点击下方
卡片
,关注
「3D视觉工坊」
公众号
选择
星标
,干货第一时间送达
来源:机器之心,编辑:佳琪、蛋酱
添加小助理:cv3d001,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。
扫描下方二维码,加入
「3D视觉从入门到精通」知识星球
(
点开有惊喜
)
,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:
近20门秘制视频课程
、
最新顶会论文
、计算机视觉书籍
、
优质3D视觉算法源码
等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

四个 10 分!罕见的一幕出现了。
您正在收看的,不是中国梦之队的跳水比赛,而是 ICLR 2025 的评审现场。
虽说满分论文不是前无古人,后无来者,但放在平均分才 4.76 的 ICLR,怎么不算是相当炸裂的存在呢。

https://papercopilot.com/statistics/iclr-statistics/iclr-2025-statistics/
这篇征服了列位审稿人的论文,正是 ControlNet 作者张吕敏的新作 IC-Light。我们很少看到一篇论文,能够让四位审稿人给出高度一致的「Rating: 10: strong accept, should be highlighted at the conference」。
早在向 ICLR 投稿之前,IC-Light 就已经在 Github 上开源半年了,收获了 5.8k 的星标,足见其效果之优秀。
最初版本是基于 SD 1.5 和 SDXL 实现的,而就在前几天,团队又推出了 V2 版本,适配了 Flux,效果也更上一层楼。
感兴趣的朋友们,可以直接试玩。
-
Github 项目:https://github.com/lllyasviel/IC-Light?tab=readme-ov-file
-
V2 版本:https://github.com/lllyasviel/IC-Light/discussions/98
-
试玩链接:https://huggingface.co/spaces/lllyasviel/IC-Light
IC-Light 是一个基于扩散模型的照明编辑模型,可以通过文本精准控制图像的光照效果。
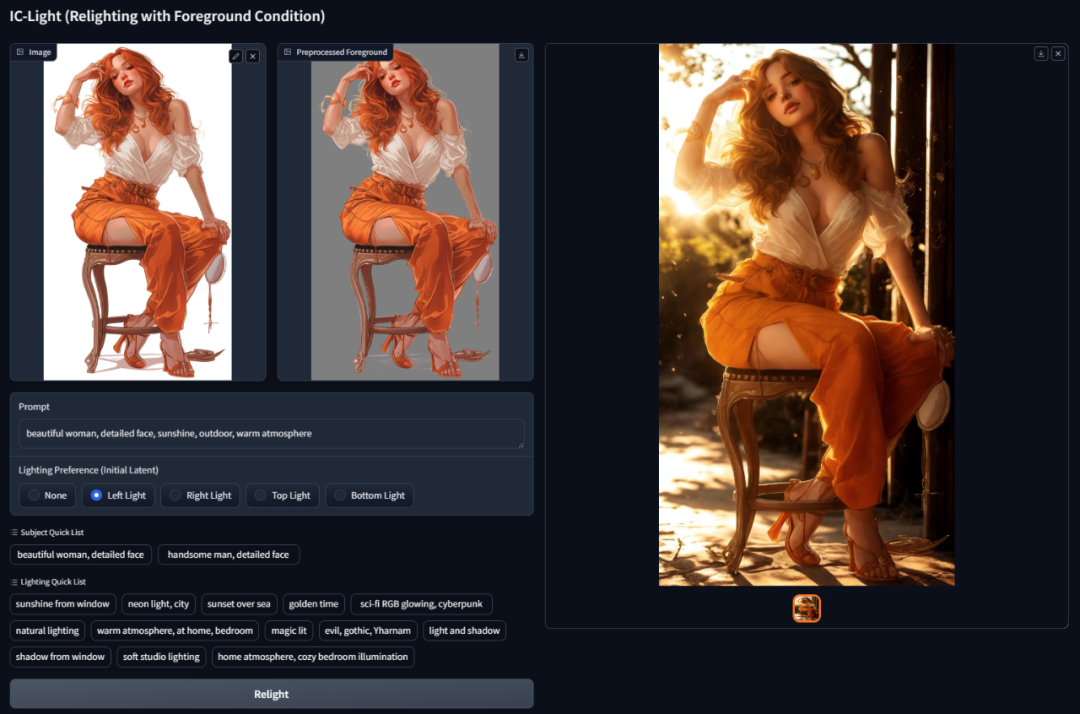
也就是说,要放在 PS 里打开蒙版、打开 alpha 通道,调试明暗分离才能搞定的光影效果,用上 IC-Light,就变成了「动动嘴皮子的事」。
输入 prompt,要让光从窗户里打进来,于是就能看到阳光透过雨后的窗户,在人物侧脸打出柔和的轮廓光。
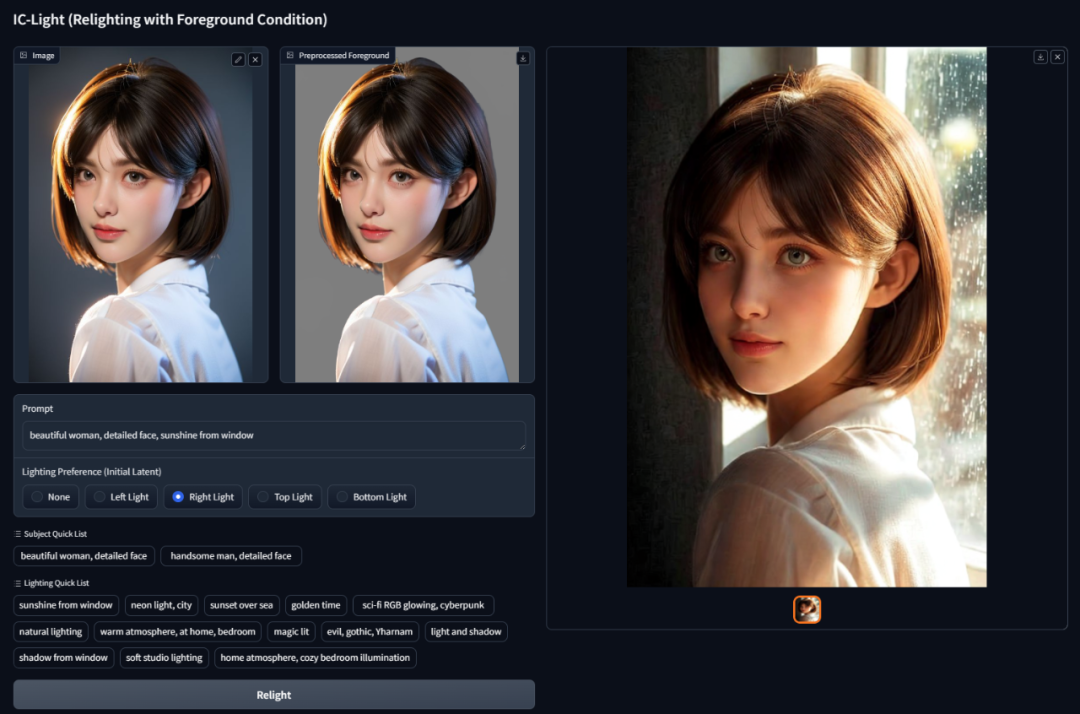
IC-Light 不仅精准地还原了光线的方向,还精准地呈现了光透过玻璃的漫射效果。
对霓虹灯这样的人工光源,IC-Light 的效果同样出色。
根据提示词,原本在教室里的场景立马爆改赛博朋克风格:霓虹灯的红蓝双色打在人物身上,营造出深夜都市特有的科技感和未来感。
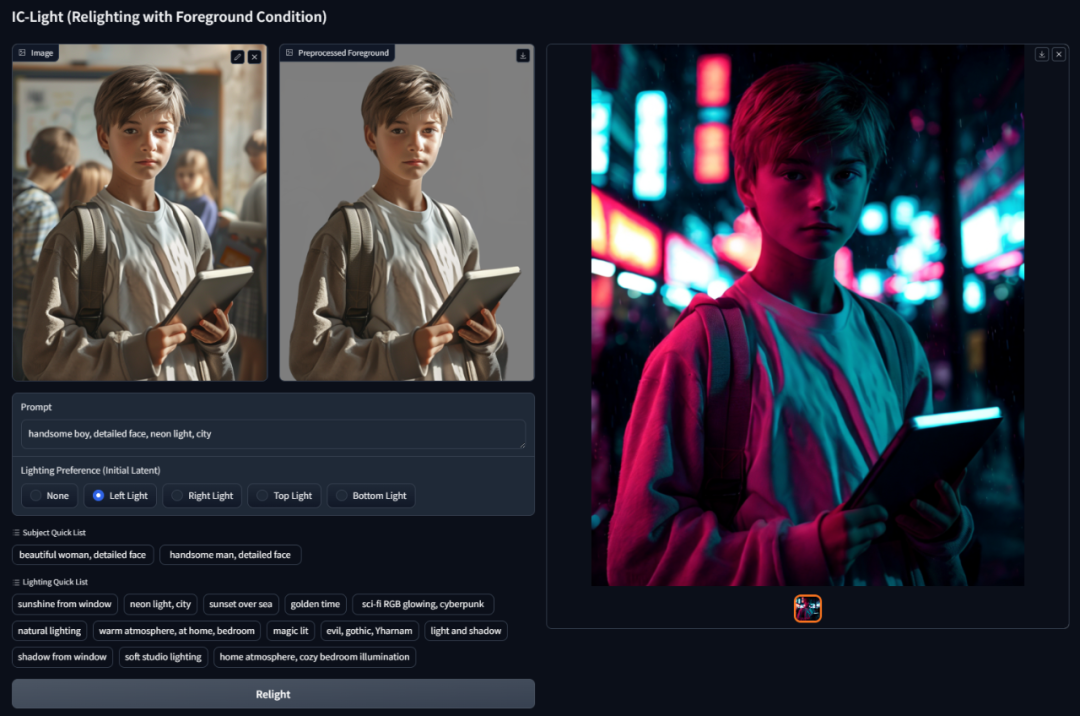
模型不仅准确还原了霓虹灯的色彩渗透效果,还保持了人物的一致性。
IC-Light 还支持上传背景图片,来改变原图的光照。

