
我 相 信 这 么 优秀 的 你
已 经
置 顶
了 我
作者恒亮 选文|小象
来源雷锋网「leiphone-sz」 已获作者授权,拒绝二次转载
随着深度学习技术在机器翻译、策略游戏和
自动驾驶
等领域的广泛应用和流行,阻碍该技术进一步推广的一个普遍性难题也日渐凸显:训练模型所必须的海量数据难以获取。
以下是一些当前比较流行的机器学习模型和其所需的数据量,可以看到,随着模型复杂度的提高,其参数个数和所需的数据量也是惊人的。

基于这一现状,本文将从深度学习的层状结构入手,介绍模型训练所需的数据量和模型规模的关系,然后通过一个具体实例介绍迁移学习在减少数据量方面起到的重要作用,最后推荐一个可以简化迁移学习实现步骤的云工具:NanoNets。
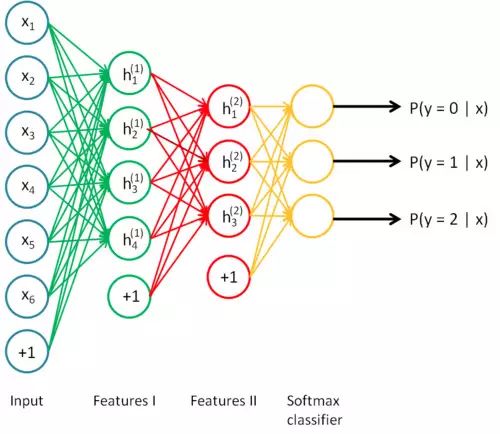
层状结构的深度学习模型
深度学习是一个大型的神经网络,同时也可以被视为一个流程图,数据从其中的一端输入,训练结果从另一端输出。正因为是层状的结构,所以你也可以打破神经网络,将其按层次分开,并以任意一个层次的输出作为其他系统的输入重新展开训练。
数据量、模型规模和问题复杂度
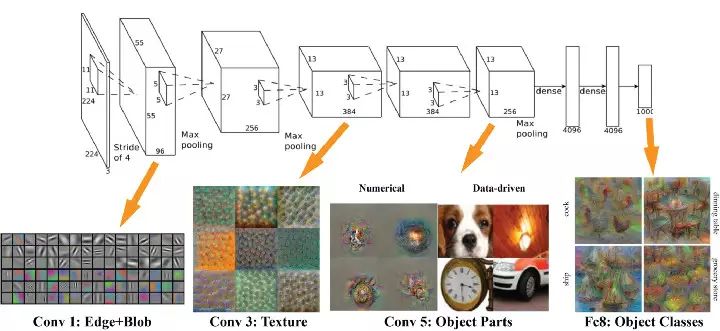
模型需要的训练数据量和模型规模之间存在一个有趣的线性正相关关系。其中的一个基本原理是,模型的规模应该足够大,这样才能充分捕捉数据间不同部分的联系(例如图像中的纹理和形状,文本中的语法和语音中的音素)和待解决问题的细节信息(例如分类的数量)。模型前端的层次通常用来捕获输入数据的高级联系(例如图像边缘和主体等)。模型后端的层次通常用来捕获有助于做出最终决定的信息(通常是用来区分目标输出的细节信息)。因此,待解决的问题的复杂度越高(如图像分类等),则参数的个数和所需的训练数据量也越大。
引入迁移学习
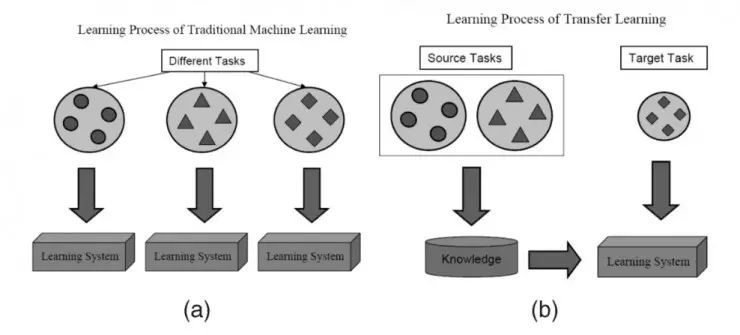
在大多数情况下,面对某一领域的某一特定问题,你都不可能找到足够充分的训练数据,这是业内一个普遍存在的事实。但是,得益于一种技术的帮助,从其他数据源训练得到的模型,经过一定的修改和完善,就可以在类似的领域得到复用,这一点大大缓解了数据源不足引起的问题,而这一关键技术就是迁移学习。
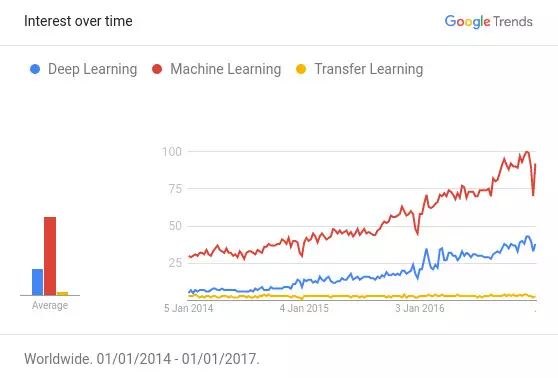
根据Github上公布的“引用次数最多的深度学习论文”榜单,深度学习领域中有超过50%的高质量论文都以某种方式使用了迁移学习技术或者预训练(Pretraining)。迁移学习已经逐渐成为了资源不足(数据或者运算力的不足)的AI项目的首选技术。但现实情况是,仍然存在大量的适用于迁移学习技术的AI项目,并不知道迁移学习的存在。如下图所示,迁移学习的热度远不及机器学习和深度学习。
迁移学习的基本思路是利用预训练模型,即已经通过现成的数据集训练好的模型(这里预训练的数据集可以对应完全不同的待解问题,例如具有相同的输入,不同的输出)。开发者需要在预训练模型中找到能够输出可复用特征(feature)的层次(layer),然后利用该层次的输出作为输入特征来训练那些需要参数较少的规模更小的神经网络。由于预训练模型此前已经习得了数据的组织模式(patterns),因此这个较小规模的网络只需要学习数据中针对特定问题的特定联系就可以了。此前流行的一款名为
Prisma
的修图App就是一个很好的例子,它已经预先习得了梵高的作画风格,并可以将之成功应用于任意一张用户上传的图片中。
值得一提的是,迁移学习带来的优点并不局限于减少训练数据的规模,还可以有效避免过度拟合(overfit),即建模数据超出了待解问题的基本范畴,一旦用训练数据之外的样例对系统进行测试,就很可能出现无法预料的错误。但由于迁移学习允许模型针对不同类型的数据展开学习,因此其在捕捉待解问题的内在联系方面的表现也就更优秀。如下图所示,使用了迁移学习技术的模型总体上性能更优秀。
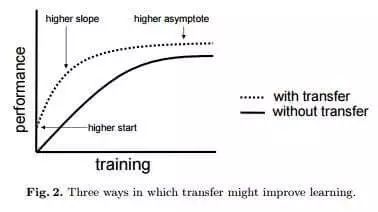
迁移学习到底能消减多少训练数据?

这里以此前网上流行的一个连衣裙图片为例。如图所示,如果你想通过深度学习判断这条裙子到底是蓝黑条纹还是白金条纹,那就必须收集大量的包含蓝黑条纹或者白金条纹的裙子的图像数据。参考上文提到的问题规模和参数规模之间的对应关系,建立这样一个精准的图像识别模型至少需要140M个参数,1.2M张相关的图像训练数据,这几乎是一个不可能完成的任务。








