
作者简介:

孙召增
金山集团 网络经理
从事IT运维十多载,酷爱运维开发的云时代网络布道者,熟练应用 Zabbix、ELK Stack 等开源运维产品,善于与企业运维管理结合进行二次开发;熟悉 Python 编程,主导开发了 ITNM 网络可视化管理平台。
1、前言
我从毕业以后一直在企业里面做 IT 支持,经历这么多年,有一些有感而发,我后面的每一个 PPT,其实都是我的一些深思熟虑,然后给大家交流一些真正的干货。
2、金山剪影
先给大家介绍一下金山,大家听到这个名字首先想到的是 WPS,我们上学的时候就知道 WPS 做办公很好用。

除了金山办公,WPS 这个公司现在还有三个子公司,一个是猎豹移动,主要是做手机端的工具开发,是在美国纳斯达克上市的。还有一个是西山居,玩游戏的朋友都知道这个公司,做了很多漂亮的游戏,不管是 PC 端还是游戏端的,《剑侠》系列的,还有是云服务的金山云。
猎豹移动最新数据统计,月活是6亿多,我们手机端用的一些软件,大家都知道,比如清理大师,驱动精灵,还有评测软件。
西山居游戏《剑侠》系列的手游和 PC 端游戏,都非常有名。
金山云主要是细分领域在视频和游戏,做得非常棒。外面我刚才看了,也有我们团队的一些展台,大家感兴趣的可以去了解一下。

金山办公,这是月活也达到两亿多,这也是最新的数据。详细的大家可以从官网看一些信息。
3、APM缘起与目的
我们说企业里面网络运维为什么要做APM呢?其实是偏系统运维这块,实际上企业各个分支都可以做这件事情,大家知道做IT俗称是IT消防员。

这两张图大家都不陌生,哪里出了火情,我们都要拿着电脑到机房拍照,最后累得满头大汗,这种情况相信大家都经历过,我也经历过。出现这种问题怎么办?

在最初的时候没有什么手段,遇到问题就措手不及,无从下手,和系统运维人员也好,业务人员也好,互相推责任,他说是你的责任,你说是他的责任,这个问题最终怎么办?
最终还是运维人员背锅,大家都体会过。为什么会出现这种状况?
我自己的分析是,我们的运维没有拿出一些东西来,没有拿出有利证据说服别人,是不是我的问题,是不是你的问题,在没有数据支持的情况下,造成互相推诿的局面,最后老板往往把责任推到运维,运维不力,最后上线的工作都是运维的工作。
3.1 解构IT基础设施架构
在一个企业里面,不管是传统企业,还是互联网企业,都有这么一个基础架构。最下面一层是环境监控这些基础设施,再往上一层是网络平台,包括各种交换机、路由器、VPN 设备、无线等等。

在网络系统之上支撑的就是企业应用,这里有各种的应用系统,ERP、OA等系统,还有运营,还有员工有的桌面,电脑、打印机、复印机,都是跑在网络上。
我想这个基础架构对于每个企业来说大同小异,我们运维人员从底层到最上面,都是我们要保障的对象,要做好的事情。那么怎么做好这件事情呢?我觉得要从两方面着手。
