fastText 是 Facebook 开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快。
Facebook 在此前的研究中
宣称人们可以使用一个标准多核 CPU 在十分钟内完成 fastText 上 10 亿多词的训练,并在一分钟内将 50 万个句子分成 31.2 万个类别。去年 8 月,Facebook 将这一技术开源。
昨天,Facebook 人工智能研究院(FAIR)进一步拓展了 fastText 的应用范围,他们发布了支持 294 种语言的预训练矢量文件包,并配有两个快速入门教程,为学生、软件开发者和机器学习研究人员提供了更多支持。同时,随着 fastText 模型内存使用量的减少,它现在已经可以装进手机和树莓派这样的小型计算设备中了。
在小内存设备上的 fastText
为了让更多人和应用在移动端享受到 fastText 带来的便利,Facebook 本次推出的新版本降低了 fastText 模型的内存需求。基于早期版本 fastText 构建的模型通常需要几 G 的内存,而新版本只需要数百 Kb。
FAIR 团队的研究者们通过最近发布的 FAISS(一种用于高维度向量相似性搜索和聚类的开源库)压缩了 fastText 模型和内存使用量。对此,研究团队发表了一篇论文《FastText.zip: Compressing Text Classification Models》描述了两个研究项目的整合研究。
论文链接:https://arxiv.org/pdf/1612.03651.pdf
简单且最棒的文本分类器
fastText 旨在让开发者、研究者和学生们能够快速上手。它的速度特性可以让你快速迭代产品,并在没有专门硬件的情况下优化你的模型。fastText 模型可以在任何多核 CPU 上用不到几分钟的时间训练超过十亿单词,或在不到一分钟时间里将五十万个句子分类成几百到数千个类。
fastText 分类器在与更复杂、通过 GPU 加速的神经网络架构相比有很大优势。两者之间的比较在 Facebook 研究团队发表的另一篇论文《Bag of Tricks for Efficient Text Classification》中已有体现。相比神经网络模型,fastText 的精度损失很小。
论文链接:https://arxiv.org/pdf/1607.01759.pdf
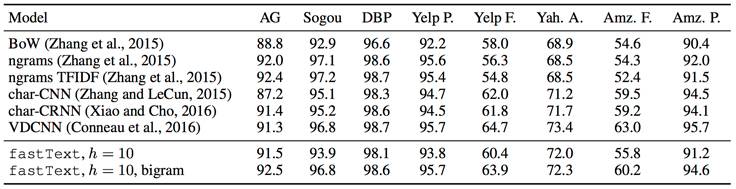
fastText 与卷积神经网路在情绪分析任务中的对比。
FAIR 设计 fastText 的过程
在机器学习的发展历程中,软件的研究进度往往超过硬件,研究者们经常需要优化已有程序的性能——提高准确性,同时减少计算能力的消耗量。Facebook 的研究团队在这样的过程中已经积累了不少经验,然而在 fastText 的改进中,研究人员还是遇到了挑战:其中一个约束是需要将机器学习拓展到拥有多核 CPU 和 C++编译器的计算机中——这意味着把 fastText 送到几乎所有开发者的手中。
Facebook 构建出了一个简单而强大的库来解决在通用型/弱性能机器中处理重要文本分类的问题。fastText 作为学习文本分类的库,和为应用增加精确文本分类特性的工具都表现良好。fastText 同时允许开发者增加文本分类特性,如标签和评论情绪等级分析——而无需对此进行通常需要的机器学习训练。
使用低维度向量来提高性能。大向量可以提高准确性,因为这类词向量中通常含有很多特征,但是它们非常耗费训练时间和计算资源。如果使用低维度向量,通过表示正确的特征,模型可以扩容为巨大的语料库,同时达到目前最好的表现。在编码期间,通过常规优化方法可以缩减向量尺寸,获得低维度向量。
训练时间则是通过基于 softmax 的 Huffman 编码树(二叉树的变体)来减少的。在运行中,最可能类的搜索时间也被减少了,因为表示字向量的树的每个叶具有相关联的概率。下分支的叶具有相对更低的概率。概率计算在路径中随着低概率分支的丢弃而变得更加快速。
fastText 使用词袋模型来获取特征,通过线性分类器训练模型。因为词袋模型无法识别句子的语序,所以生成的高频词广义语境特征不与低频词共享,从而导致低频词的准确率很低。使用可以识别单词顺序并向低频率词向量共享信息的 n-gram 模型代替词袋模型可以解决这个问题,但增加了复杂性、训练时间和计算需求。在 fastText 中,训练时可以使用部分 n-gram 信息,我们可以通过选择句子中目标词上下文的单词数来平衡训练时间和准确性。
fastText 比目前流行的 word2vec 工具或其他最先进的形态词表示方法有更好的表现,同时包含了更多语言。在本次发布后,FAIR 的研究团队会持续对 fastText 进行改进,在未来这个工具将变得更容易使用。
在精度相同的情况下,fastText 的速度比其他方法更快。在与目前最好的神经网络模型的性能对比中,fastText 要快 1000 到 10000 倍。这就是简化和低阶线性模型与标准特征(如二元)应用带来的优势。
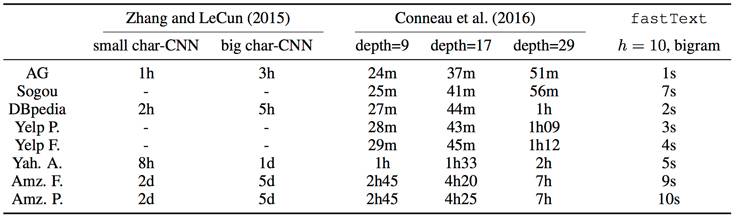
下表展示了 fastText 的性能: