
SQL是数据库的查询语言,语法结构简单,相信本文会让你从入门到熟练。
掌握SQL后,不论你是产品经理、运营人员或者数据分析师,都会让你分析的能力边界无限拓展。别犹豫了,赶快上车吧!
以下的语句都在SequelPro的Query页面运行,其他操作页面不会有太大差异。标点符号必须为英文,这是新人很容易犯的错误。
SQL最小化的查询结构如下:
table是我们的表名,column是我们想要查询的字段/列,column可以用 * 代替,指代全部字段,意为从table表查询所有数据。
where 是基础查询语法,用于条件判断。
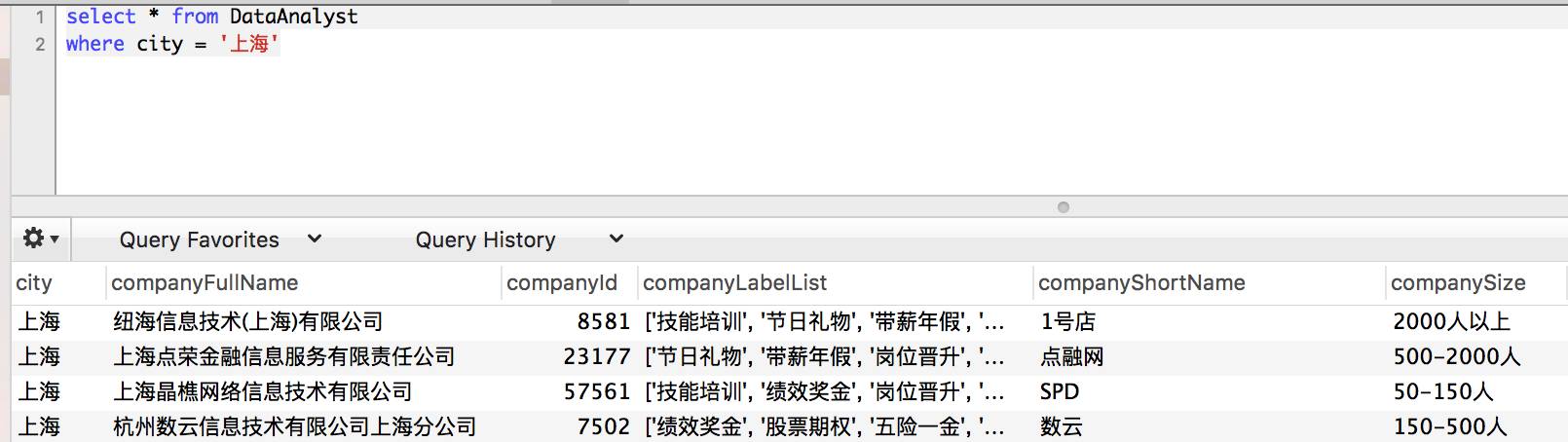
上图是最简化的查询语句,将所有城市为上海的职位数据过滤出来。我们也可以用 and 进行多条件判断。
or 语句则是或的关系
查找城市为上海,或者职位名称是数据分析师的数据,它们是并集。
当我们涉及到非常复杂的与或逻辑判断,应该怎么办?比如即满足条件AB,又要满足条件C,或者是满足条件DE。此时需要用括号明确逻辑判断的优先级。
这条语句的含义是查找出上海的数据分析师或者是北京的产品经理。当有括号时,会优先进行括号内的判断,当有多个括号时,对最内层括号先进行判断,然后依次往外。
接下来的问题来了,当我们要查询多个条件,比如北京上海广州深圳南京这些城市,难道一个个用and关联起来?这太麻烦了,我们可以使用 in 。
select * from DataAnalyst
where city in ('北京','上海','广州','深圳','南京')
当我们遇到字段数据类型是数值时,也可以使用符号> 、>=、< 、<=、!= 进行逻辑判断,!= 指的是不等于,等价于 <> 。
上例是筛选出公司ID >= 10000的职位,为数值时,不需要像字符串一样加引号。
当我们需要取区间数值时,使用 between and
between and 包括数值两端的边界,等同于 companyId >=10000 and companyId <= 20000。
如果要模糊查找,能用like。
语句的含义是在positionName列查找包含「数据分析」字段的数据,%代表的是通配符,含义是无所谓「数据分析」前面后面是什么内容。如果是 '数据分析%' ,则代表字段必须以数据分析开头,无所谓后面是什么。
除了上面所讲,还有一个常用的语法是not,代表逻辑的逆转,常见not in、not like、not null等。
接下来我们学习group by,它是数据分析中常见的语法,目的是将数据按组/维度划分。类似于Excel中的数据透视表,我们以city为例。
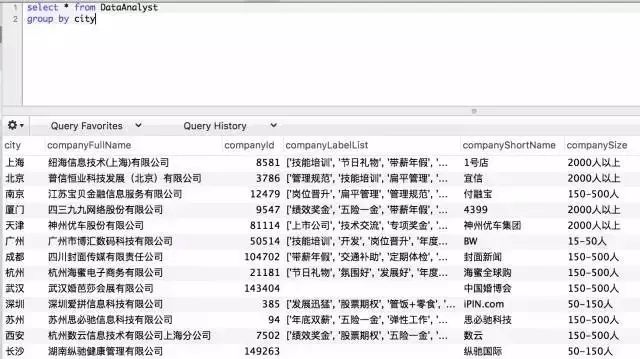
它将城市划分成几组,通过group by 可以快速的浏览数据有哪些城市。我们看一下它的高阶用法。
![]()
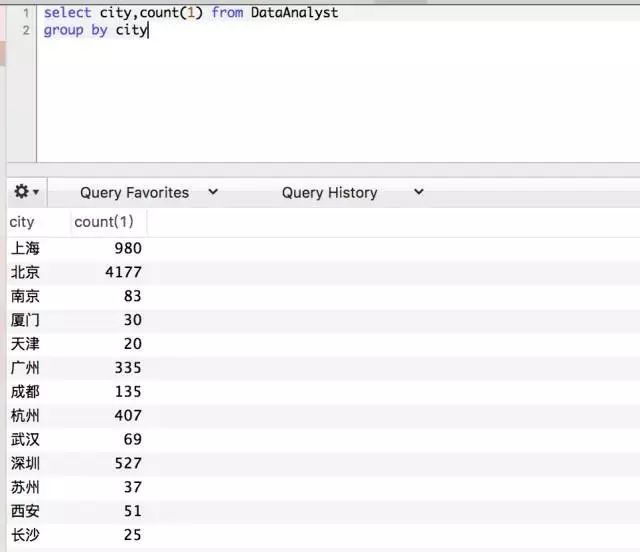