第一,我们做好这件事情要有一个指标,要确定一个标准,这个标准每个企业不一样,但是对于我们实际情况来说,应该设计怎样的标准体系。有了这个标准,大家有一个衡量的基线,然后我们再不断优化这个标准,就能用一些流程来衡量,这也方便在绩效里体现我们做得好不好。
第二,这里面还要有一个很好的运维平台,把运维平台做出来让大家能够看到这些东西。我们通过运维平台去实现标准,要有手段去达到这样的指标,保证我们的体系是完整的。
标准和平台这里面坑这么多,我们从哪方面开始着手呢?通常大家根据思维惯性更多是从运维系统着手,要保证它的可靠性、稳定性、连接性。但是往往忽略一方面,系统是跑在网络上面了,如果网络环境不好的话,我的用户环境再好,体验也是差的。
所以我们做的基础是保障这条路畅通,本文里大部分的东西都是围绕网络系统这块如何做 APM,以及怎么把它做好。
3.2 探寻IT运维的痛点

IT运维的痛点是什么,我们运维基础设施这么多,种类又多,随着年限增长,设备越来越老化,老化故障率就会增加,这是基础设施的特点。
但是运维人员碰到这些问题,你没有好的手段,预判力就比较低,当然看到问题,我们只是看到问题表象,想找到它的根本原因往往很难。
3.3 明确IT运维的目标
我觉得在运维的方向,根据我们的实际情况初步设计了三个阶段。
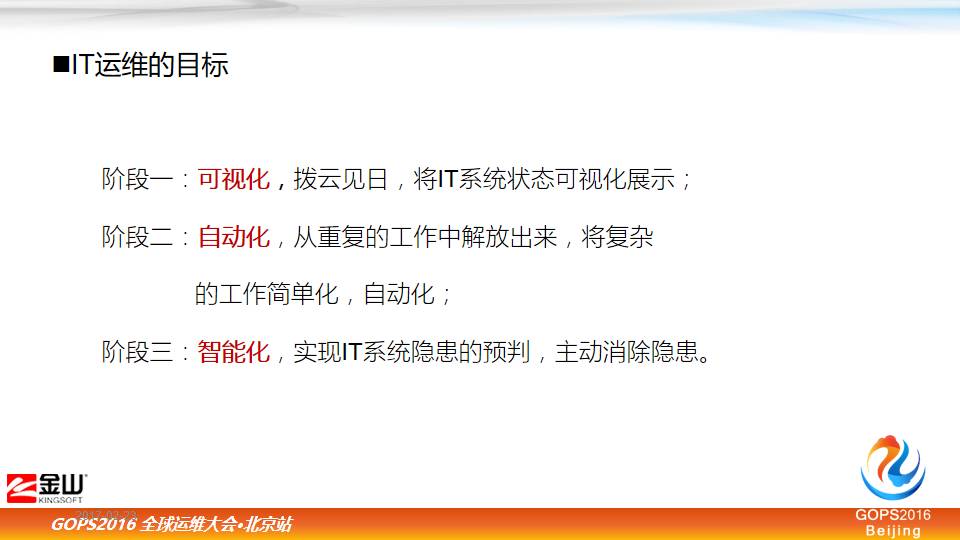
第一阶段可视化
我们对现有网络的系统,不管是交换机、路由器,这些IT设备底运行怎么样,要把它做到从可视化角度一目了然,不只是我们做技术人员能够对它很清楚,用户也能够看出来它是怎样的,现实中业务不可用时,用户看不到背后的原因,出现问题他就会说是不是网络的问题,所以可视化之后,我们可以做到拨云见日。
第二阶段自动化
日常工作当中,天天重复的事情,怎么变成自动化,让我们闲下来多做一些思考性的事情,所以第二阶段我认为是自动化,工作越来越简单。
第三阶段是智能化。
实现IT系统隐患的预判,主动消除隐患。
4、APM成果初现
4.1 实现洞察DDOS攻击

在此给大家做一些成果的分享,我们第一阶段做完可视化之后达到什么效果,看这张片子是 DDos 攻击的例子,这是11月份外网对我们防火墙的扫描,虽然这个扫描不是很多,才500多次。
它的攻击行为我们完全从后台日志记录下来,进行了随时可以看到它的大概数量,来自哪里,都是攻击我的哪些 IP,包括端口,后面还会和我们的 DDos 系统连接起来。
比如一分钟之后我的工具包达到一千或者多少,然后告警告诉我们维护人员干预这件事情,不要等到防火墙破了以后网断了,大家上不去网,这就做不到事前防控了。
4.2 可视化分析防火墙异常连接
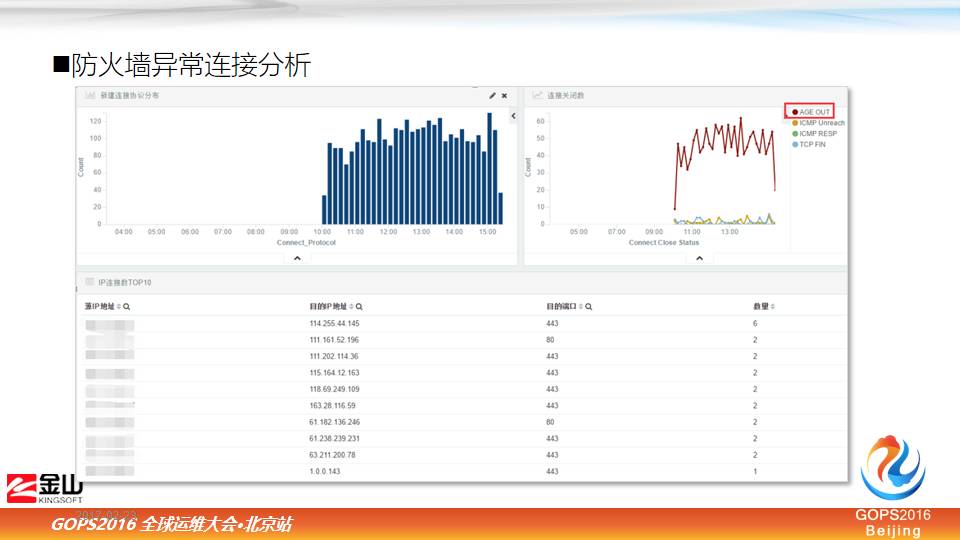
这个也是防火墙的连接,只不过不是来自外网,是来自内网,这个图是某一个IP,它上网的行为,通过它的上网数据分析,右上角的连接都是一些TCP的连接,右上角红线是超时的数量,看到这个时间段,大部分的 TCP 外网请求都是超时的,他做了哪些事情呢?
