原文地址:http://www.jianshu.com/p/940cf43778e9
作者简书:文质彬彬,专注数据分析与自我管理 数据圈圈友 已授权
为了了解图书馆咨询群的聊天情况,更好的了解学生情况,我对从3月份到目前图书馆咨询群的聊天记录进行了个初步的分析。对未来图书馆群管理做一个简单的建议。全篇分为三个步骤:
# 首先,是数据准备和整理library(stringr)library(plyr)library(lubridate)library(ggplot2)library(reshape2)library(igraph)
# 下载QQ群聊天记录txt
root = "/Users/zhangyi/Desktop/"file = paste(root, "QQ2(427968708).txt", sep="") file.data file, what = "", sep="\n", encoding="UTF-8")
data time=c(),text=c())time text

file.data
我们需要先将其格式分为用户、时间和文本内容三个简单部分,以便后续进行分析。
# 遍历所有的有效数据for(i in 3:length(file.data)){
reg.time "[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]+:[0-9]+:[0-9]+", file.data[i]) if(reg.time==1){ data data, data.frame(time=time,user.name=user.name,text=text)) text time;end time+attr(reg.time, "match.length")-1
time data[i], begin, end)
begin as.numeric(reg.time+attr(reg.time, "match.length")+1);
end data[i])
user.name data[i], begin,end)
}else{ text text,file.data[i])
}
}
# 去掉NAfor(i in 1:dim(data)[1]) if(is.na(data[i,1]))
{ if(is.na(data[i,2]))
{ if(is.na(data[i,3]))
{ datadata[-i,]
}
}
}
# 转换格式data$text as.character(data$text)data$user.name as.character(data$user.name)

转换前

转换后

data-文本高级分析
user.name name) texttext.numfor(i in 1:length(user.name)){ text.i text[which(data$user.name==user.name[i])] text.i.num length(text.i) for(j in 1:text.i.num){ text[i]text[i],text.i[j],sep="")
} text.num[i]text.i.num
}
user.text name=user.name,text=text,text.num=text.num)
user.text$user.name as.character(user.text$user.name)
user.text$text as.character(user.text$text)

user.text-各个用户的发言合并以及条目
# 非文本处理newdata,主要用来进行基础分析
# 将字符串中的日期和时间划分为不同变量
temp1 ' ')
result1 'date','clock')#分离年月日
temp2 '-')
result2 'year','month','day')# 分离小时分钟
temp3 ':')
result3 'hour','minutes','second')# 合并数据
newdata

newdata-没用星期数据
# 提取星期数据newdata$wday newdata$date)# 转换数据格式newdata$month newdata$month) )newdata$year newdata$year)newdata$day newdata$day))newdata$hour newdata$hour))newdata$wday newdata$wday)

newdata
# 非文本基础分析# 一星期中每天合计的聊天记录次数,可以看到该 QQ 群的聊天兴致随星期的分布。qplot(wday,data=newdata,geom='bar')

周内分布
很明显的可以看到周三的发言数量是最多的,而周一周二显然比较低迷。同时,周四和周日的也不错。
#聊天兴致在一天中的分布。qplot(hour,data=newdata,geom='bar')

一天分布
早上十点和下午五点六点是聊天高峰期,晚上十点也相对鼻尖活跃。到了十一点后基本就没人了。
#前十大发言最多用户&话痨user as.data.frame(table(newdata$user.name)) # 用 table 统计频数user Freq,decreasing=T),]user[1:10,] # 显示前十大发言人的 ID 和 发言次数topuser 1:10,]$Var1 # 存前十大发言人的 IDuser_hl data$user.name user_hl.n as.data.frame(table(user_hl))user_hl.n.20 2],decreasing=T),]user_hl.n.20 .20[1:20,]ggplot(data=user_hl.n.20,aes(x=user_hl,y=Freq))+
geom_bar(stat='identity')+coord_flip()+
theme(text = element_text(family = 'STKaiti'))#coord_flip()的作用就是讲条形图这些这样90度的旋转。

话痨1

话痨2
# 根据活跃天数统计前十大活跃用户
# 活跃天数计算# 将数据展开为宽表,每一行为用户,每一列为日期,对应数值为发言次数
flat.day 'date')
flat.mat as.matrix(flat.day[-1]) #转为矩阵# 转为0-1值,以观察是否活跃
flat.mat 0,1,0)# 根据上线天数求和
topday 1],apply(flat.mat,1,sum))
names(topday) 'id','days')
topday 1:10,]

活跃天数
online.day day[,-1],sum) tempdf time=ymd(names(online.day)),online.day )
qplot(x=time,y=online.day ,ymin=0,ymax=online.day ,data=tempdf,geom='linerange')
names(which(online.day>200))