而说到 ControlNet,大家应该都不陌生,它可是解决了 AI 绘画界一个老大难问题。
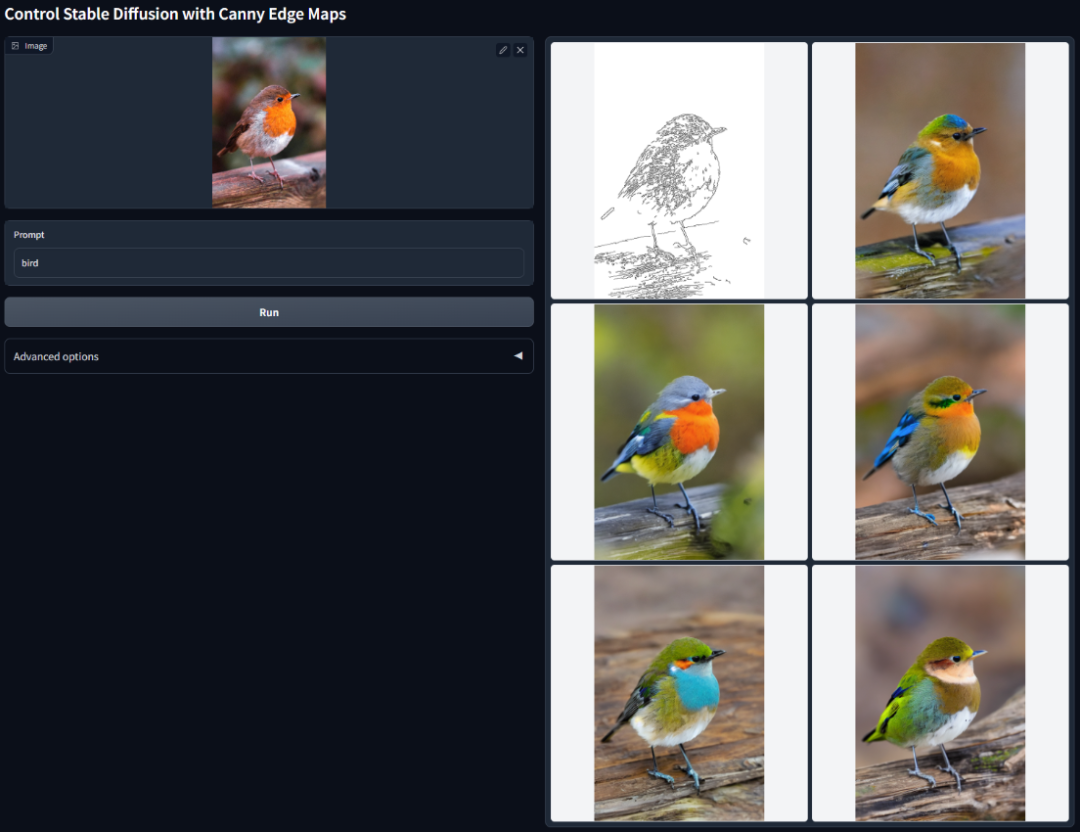
Github 项目:https://github.com/lllyasviel/ControlNet
之前,Stable Diffusion 最让人头疼的就是无法精确控制图像细节。
不管是构图、动作、面部特征还是空间关系,即便提示词已经做了很详细的规定,但 SD 生成的结果,依然要坚持 AI 独特的想法。
但 ControlNet 的出现就好像是给 SD 装上了「方向盘」,许多商业化的工作流也因此催生。
学术应用两开花,ControlNet 在 ICCV 2023 摘下了马尔奖(最佳论文奖)的桂冠。

虽然很多业内人士表示在卷得飞起的图片生成领域,真正的突破越来越难。但张吕敏似乎总能另辟蹊径,每次出手都能精准命中用户需求。这一次也不例外。
在现实世界中,光照和物体表面的材质是紧密关联的。比如你看到一个物体时,很难分清楚是光线还是材质,让物体呈现出是我们眼中样子。因此,在让 AI 编辑光线时,也很难做到不改变物体本身的材质。
以前的研究想通过构建特定的数据集来解决这个问题,但收效甚微。而 IC-Light 的作者发现用 AI 合成生成的数据加上一些人工处理,能达到不错的效果。这个发现对整个研究领域都有启发意义。
ICLR 2025 刚放榜之时,IC-Light 就凭借「10-10-8-8」稳坐最高分论文的宝座。
审稿人们在审稿意见里也不乏赞美之词:
「这是一篇精彩论文的典范!」
「我认为所提出的方法和由此产生的工具将立即对许多用户有用!」
在 rebuttal 结束,补了一些参考文献和实验之后。那两位给 8 分的审稿人也欣然改成了满分。

下面,就让我们一起来看看满分论文具体都写了什么。
研究细节

在这篇论文中,研究者根据光传输独立性的物理原理,提出了在训练过程中强加一致光(IC-Light)传输的方法,其物理原理是:不同光照条件下物体外观的线性混合与混合光照下的外观一致。
如图 2 所示,研究者利用多种可用数据源对照明效果的分布进行建模:任意图像、3D 数据和灯光舞台图像。这些分布可以捕捉现实世界中各种复杂的照明场景,背光、边缘光、辉光等。为简单起见,此处将所有数据处理为通用格式。