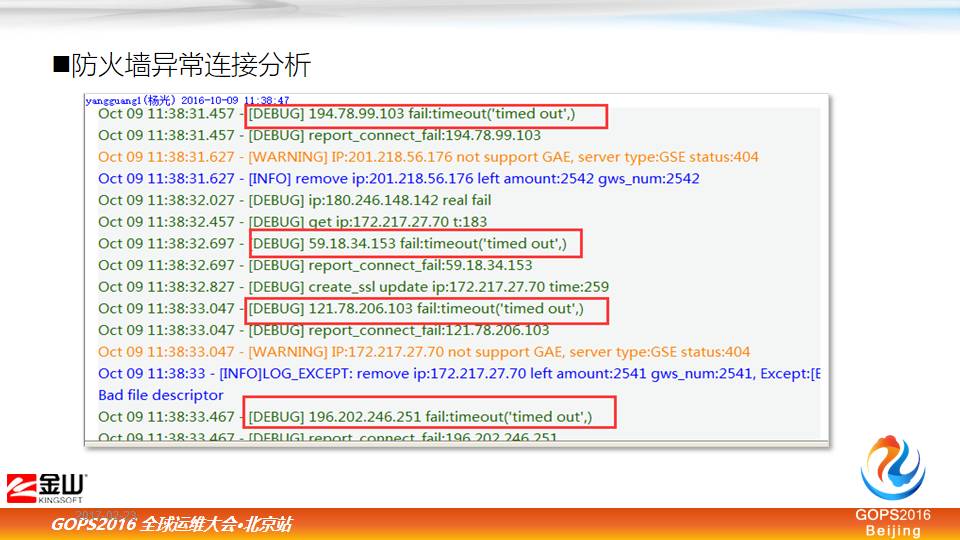
原地址是一个,后面还去了不同目的地,还有端口。通过下面的一些具体分析,确实它是这些地址都去超时了,超时才进行这样的连接,这样连接太多的话,会导致防火墙性能不能提供正常服务。
我们最后定位这个用户是用了免费 VPN 服务,去扫描一个海外的 VPN 资源,不停扫描,其实这些工具资源早就撤了,但是就是因为他一个人耗费了我们大量防火墙的资源。如果要不通过可视化追踪看的话,这些细微数据是看不到的,或者防火墙怎么挂了都不知道。
4.3 监控广域网质量评估稳定性
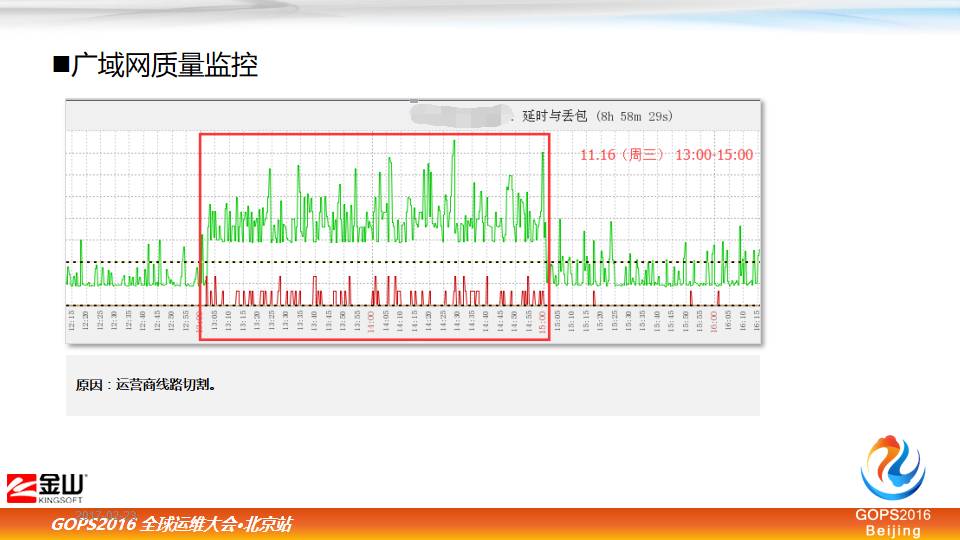
这张图是对广义网链路的监测,就是丢包率和延时的监控,这是我们租的某个运营商线路,在下午1-3点突然出现大量丢包,包括延迟会增大。
当然我们跑在上面的业务就非常缓慢了,我们事先发现这个问题,通知运营商。因为运营商原来做切割的时候,预案不足,导致出现问题。
像这样的数据我们干嘛呢,因为每年我们都会跟运营商签服务,服务里面都有条款,如果一个月内断了多长时间,都有赔偿的。所以拿这些数据,运营商不会说没有问题,不会推诿。
4.4 可视化分析无线用户掉线问题
下面我举两属于内网无线的例子,相信现在大家都部署了大量无线进行移动办公,移动办公过程中,用户对无线的依赖特别多,很重。
无线质量好与坏,在你日常的运维里面,占有很大的部分。图中是我们内部的掉线分析。
我们的掉线情况可以分为七种,其中比较多的有漫游掉线,还有未认证掉线。用户从一个 AP 切到另一个 AP 漫游的时候,肯定有重连接的过程,这是很正常的。
红线标注的是我们的未知错误,这是我们重点关注的,有两种原因,要么是终端的问题,要么是 AP 的问题。
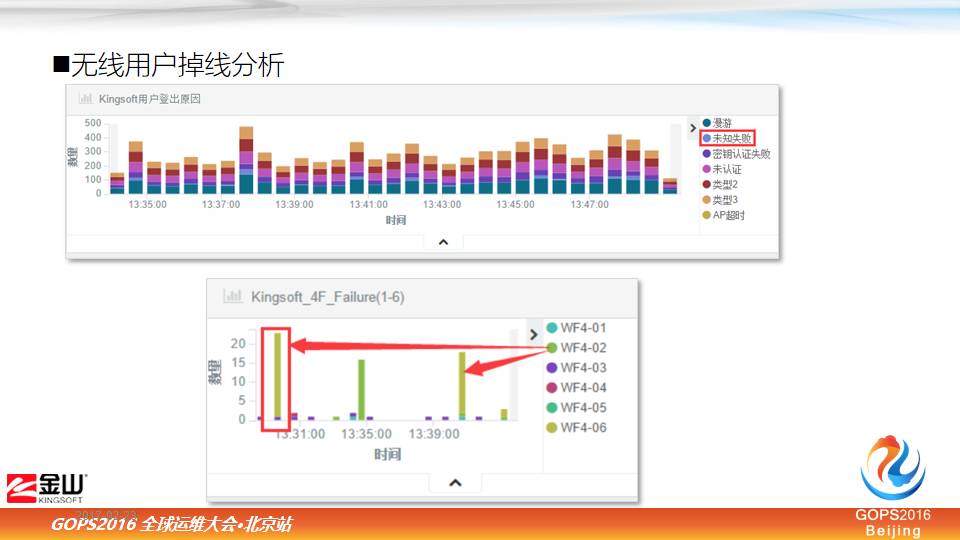
图中某个 AP 一天有几个时间段会掉线,几分钟内掉线次数达到20次左右,图中被红框标注的绿条表示某一个用户频繁掉线的次数。
事后我们看后台记录日志里面,有更详细的信息说明,通过两个红框可以看到,基本上定位是用户所在的位置,他的 AP 不稳定原因,后来我们把 AP 做了处理,这个问题就好了。
4.5 解决WIFI连接不稳定问题
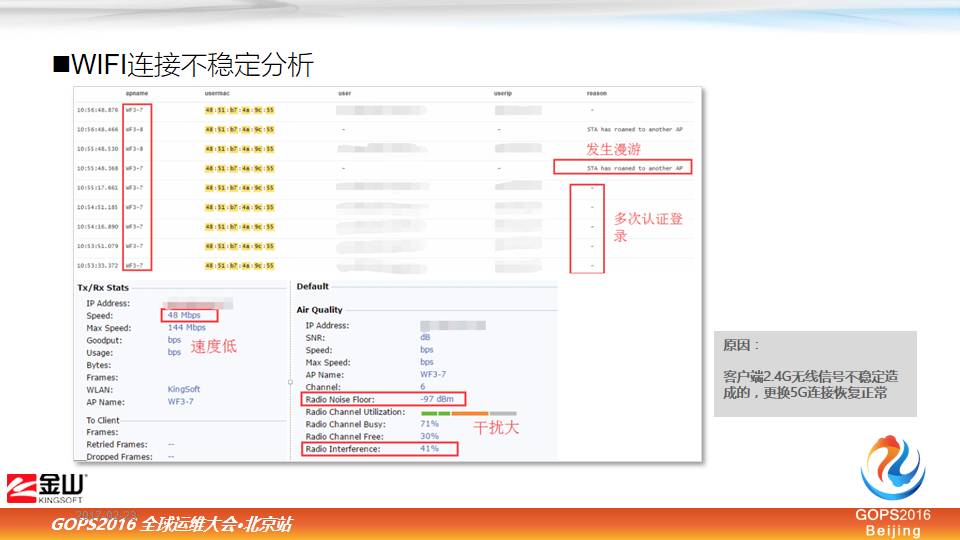
还有一个也是连接不稳定,不是掉线,不稳定第一个原因是漫游,漫游里面也有不正常的,就是频繁漫游。
这个用户没有动位置,就在他的办公桌面,一天都没动,后台看到它不停漫游,而且在周围几个 AP 来回切,我们从后台抓取数据来看,一个是接入速度低,二是干扰大,这个数据是用 2.4G 接入我们的网络,网卡也比较老,后来我们把它的终端升级到 5G 以后,这个问题就不存在了。
给大家分享一个经验,在大规模网络里面,如果设备部署得比较密集的话,终端最好用 5G 方式连接,因为 2.4G 信道比较少,受干扰还是比较大的。上面介绍的是通过简单可视化分析之后给我们带来的好处,我们做什么事情都一目了然。
5、APM的工具体系
我们当初做可视化工具选择的时候,经历的一些坑,也不叫坑,因为试了不少工具。

上面这两排都是做网络监控的工具,像 ZABBIX、Nagios、CACTI、MRTG 等等,他们都有各自不同的特点,下面是做日志分析的,这些工具都是开源社区里比较有名的,大家用得比较多的。
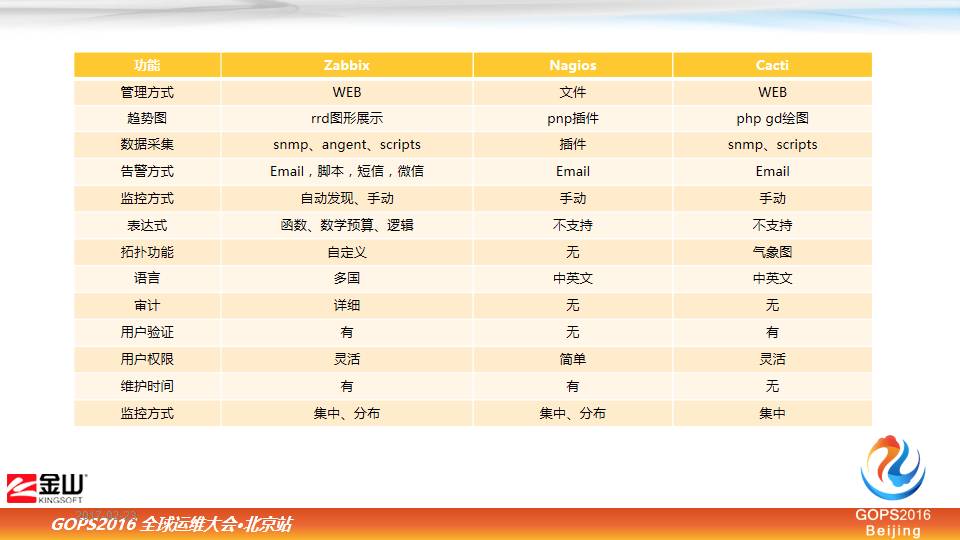
在选网络监控工具的时候,我们对比了一些平台,最终我们选用的是 ZABBIX,这里面我也罗列了一些优点和差异,ZABBIX 在告警方式我比较喜欢,简单,种类方式比较多,邮件也好,短信也好,包括微信互动也都可以实现。
