
作者:
大中
全文共 2389 字,阅读需要 5 分钟
—— BEGIN ——
你知道在三四线的县城,用户在哪里看新闻么?
不是在今日头条里,而是在微信中的那个腾讯新闻里。
这是我在安徽青阳做用户调研时绝大多数给我的回答。这或许说明一点:用户没有像设计师那样的洁癖,期望每一个app都有明确的边界。
谁说不能在一个社交app里看新闻?我还要加一句,谁说不能在本地头条(我正在负责的产品)里看全国头条?
说是这么说了,但是心里清楚——这只是产品的外延,既然是外延就应该追求做产品的性价比,所以才有了这个极简的新闻聚合产品。
先定个产品的小目标:通过全技术的方式,给用户提供一个高频更新的新闻列表,运营可进行微调干预。
整个过程7步完成,对,就是七步成诗那七步。
一、构建标签库
标签库其实就是词条库,词条哪里来?
或者换一个问法,互联网上谁最懂中文?
答案当然是百度咯。
跑到百度百科首页一看,我们要的东西就躺在下面的红框里。
那我们还客气啥,爬呀~
等等,1400万是不是有点太多了?那我们就去掉一点吧,只留下名词好了,这样可以把词库控制在百万量级。
二、抓取新闻
接下来,就是抓新闻。
新闻哪里有,找门户网站呗;公众号app就算了,费时费力;爬PC站不是一样的嘛。
以体育为例,我们可以挑选新浪体育、搜狐体育、凤凰体育,还有什么体育?你也看出来了——其实我对体育无感,这里就假设有10个体育专题网站吧。
我们要抓的是热门新闻,啥叫热门?出现在第一屏的就是热门。所以我们抓取的时候,只抓取首屏新闻。
结果就是我有了一堆标题和链接,还有链接后面的正文。
三、建立新闻和标签的关联
现在到了建立新闻和标签关联的时候了,首先当然是要分词,怎么分?
呃,这个好像有很多自然语言词库的吧,你自己去找吧~
分词完了之后,计算各个词的出现频率,出现频率越高说明它越可能是这篇文章的关键词。
出现在标题里的词是不是比出现在正文里的词更重要呢?所以你可以把标题里的词加个N倍权重,N等于几?关注我私信我就告诉你。
这里分出来的词,其实就是标签库里的标签。这样每一篇文章就有一个对应的词频由高到低的标签列表了,太长了也没用,就取TOP5吧。
这里有个问题留给你,既然文章要分词,文章分出来的词直接做词库不就好了,为啥要去百度爬呢?答案还是要关注我私信我才告诉你。
四、标签热度排序
现在我们为体育频道选择了10个数据源(就是新浪体育这样的网站),每个数据源下抓了50篇文章,每篇文章都有5个标签,现在我们要看哪个标签最热了。
我们的方式简单得很,否则怎么说我们设计了一个极(jian)简(lou)的产品呢,方法是如果一个标签在一个数据源出现了,就加1,在10个数据源都出现了那就是10。
通过这种方式你会得到每一个标签的值,这个值除以数据源总数就是“热度值”,在我们这里就是0.1到1之间的分布。
这个时候运营的妹子来乱入了,她说她的特长就是八卦,而且是先人一步的八卦,让我们千万要相信她判断热点的是否会大热的能力。
这句话的意思是:
她想来人肉预先提升一个标签的热度值,虽然现在它还没有大热。
嗯,平常关系辣么好,我不信也得做个姿势选择相信,于是就有了下面的线框。她可以调整一个标签次的热度值。
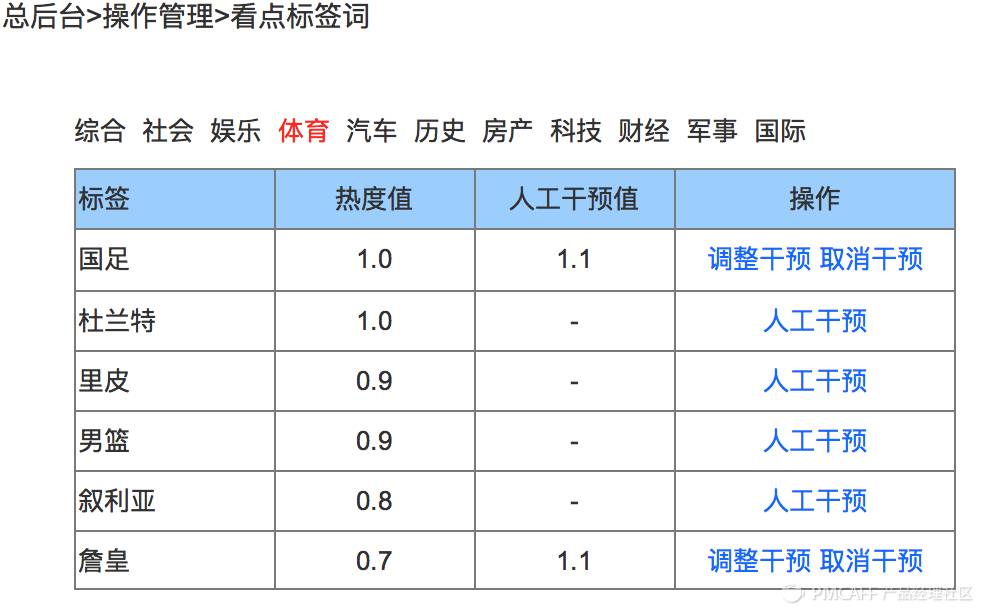
呀,最后怎么还有两个词连接在一起的?实际上多个词比单个词更接近于一个热点事件。当然对于这种二元词,计算方式和一元词略有不同,细节此处不展开。
五、文章按频道排好序
到这里我们已经有了标签的热度排序,那文章的热度怎么算呢?
文章不是有5个标签嘛,那个最高热度值标签的热度就是文章的热度。
实际上热度只是文章的一个维度,要给文章排序,你自然还会想到以下的几个维度:
具体算法上可以用高斯衰减:比如72小时内基本无衰减,超过72小时后每过12小时就衰减一点。
说到衰减,最近看了采铜的效益半衰期理论感觉颇为受用,大意是:一个人管理自己日常的行为,可以考虑这个行为对自己长期受用程度来衡量;有些事情效益半衰期很长比如读书和健身,就应该多做,另外一些事情效益半衰期很短比如游戏,就可以少做。
扯一扯防松一下,接回来说。
文章要排序,就是看这3个因子,编一个数据公式把:热度分,质量分,时效分串起来计算出一个数值就ok了。
想要公式?好像不是很方便哎,再说你那么聪明,自己也能搞出来。
六、按频道权重整合输出
文章有了排序,下一步直接输出么?可是当前我们只有一个全国新闻频道,细分分频道啊,个性化呀那都是以后的事情,极简系统就是千人一面的啦。
所以下一步我们要定一下各种频道的内容如何混在一起。这个没有啥技术含量,就是给各个频道定个权重,然后按这个权重计算个比例去混合就好了。
技术上可确保:用户看的越多,实际比例就越接近预先定义的权重分布。