上述语句,使用count函数,统计计数了每个城市拥有的职位数量。括号里面的1代表以第一列为计数标准。这里出现新的问题,当我们遇到重复数据怎么办?在DataAnalyst 这张表中,北京职位包含重复的职位ID,我们需要去重。
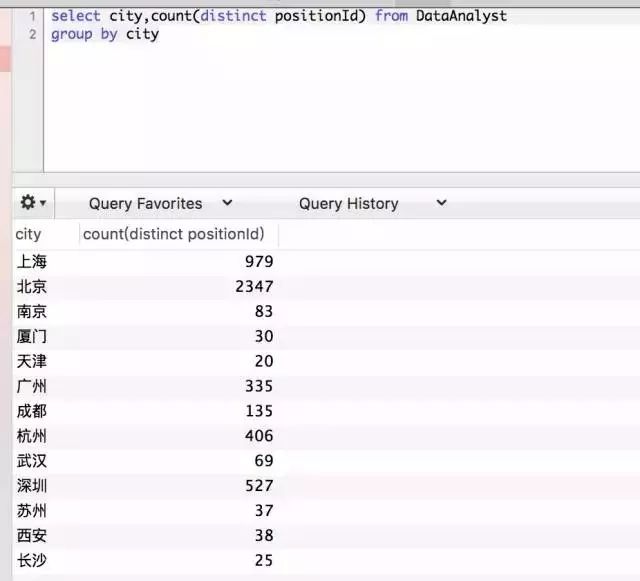
![]()
北京的数据一下子少了2000,多余的重复值被排除在外。distinct 是去重函数,distinct positionId 会只计算唯一的positionId个数。日常工作中,活跃用户数、文章UV,都是用distinct 计算获得,这是唯一标示符ID的重要作用。
除了count,还有max,min,sum,avg等函数,也叫做聚合函数。用法和Excel没什么区别。
当我们在group by 添加多个字段,它将以多维的形式进行数据聚合。
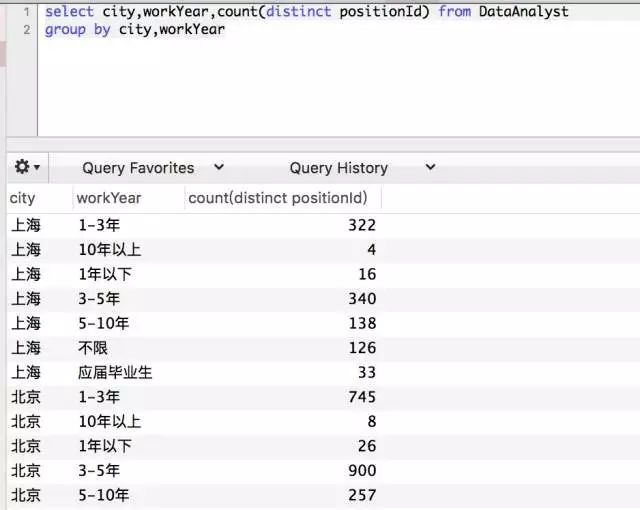
![]()
这就是数据分析师常用的多维分析法,通过group by 切分不同的维度进行对比,在不利用BI的情况下,通过SQL进行快速数据分析。
接下来学习逻辑判断,SQL也有if函数,和Excel的用法一摸一样,通过它我们能进行复杂的运算。比如我想统计各个城市中有多少数据分析职位,其中,电商领域的职位有多少,在其中的占比?
industryField是公司的行业领域,虽然我们能用where like 计算出有几个电商的数据分析师,但是占比的计算会比较麻烦,此时可以用if。
select if(industryField like '%电子商务%',1,0) from DataAnalyst