另外拓扑功能,可以把整个 IT 资源串在一起,你关心的指标,比如流量延时、丢包,还有一些状态,都可以在这张图上呈现,包括线路连接的状态都可以呈现,而且支持中文和多国语言。部署方式非常灵活。
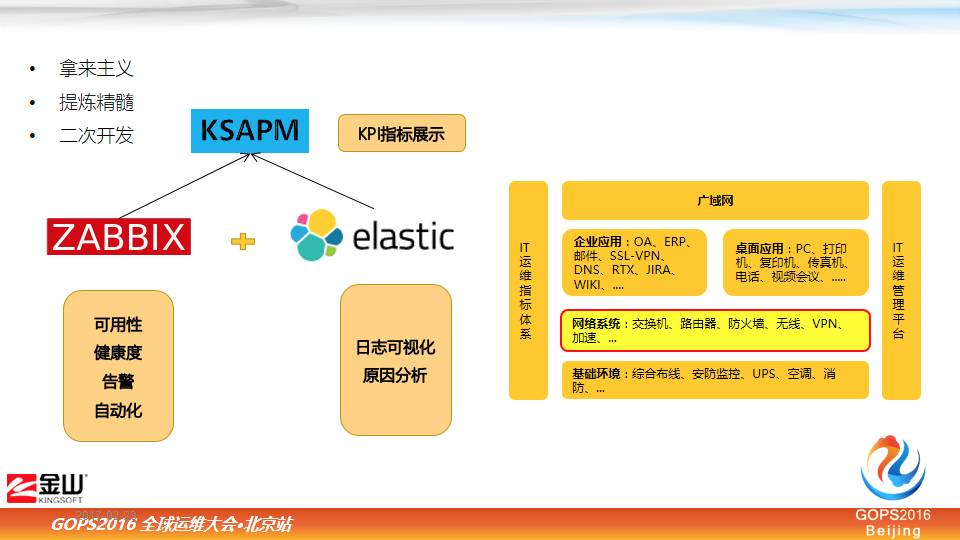
上面的这张图展示的是我们现在这个运维平台的简单运维架构,我们选择工具以后先拿来适用一下,看看它的特色到底适不适合我们,这些工具不一定适合其他朋友,可以做参考,如果找到适合他自己的,把里面你想用的东西提炼出来,不一定要用得多么全,只要你有用就好。
6、APM运维平台建立
我们尝试了一下做二次开发,为什么这么做呢?因为他提交的都是基本功能,你想要的或者想展示的可能不能完全展示,这里面我们做了二次开发就是做了 KPI 指标展示的平台。
用 ZABBIX 做可用性、健康性、告警、自动化,elastic主要集中在实时日志,通过可视化进行原因分析,在这两个工具之上,做到一个开放的平台,然后对我们的指标进行分析。
6.1 APM运维平台的架构设计
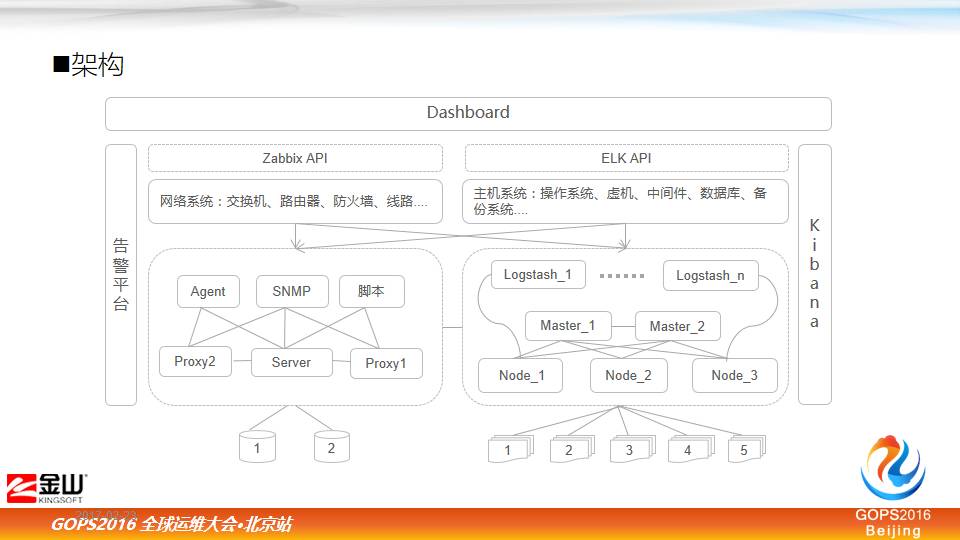
上面是我们的架构,ZABBIX 服务器是分布式或者独立部署,然后把数据抓取过来,进行展示。右边的 ELK 是做日志的,上面通过它的 API,我们做了一个 KPI 指标的展示,两侧相应的告警平台是通过 ZABBIX 实现,连接告警邮箱和短信、微信等等。
6.2 建立KPI指标体系
刚才说了很多 KPI 指标,也就是说我们要监控对象什么时候好,什么时候坏,我们指标体系怎么建,下面我主要说一下我的经验。
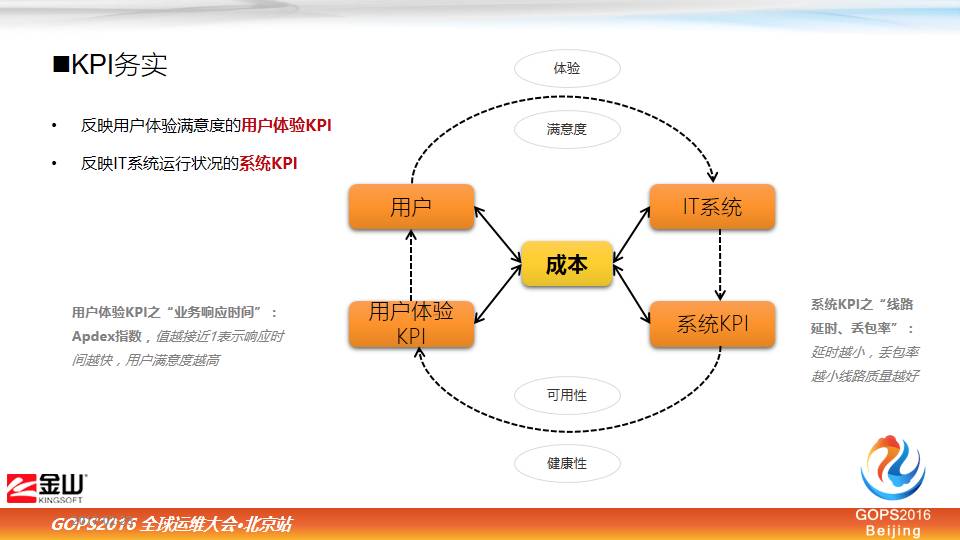
我们把 KPI 分成两类,一个是用户体验 KPI,这主要是对用户来说,你的系统好不好,他能够看得懂的指标。再一个指标是反映IT系统运行怎么样,我们叫系统 KPI。
