移动端的KL库主要服务于模型下发和移动端推理引擎的执行,由于移动端的计算能力相对较弱,模型文件不宜过大,需要进行一些裁剪和压缩。目前主流的ML库有
Tensorflow Lite
、
PyTorch Mobile
、
MediaPipe
、
Firebase ML Kit
等,本文就这些技术做一个简单的介绍,帮大家扩大技术视野。
TensorFlow Lite
https://www.tensorflow.org/lite/guide
TensorFlow Lite 是将 TensorFlow 用于移动设备和嵌入式设备的轻量级解决方案,可以在Android、iOS以及其他嵌入式系统上使用。 借由
TensorFlow Lite Converter
将模型转化的压缩后的格式
.tflite
。
TFLite Converter
提供 Python和 CLI 工具,推荐使用Python API。
# MediaPipe graph that performs face mesh with TensorFlow Lite on GPU.# GPU buffer. (GpuBuffer)
input_stream:"input_video"# Output image with rendered results. (GpuBuffer)
output_stream:"output_video"# Detected faces. (std::vector<Detection>)
output_stream:"face_detections"# Throttles the images flowing downstream for flow control. It passes through# the very first incoming image unaltered, and waits for downstream nodes# (calculators and subgraphs) in the graph to finish their tasks before it# passes through another image. All images that come in while waiting are# dropped, limiting the number of in-flight images in most part of the graph to# 1. This prevents the downstream nodes from queuing up incoming images and data# excessively, which leads to increased latency and memory usage, unwanted in# real-time mobile applications. It also eliminates unnecessarily computation,# e.g., the output produced by a node may get dropped downstream if the# subsequent nodes are still busy processing previous inputs.
node {
calculator:"FlowLimiterCalculator"
input_stream:"input_video"
input_stream:"FINISHED:output_video"
input_stream_info:{
tag_index:"FINISHED"
back_edge: true
}
output_stream:"throttled_input_video"}# Subgraph that detects faces.
node {
calculator:"FaceDetectionFrontGpu"
input_stream:"IMAGE:throttled_input_video"
output_stream:"DETECTIONS:face_detections"}# Converts the detections to drawing primitives for annotation overlay.
node {
calculator:"DetectionsToRenderDataCalculator"
input_stream:"DETECTIONS:face_detections"
output_stream:"RENDER_DATA:render_data"
node_options:{[type.googleapis.com/mediapipe.DetectionsToRenderDataCalculatorOptions]{
thickness:4.0
color { r:255 g:0 b:0}}}}# Draws annotations and overlays them on top of the input images.
node {
calculator:"AnnotationOverlayCalculator"
input_stream:"IMAGE_GPU:throttled_input_video"
input_stream:"render_data"
output_stream:"IMAGE_GPU:output_video"}
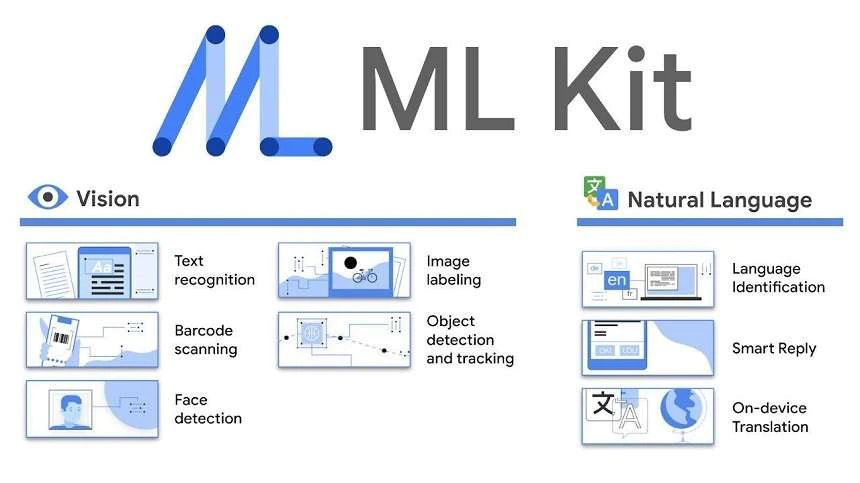
Firebase 由 Google 提供支持,基于 Google Mobile Service 的移动开放平台,为移动开发这提供了 APM、埋点等功能,ML Kit 是 Firebase 功能的面向移动端的机器学习库, 面向 Android/iOS 提供模型的分发、推理、学习、日志收集等能力。目前只支持 Tensorflow Lite 格式的模型。
例如使用 ML Kit 识别图片中的物体,代码如下:
privateclassObjectDetection:ImageAnalysis.Analyzer{
val options =FirebaseVisionObjectDetectorOptions.Builder().setDetectorMode(FirebaseVisionObjectDetectorOptions.STREAM_MODE).enableClassification().build()
val objectDetector =FirebaseVision.getInstance().getOnDeviceObjectDetector(options)private fun degreesToFirebaseRotation(degrees:Int):Int=when(degrees){0->FirebaseVisionImageMetadata.ROTATION_0
90->FirebaseVisionImageMetadata.ROTATION_90
180->FirebaseVisionImageMetadata.ROTATION_180
270->FirebaseVisionImageMetadata.ROTATION_270
else->throwException("Rotation must be 0, 90, 180, or 270.")}
override fun analyze(imageProxy:ImageProxy?, degrees:Int){
val mediaImage = imageProxy?.image
val imageRotation =degreesToFirebaseRotation(degrees)if(mediaImage !=null){
val image =FirebaseVisionImage.fromMediaImage(mediaImage, imageRotation)
objectDetector.processImage(image).addOnSuccessListener { detectedObjects ->for(obj in detectedObjects){
val id = obj.trackingId
val bounds = obj.boundingBox
val category = obj.classificationCategory
val confidence = obj.classificationConfidence
// Do Something}}.addOnFailureListener { e ->// Do Something}}}}