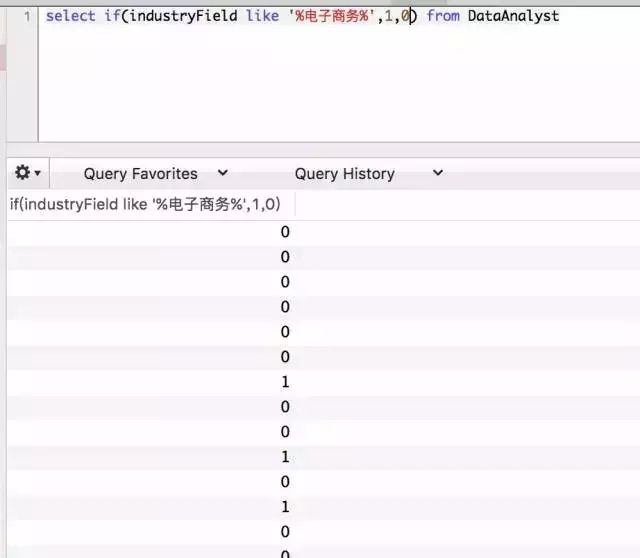
![]()
上面的公式利用if判断出哪些是电商行业的数据分析师,哪些不是。if函数中间的字段代表为true时返回的值,不过因为包含重复数据,我们需要将其改成positionId。之后,用它与group by 组合就能达成目的了。
select city,
count(distinct positionId),
count(if(industryField like '%电子商务%',positionId,null))
from DataAnalyst
group by city
![]()
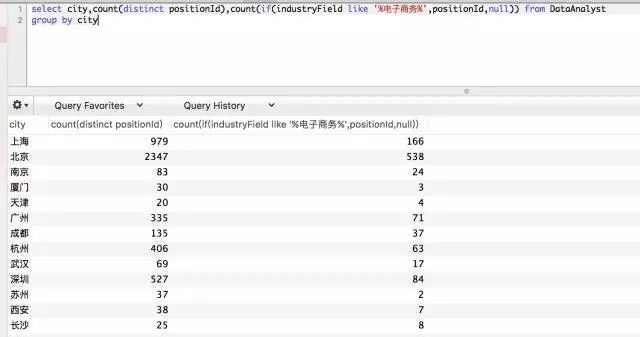
第一列数字是职位总数,第二列是电商领域的职位数,相除就是占比。记住,count是不论0还是1都会纳入计数,所以第三个参数需要写成null,代表不是电商的职位就排除在计算之外。
接下来是新的问题,如果我想找出各个城市,数据分析师岗位数量在500以上的城市有哪些,应该怎么计算?有两种方法,第一种,是使用having语句,它对聚合后的数据结果进行过滤。
select city,count(distinct positionId) from DataAnalyst
group by city having count(distinct positionId) >= 500