这两个指标,围绕着我们的用户也好,还有 IT 系统也好,这是一个闭环的体系。
从用户角度来说,我们先从IT系统来说,我的IT系统要健康良好,怎么用系统 KPI,系统 KPI 好了以后,它的可用性、健康性直接体现到用户 KPI 指标,这个指标好的,自然用户会有很好的感受。
这些指标对于我们系统是能够反映出来的,但是企业里面IT其实是不受重视的,你的资源没有那么多,怎么在成本有限的情况下,把指标做好是问题的关键。
所以这里面也要运用我们的业务部门、用户部门或者领导也好,要把他们沟通好,在这样的情况下,我的指标这个阶段达到什么程度,咱们一步步来,步步为营。
在成本增加的情况下,我们把成本做得更漂亮一些,但是最开始的时候,我们基础环境没有那么好,大家不用把指标设得那么高,你肯定达不到,我们的指标要务实一点,不要为了指标而指标。
6.3 落地KPI指标实例
下面举几个例子,KPI 怎么落地?下面有两个例子
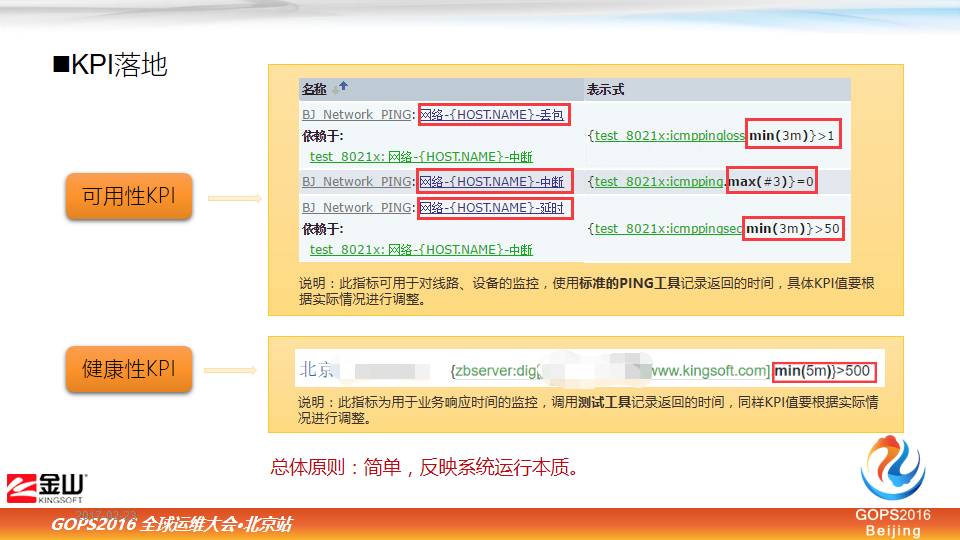
案例一,可用性指标的建立
比如网络好与坏,不管是网络也好,还是线路也好,可以用三个指标衡量,丢包、中断、延时,最重要的是中断,中断以后什么也不能用了。
中断指标比如我们设的是最大3分钟类连通性都是0,最大值都是0,说明线路就断了。在中断次之一点就是丢包,这个指标是三分钟类,最小丢包率大于1%,也就是说,最小值是1%,其他值肯定超过1%了。
延时指标是3分钟内延时值最小值大于50毫秒,这是我们设定的一个指标,当然这个值可能是根据不同情况要进行调整,比如说内网一般延时中几毫秒内。
案例二,健康性的指标的建立
主要是我们DNS解析响应时间,我们这里写了一个脚本解析,抓取里面的解析时间。我们设置的是五分钟内,最小值都超过500毫秒,就认为解析值很缓慢了。
