
点击图片,立即加入开源中国码云
摘要: 上周轰动一时的Gitlab事件终于尘埃落定了,不可否认的是这次事故Gitlab官方公关的的很出色,及时公布事件细节并寻求帮助,这让本是一个失误引发的事故,演变为一个真诚面对问题并反思的正面教材。对此,网络上一片好评。

截止北京时间2017/02/02 02:14,GitLab.com已恢复正常。期间丢失了 6 小时的数据库数据(问题,合并请求,用户,评论,片段等)。Git / wiki 存储库和自托管安装不受影响。根据GitLab从日志里得出的结论,有707位用户丢失数据,5,037项目丢失,受事故影响的用户基数不到1%。
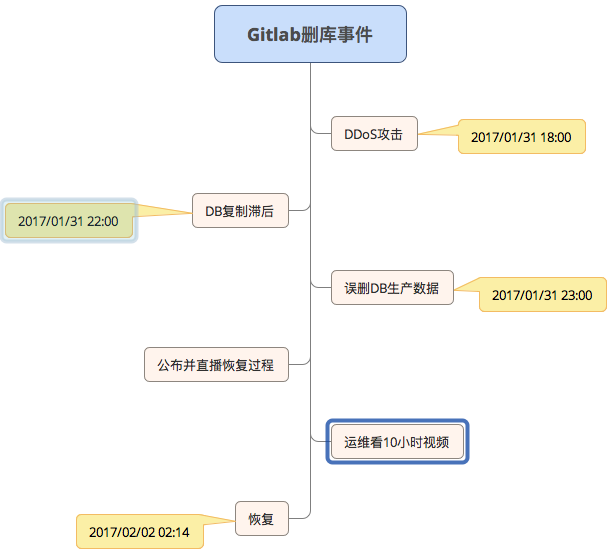
起因是在 2017/01/31 18:00左右,Gitlab检测到垃圾邮件发送者通过创建片段来攻击数据库,使其不稳定,于是运维block攻击者的IP,并移除用户发送垃圾邮件。之后运维A发现db2.staging复制滞后生产库4GB的数据(据后期2nd Quadrant的CTO – Simon Riggs 建议,PostgreSQL有4GB的同步滞后是正常的),A开始尝试修复db2,但复制失败,A在尝试了多种方案之后依然如此。
在2017年1月31日23:00 左右A决定删除该db2数据库目录,令其重新复制。由于夜间开车时间很长,A错误的将db1.cluster.gitlab.com(生产库)的数据库删除,而不是db2的。虽然在一两秒之后意识到这个问题,终止了删除操作,但为时已晚。大约 300 GB 左右的数据只剩下约4.5 GB。
随后虽然有号称有五重备份机制(常规备份(24小时做一次)、自动同步、LVM快照(24小时做一次)、Azure备份(只对 NFS 启用,对数据库无效)、S3备份),没有一个可靠地运行或设置,最终只能基于LVM的备份(最近6小时以前),还原了6 小时前的备份。恢复期间Gitlab直播了这次恢复过程。
相关链接:
本次事件让我们大感震撼的是,Gitlab居然主动的公告了事件的细节,不但提交了详尽的事故报告到googleDoc上,还在网络上也积极的寻求帮助。这份真诚实在是令人敬佩。如果是一般的技术团队都是在向外界隐藏问题,然后自己闷头解决,最终时间耽误了,用户还不认可你,而你自己也有苦说不出。反而是Gitlab主动公布,不但获得了各方面的技术组织的鼎力帮助,还收获了用户的理解和支持,同时还让网络上也少了一份猜测和谣言。
除了积极的公开事件详细,GitLab的故障回顾中也说明了要对本次事故进行Ask 5 Whys。随后在直播的过程中,官方也主动说明了不会辞退运维A,而是会罚他看一个名为 "10 hours of nyancat" 的视频(http://www.nyan.cat/哈哈,很难看下去啊)。这个表明整个团队对本次事故的处理态度是,齐心合力解决问题,然后检讨流程,不归责于个人。这份处事态度也值得人钦佩,出现问题,首先不是追究责任,而是解决问题,然后发现后面的深层次问题,从而有效的避免下次再犯同样错误。