但学习大规模、复杂和嘈杂的数据是一项挑战。如果没有合适的正则化和约束条件,模型很容易退化为与预期光照编辑不符的随机行为。研究者给出的解决方案是在训练过程中植入一致光(IC-Light)传输。
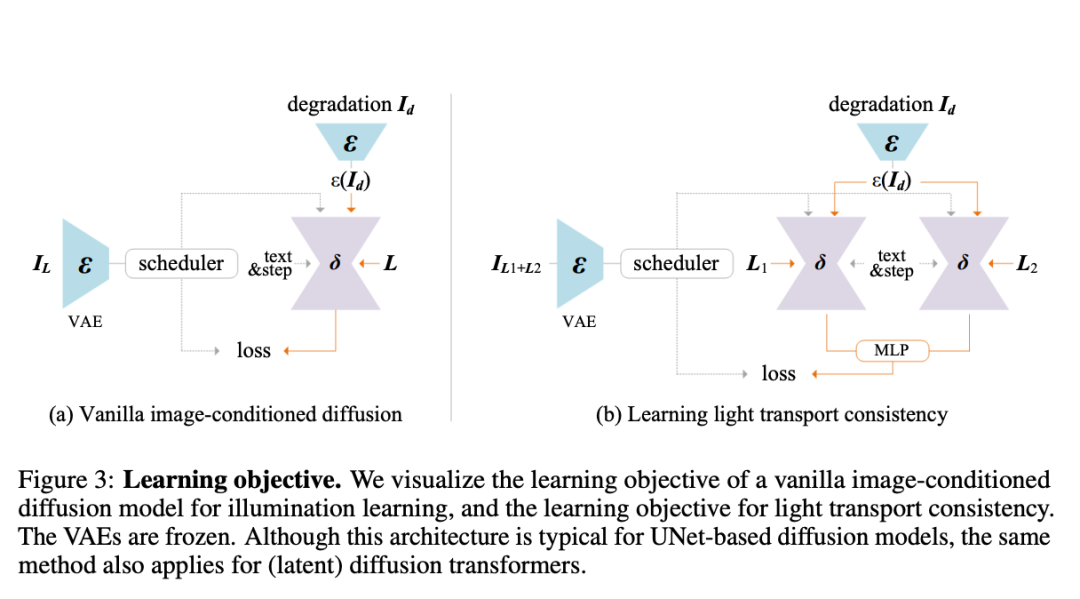
通过施加这种一致性,研究者引入了一个强大的、以物理为基础的约束条件,确保模型只修改图像的光照方面,同时保留反照率和精细图像细节等其他固有属性。这种方法可以在 1000 多万个不同样本上进行稳定、可扩展的训练,样本包括来自光照舞台的真实照片、渲染图像以及带有合成光照增强的野外图像。本文提出的方法能够提高光照编辑的精度,降低不确定性,减少伪影,同时不改变基本的外观细节。
总体来说,这篇论文的贡献主要包括:
(1) 提出了 IC-Light,一种通过施加一致光传输来扩展基于扩散的光照编辑模型训练的方法,确保在保留内在图像细节的同时进行精确的光照修改;
(2) 提供了预训练的光照编辑模型,以促进不同领域内容创建和处理中的光照编辑应用;
(3) 通过大量实验验证了这种方法的可扩展性和性能,显示了它在处理各种光照条件时与其他方法的不同之处;
(4) 介绍了其他应用,如法线贴图生成和艺术照明处理,进一步展示了该方法在真实世界、实际场景中的多功能性和鲁棒性。
实验结果
在实验中,研究者验证了扩大训练规模和数据源多样化可以增强模型的鲁棒性,并能提高各种与光照相关的下游任务的性能。
消融实验证明,在训练过程中应用 IC-Light 方法可以提高光照编辑的准确性,从而保留反照率和图像细节等内在属性。
此外,与在更小或更结构化的数据集上训练的其他模型相比,本文方法适用于更广泛的光照分布,如边缘照明、背光照明、魔法发光、日落光晕等。
研究者还展示了该方法处理更多野外照明场景的能力,包括艺术照明和合成照明效果。此外还探讨了生成法线贴图等更多应用,并讨论了这种方法与典型主流几何估计模型之间的差异。
消融实验
研究者首先恢复了训练中的模型,但删除了野外图像增强数据。如图 4 所示,移除野外数据严重影响了模型的泛化能力,尤其是对于肖像等复杂图像。例如,训练数据中不存在的肖像中的帽子经常会以不正确的颜色呈现(如从黄色变为黑色)。

研究者还尝试了移除光传输一致性。没有了这一限制,模型生成一致光照和保留反照率(反射颜色)等固有属性的能力明显下降。例如,一些图像中的红色和蓝色差异消失了,输出结果中也出现了明显的色彩饱和度问题。
而完整的方法结合了多种数据源,并加强了光传输的一致性,产生了一个能够在各种情况下通用的均衡模型。它还保留了细粒度图像细节和反照率等固有属性,同时减少了输出图像的误差。
其他应用
如图 5 所示,研究者还展示了其他应用,例如利用背景条件进行光照协调。通过对背景条件的额外通道进行训练,本文的模型可以完全根据背景图像生成照明,而无需依赖环境映射。此外,模型还支持不同的基础模型,比如 SD1.5、SDXL 和 Flux,这些模型的功能在生成的结果中都有所体现。