总体来说我们设置的值都很简单,但可以反映当前系统运行情况是怎么样的。
案例三,如何评估KPI指标
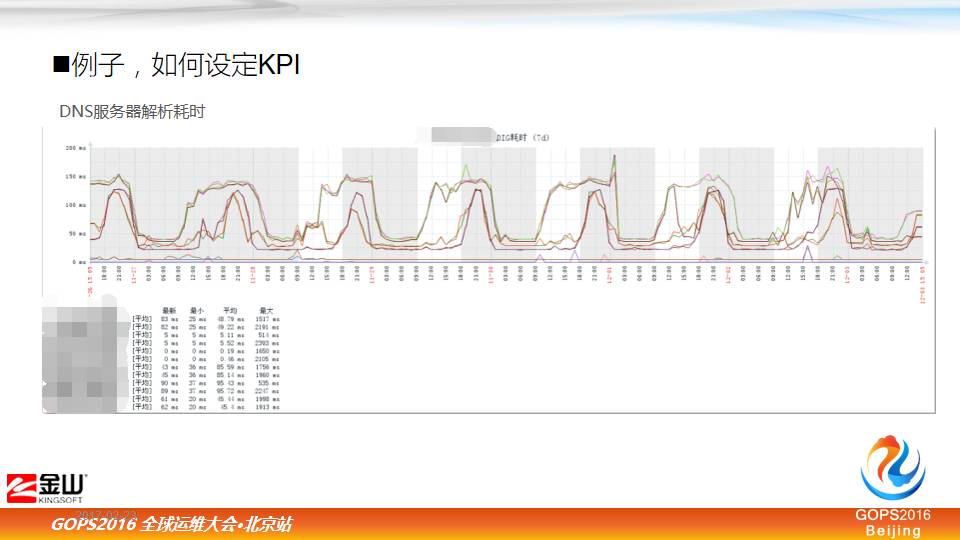
刚才说了两个指标,那怎么确定你的值是合适的,我们开始设计一个根据你自己的经验和感觉设置一个值,长时间下来以后,通过一段时间分析,比如我们这个图是对 DNS 解析时间的值设定,为什么设置500?
我们正常情况下,我们连续检测一周时间,发现我们解析的正常值都是小于200毫秒,所以我们在这个基础上又提高一点把阈值设定为500毫秒,这样系统就会认为超500毫秒肯定不可以了。
当然有时候偶尔会超过1000毫秒依旧正常的情况,但是从整体上来看,都是在200毫秒以下,这是正常情况。通过这样历史数据的积累,我们再去优化调节 KPI 指标。
这样就比较贴近于你的系统,当前情况下应该用什么质量来衡量,你也可以跟你的主管说,我们现在系统下能够达到的水平是什么情况,你如果想提高你的指标,做得更好,这时候你就可以要一些资源了,把带宽加大,提高设备硬件性能等。
案例四,KPI展示
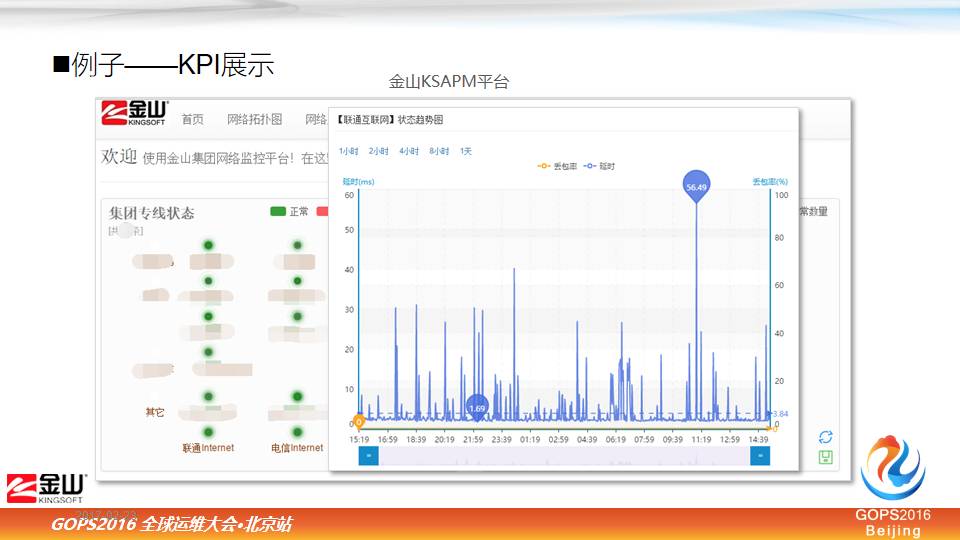
最后是一个 KPI 展示,我们IT做支撑服务,对于我们用户也好,对于我们业务部门也好,你要让他看得到把用这个系统好不好。
你以前做得再漂亮,他看不到,出了问题他认为你还是没有做好。所以这个平台就是我们给大家展示,通过这样的展示之后,用户就对我们的系统运行情况就很清楚了。
我选了一个对我们线路状态的监测,绿色正常,红色中断,黄色丢包,蓝色是延时。对每个线路,我还可以继续点击,在里面再去看线路历史的情况,这个线路例子是联通线路一天的数据,线路质量还是不错的。

