,变更为抓取某人动态(比如轮子哥,数据质量很高)、探索 HTTP 请求中哪些 header 和 query 是必要的,文中代码都只需要非常局部性的修改。至于人脸探测,或者其他机器学习接口,可以提供非常多的功能用于数据过滤,但哪些过滤是具备高可靠性,可信赖的且具备可用性,这个大概是经验和反复试验,这就是额外的话题了;顺便希望大家有良好的编码习惯
-
最后再次声明,颜值得分以及性别过滤存在 bad case,请勿认真对待
作者:邓卓
来源:
https://zhuanlan.zhihu.com/p/34425618
《Python人工智能和全栈开发》2018年07月23日即将在北京开课,