事故发生后,有人建议不要用rm命令,采用mv命令,其实这个只能解决暂时问题,你们保证用其他命令就不会出问题么。另外有人建议建立一个checkList流程,每次执行的时候check一遍流程,有文档做指示不会犯一些低级错误,如若每个命令都去check一下,工作是不会更复杂了。
另外还有一些建议双人操作,增加权限系统等等,我觉得对于一个规范流程来说,一些必要的提示和规范可以增加,但是运维要自动化,以机器来代替人工,而不是开倒车去采用更多的人工来避免错误。
本次的事故在恢复的时候,发现有5个备份系统基本都无用,最终导致了6个小时数据的丢失。基于备份系统的缺陷,有运维同学建议如下:
1、审核所有数据的备份方案,备份频率如何,备份数据放在哪里,保留多久。
2、对于云服务自带的镜像备份等服务,确认是否正确的打开和设置
3、对于自行搭建的备份方案,确认
4、定期做灾备演习,检验是否可以正确从备份中恢复,以及此过程需要多少时间和资源。
从备份流程和规范来说,这些建议很中肯。从另外一个角度来说,即便是你的备份系统已经做到了这些,而且操作人员零失误,但是丢失数据的问题也会发生,为何呐。
以下是采自左耳朵耗子《从Gitlab误删除数据库想到的》的文字。
备份通常来说都是周期性的,所以,如果你的数据丢失了,从你最近的备份恢复数据里,从备份时间到故障时间的数据都丢失了。
备份的数据会有版本不兼容的问题。比如,在你上次备份数据到故障期间,你对数据的scheme做了一次改动,或是你对数据做了一些调整,那么,你备份的数据就会和你线上的程序出现不兼容的情况。
有一些公司或是银行有灾备的数据中心,但是灾备的数据中心没有一天live过。等真正灾难来临需要live的时候,你就会发现,各种问题让你live不起来。你可以读一读几年前的这篇报道好好感受一下《以史为鉴,宁夏银行7月系统瘫痪最新解析》。
所以,在灾难来临的时候,你会发现你所设计精良的“备份系统”或是“灾备系统”就算是平时可以工作,但也会导致数据丢失,而且可能长期不用的备份系统很难恢复(比如应用、工具、数据的版本不兼容等问题)。
所以说,如果你要让你的备份系统随时都可以用,那么你就要让它随时都Live着,而随时都Live着的多结点系统,基本上就是一个分布式的高可用的系统。因为,数据丢失的原因有很多种,比如掉电、磁盘损坏、中病毒等等,而那些流程、规则、人肉检查、权限系统、checklist等等都只是让人不要误操作,都不管用,这个时候,你不得不用更好的技术去设计出一个高可用的系统!别无它法。
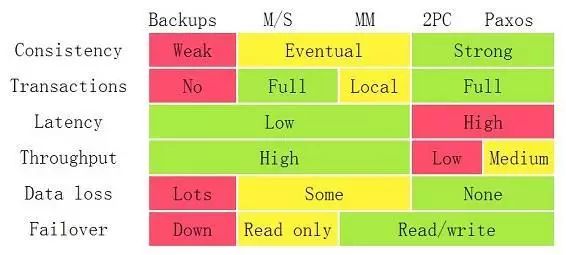
以上是每种架构的优缺点,我们可以看到Backups、Master/Slave、Master/Master架构下,Data都是会出现loss的情况的,而2PC和Paxos是不会的。
夜黑风高,夜间长时间开车,必然会有车祸现场的时候。这次事故的运维A,工作到深夜,想必也是和疲劳驾驶有一定的关系。
我们不评论8小时工作制度是否合理,但对于脑力劳动者,违背用脑规律甚至使之处于过载疲劳状态,都会显著降低脑部的能量转换效率,还是科学用脑最为可靠,把时间用在效率最高的地方。对此希望决策者能够意识到这个问题,而不是一味加班赶进度。这种危害已经越来越得到更多从业人员的认同了。