有了上面这些手段,实现之后,对于我们自己,对于用户来说,都是很轻松了,我们每天上班之后看一些异常,到底什么原因发生的,看一些后台日志,然后看看服务什么原因,剩下时间就可以坐下来喝喝水,研究下一步怎么优化,出现问题怎么去做,这时候就很悠闲了,所以运维就变得很轻松了。
7、运维工作周报
什么要写运维工作周报这件事情?这是我们运维团队,其实做这件事情不是我一个人做,后面有一个团队支撑我们完成这件事。
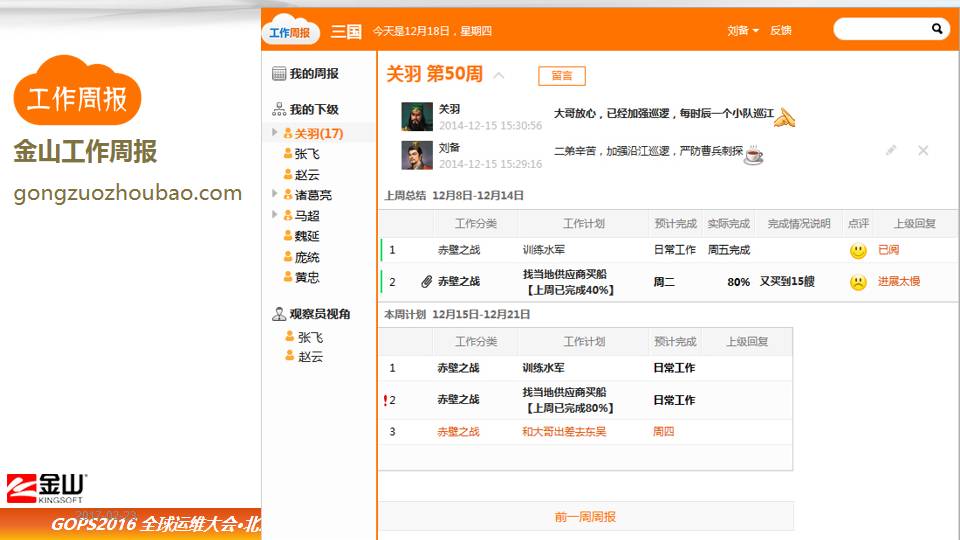
现在在移动互联网时代下,大家不可能一个人做出很复杂的东西来,需要每个人去贡献他一份力量。我们每周会有团队的例会,在例会上我们有一个工具,就是用我们的工作周报来完成工作上衔接的事情的安排。
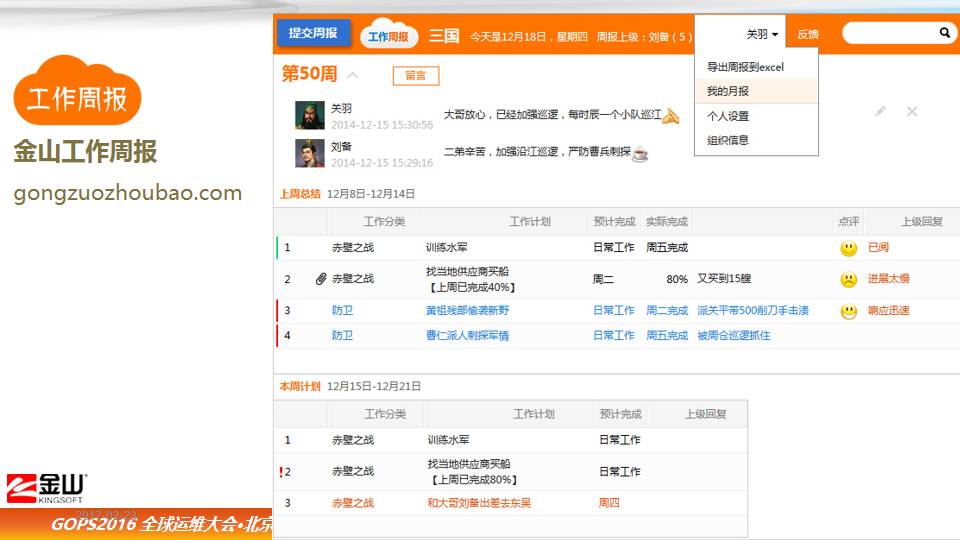
这个周报只是给大家看一个例子,这是我们每个人可以看到的,作为每周的计划,完成的怎么样,还有下周的计划,上周的总结。
上面这些黑体字部分,就是我上周制定的计划,我这周完成的怎么样,蓝色的部分是原来没有计划类的,又临时来的一些事情,我把它记录上面了。包括下面是下周的计划,要做什么事情,为什么要写在这个上面,一个是怕忘,事前多了,就怕忘记。
第二个目的,准确性,我们在沟通上,每个人表达和理解是不一样的,你可以表达张三那个意思,李四这个意思,但是我们落在这个平台上,大家就很清楚你要做什么事情,需要配合做什么事情。
近期好文:
《京东大促备战思路2.0大揭秘》
《阿里大规模计算平台的自动化、精细化运维之路》
《这些工具都没用过?还谈什么DevOps》
《重磅!揭开Qunar棱镜系统的秘密》
《DevOps前世今生之DevOps编年史》
GOPS · 深圳站,运维人的职业转折点

GOPS,让运维人从此闪亮
会议地点:南山区圣淘沙酒店(翡翠店)
会议时间:2017年4月21日-22日
您可点击“阅读原文”,享受特惠折扣购票