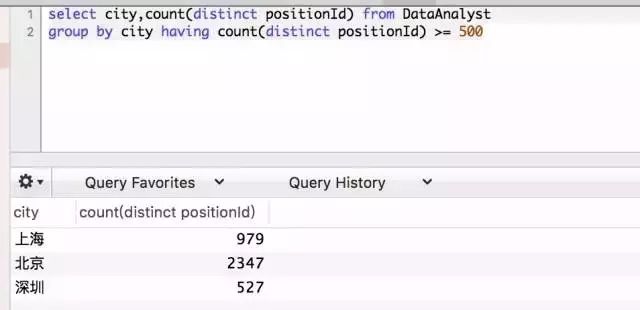
![]()
第二种,是利用嵌套子查询。
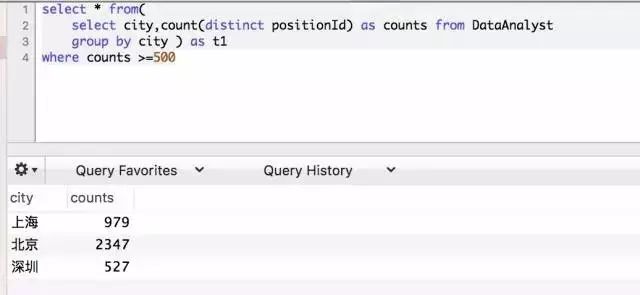
![]()
我们将第一次查询获得的城市职位数的结果,看作一张新的表,利用as 将它命名为t1( table1 的简写),将职位数命名为一个新的字段counts。然后外面再套一层select 过滤出counts >=500。
这种查询方式就叫嵌套子查询,使用场景比较广泛,where 后面也能跟子查询。
很多时候,数据是凌乱的,我们希望结果能够呈现一定的顺序,这时候就用到order by语句。
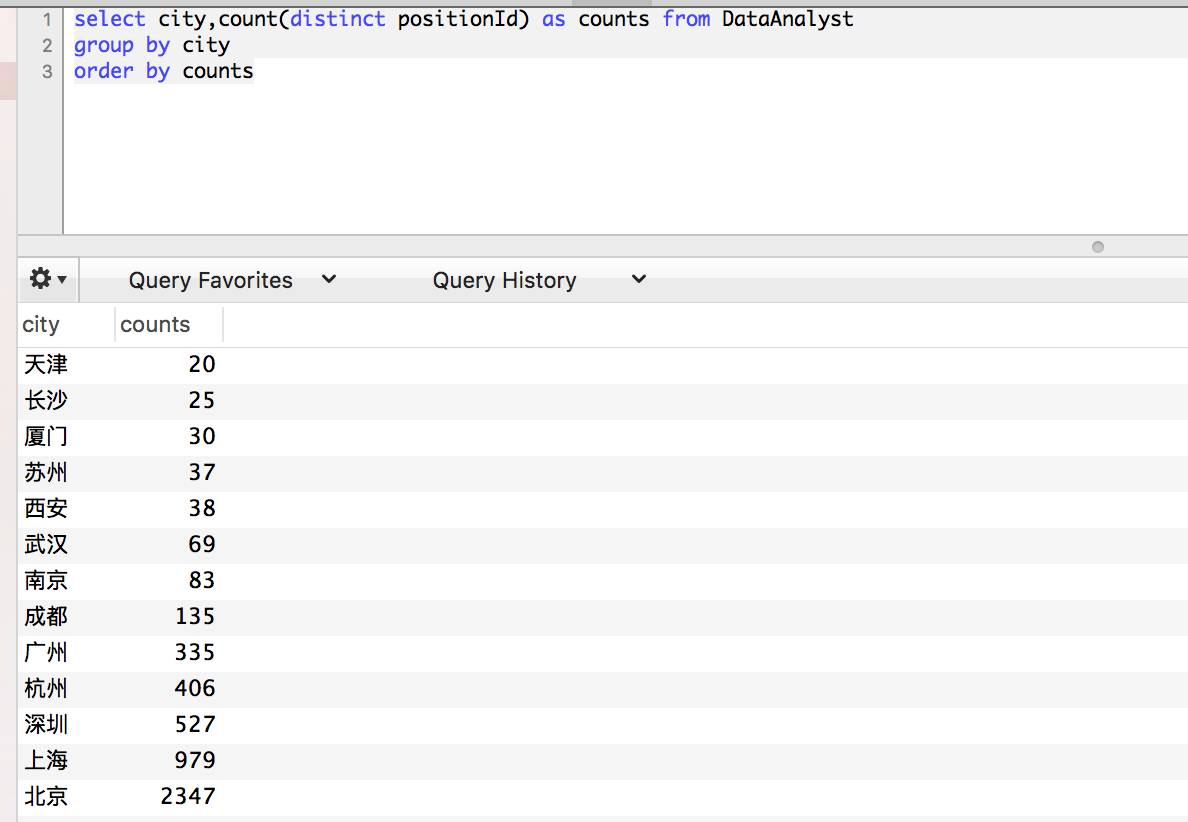
看,数据就按照统计结果升序排列,如果需要降序,则是order by counts desc,后面加一个desc就好了。如果是多个字段,按逗号分隔即可。
我们再来熟悉SQL的常用函数,首先是时间。因为我们的练习数据中没有时间,首先用now创建出一个时间字段。
直接执行它,就能获得当前的系统时间,精确到秒。其实select不一定后面要跟from。
它代表的是获得当前日期,week函数获得当前第几周,month函数获得当前第几个月。其余还包括,quarter,year,day,hour,minute。
时间函数也包含各种参数,比如week,因为中西方计算第几天是不一样的,西方把周日算作一周中的第一天,而我们习惯周一。