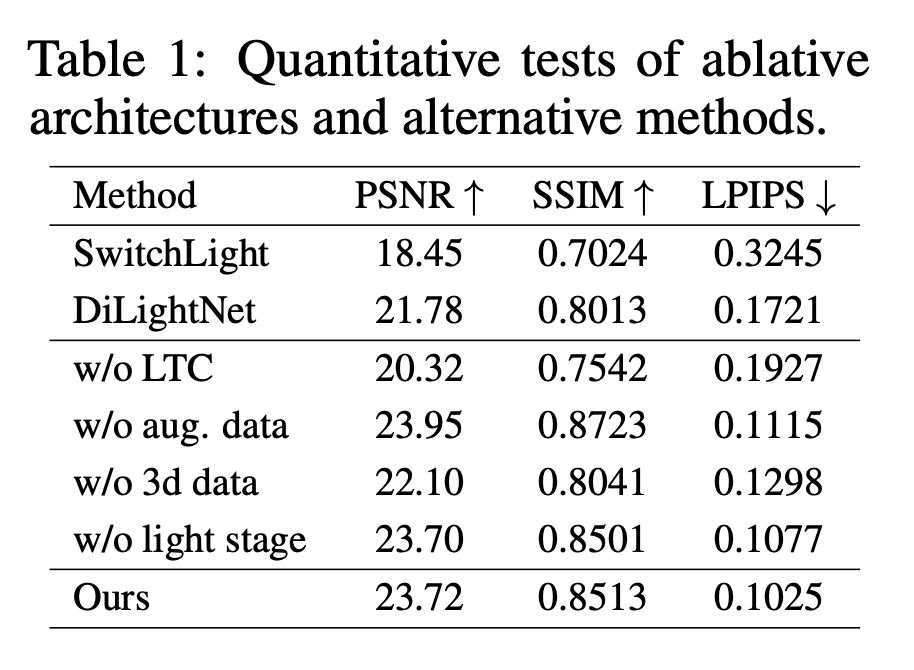
定量评估
在定量评估中,研究者使用了峰值信噪比(PSNR)、结构相似性指数(SSIM)和学习感知图像补丁相似性(LPIPS)等指标。并从数据集中提取了 50000 个未见过的 3D 渲染数据样本子集进行评估,确保模型在训练过程中没有遇到过这些样本。
测试的方法有 SwitchLight、DiLightNet,以及本文方法不包含某些组件(例如,不包含光传输一致性、不包含增强数据、不包含三维数据和不包含灯光舞台数据)的变体。
如表 1 所示,就 LPIPS 而言,本文方法优于其他方法,表明其具有卓越的感知质量。仅在三维数据上训练的模型获得了最高的 PSNR,这可能是由于对渲染数据的评估偏差所致(因为本次测试仅使用了三维渲染数据)。结合多种数据源的完整方法在感知质量和性能之间取得了平衡。
视觉对比
研究者还与之前的方法进行了直观比较。如图 6 所示,与 Relightful Harmonization 相比,由于训练数据集更大更多样化,本文模型对阴影的鲁棒性更高。SwitchLight 和本文模型产生了具有竞争力的重新照明结果。这种方法的法线贴图质量更细致一些,这要归功于从多个表象中合并和推导阴影的方法。此外,与 GeoWizard 和 DSINE 相比,该模型生成的人类法线贴图质量更高。

更多研究细节,可参考原论文。
本文仅做学术分享,如有侵权,请联系删文。


3D视觉交流群,成立啦!
目前我们已经建立了3D视觉方向多个社群,包括
2D计算机视觉
、
最前沿
、
工业3D视觉
、
SLAM
、
自动驾驶
、
三维重建
、
无人机
等方向,细分群包括:
工业3D视觉
:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM
:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶
:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建
:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机
:四旋翼建模、无人机飞控等
2D计算机视觉
:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
最前沿
:具身智能、大模型、Mamba、扩散模型、图像/视频生成等
除了这些,还有
求职
、
硬件选型
、
视觉产品落地、产品、行业新闻
等交流群
添加小助理: cv3d001,备注:
研究方向+学校/公司+昵称
(如
3D点云+清华+小草莓
), 拉你入群。
 ▲长按扫码添加助理:cv3d001
▲长按扫码添加助理:cv3d001
3D视觉工坊知识星球