除了以上的日期表达,也可以使用dayofyear、weekofyear 的形式计算。它和上面的部分函数等价。
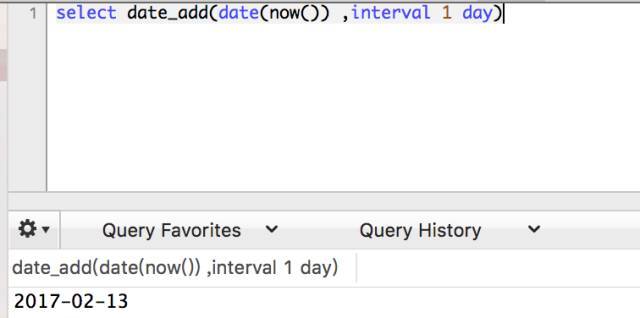
怎么对时间进行加减法呢?这时候靠date_add函数出马。
![]()
我们可以改变1为负数,达到减法的目的,也能更改day为week、year等,进行其他时间间隔的运算。如果是求两个时间的间隔,则是datediff(date1,date2)或者timediff(time1,time2)。
时间函数的运用比较灵活,没有特殊限定,网络上的文档和教程也不少,可以深入学习。
最后是数据清洗类的函数。
MySQL支持left、right、mid等函数,这里又和Excel一样。我们通过salary计算数据分析师的工资吧(这一步骤,在曾经的文章中已经用Excel和BI多次讲解,所以我就不多赘述了,只讲过程,不熟悉的同学可以看历史内容)。
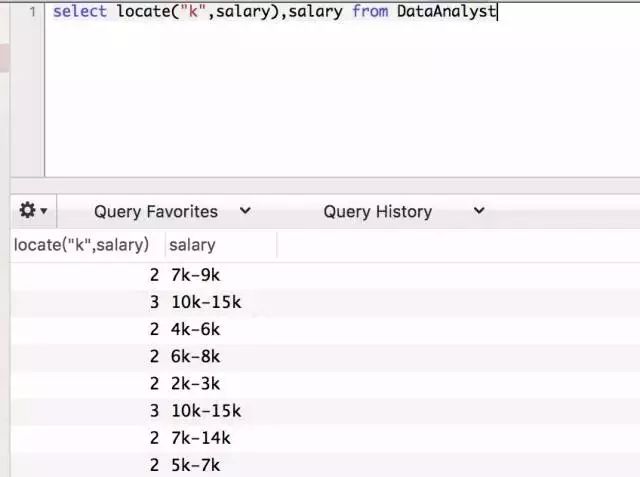
首先利用locate函数查找第一个k所在的位置。
![]()
然后使用left函数截取薪水的下限。
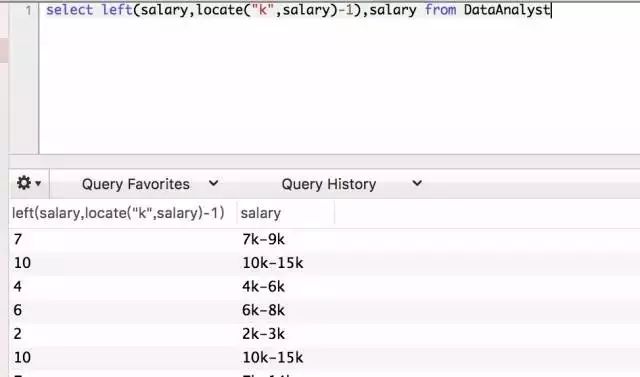
![]()
为了获得薪水的上限,要用substr函数,或者mid,两者等价。
substr(字符串,从哪里开始截,截取的长度)
薪水上限的开始位置是「-」位置往后推一位。截取长度是整个字符串减去「-」所在位置,刚好是后半段我们需要的内容,不过这个内容是包含「K」的,所以最后结果还得再减去1。
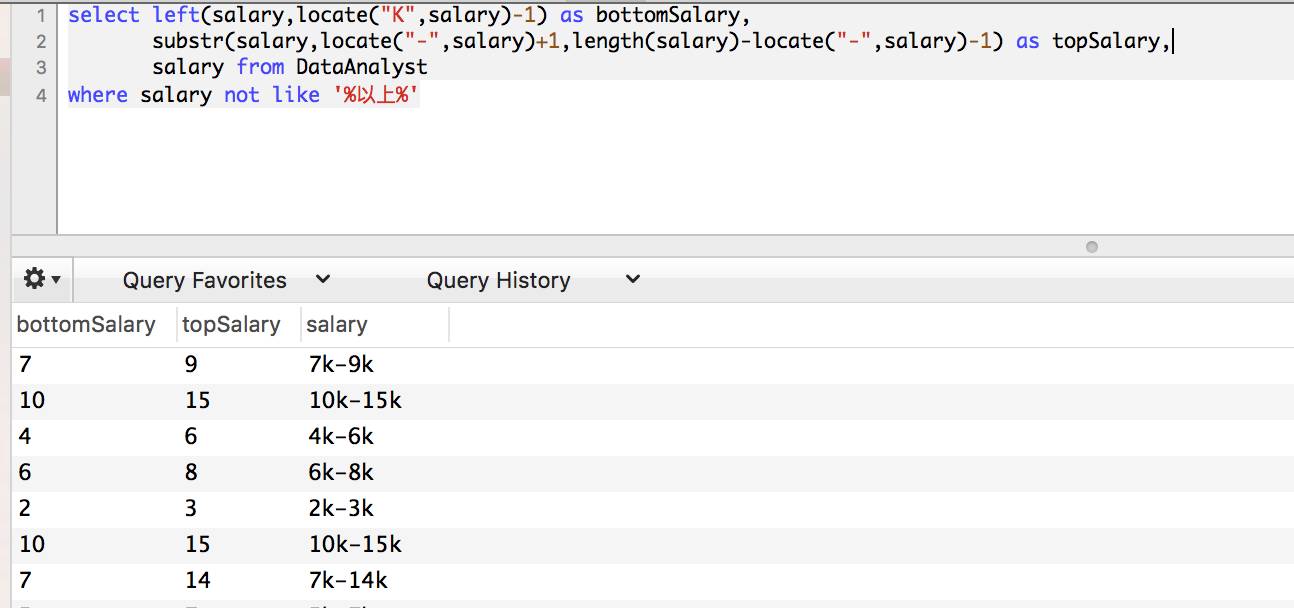
这里不了解不要紧,可以将计算过程分步骤运行。基本上,了解了上面写法的含义,文本清洗这块就没有问题了(not like用来清洗乱七八糟的薪水,我简单处理了)。再然后计算不同城市不同工作年限的平均薪资。
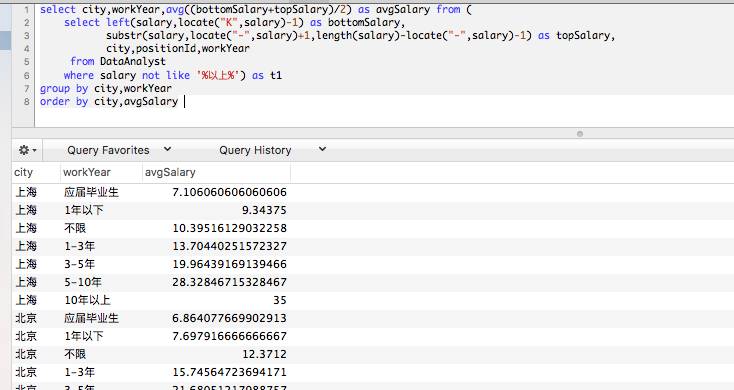
上面语句,我们用了文本清洗、子查询嵌套、分组聚合、排序等多种用法,属于较复杂的查询。重复数据的问题,因为我是复制了一份北京数据,数量刚好乘二,对平均数没有影响,感兴趣的朋友可以再加一步清洗掉它。
下面是三道思考题:
查询出哪家公司招聘的岗位数最多;
查询出O2O、电子商务、互联网金融这三个行业,哪个行业的平均薪资最高;
查询出各城市的最高薪水Top3是哪家公司哪个岗位。
做完上面的题目,你已经神功初成,数据分析的SQL意见没有大问题了。更复杂的查询,也无非是嵌套更多的内容,本质思路是一样的。
讲到这里,只剩join语法还没有教大家。因为练习数据只有一张表,而join又是SQL中比较容易混淆的难点,我会单独开一篇内容讲解,到时候使用SQLZoo和LeetCode的案例。
LeetCode是知名的算法竞赛网站,可以在上面和全世界的程序员比拼算法,当然我们只练习SQL,完成后,至少能秒杀全世界50%的程序员吧。
End.
作者:秦路(中国统计网特邀认证作者)