每天活跃度-聊天次数
# 每天活跃人数统计# 根据flat.day数据观察每天活跃用户变化# numday为每天发言人数numday 2,sum)tempdf data.frame(time=ymd(names(numday)),numday)qplot(x=time,y=numday,ymin=0,ymax=numday,data=tempdf,geom='linerange')
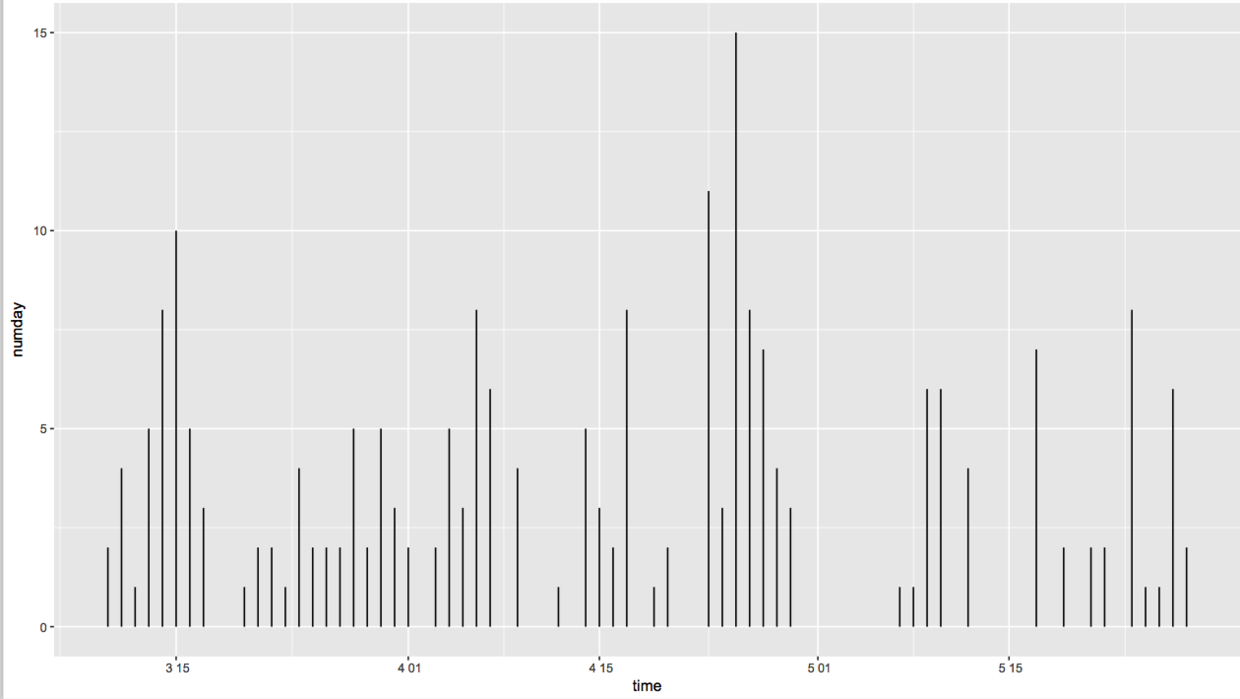
每天活跃人数
四月好像有一天特别活跃。。。
flat.hour name~hour,length,value.var='hour',subset=.(user.name %in% topuser)) hour.melt name,color=user.name))+theme_bw()+theme(legend.position = "none")
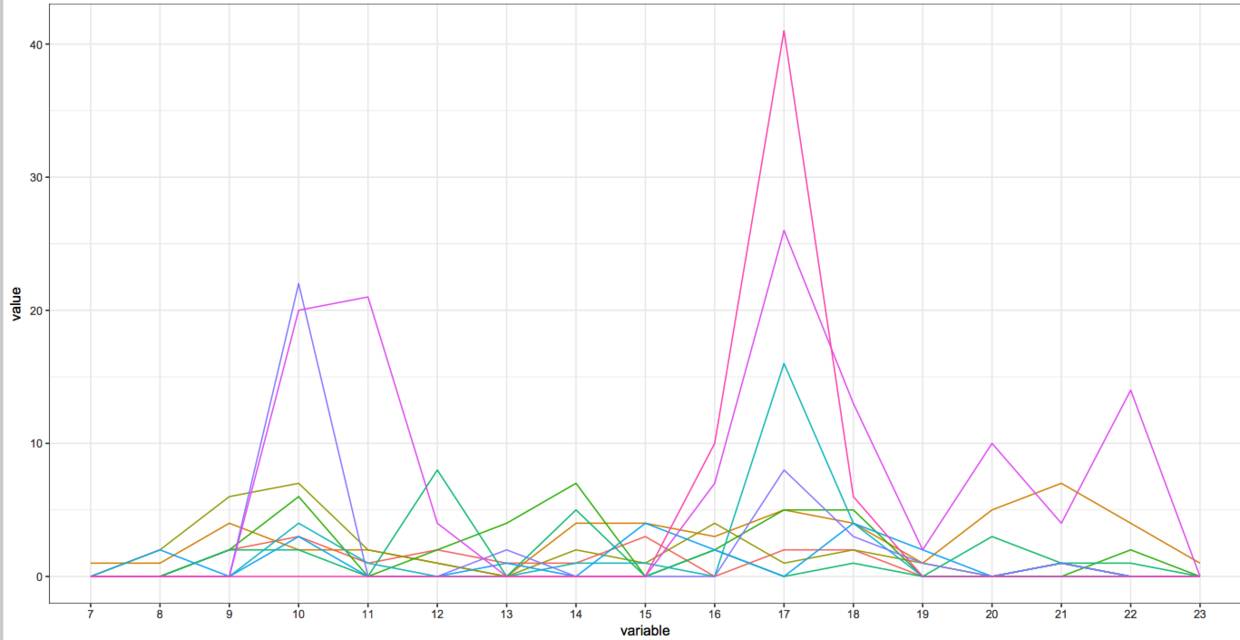
各有千秋
# 连续对话的次数,以三十分钟为间隔newdata$realtime newdata$time,'%Y-%m-%d %H:%M')# 时间排序有问题,按时间重排数据newdata2 newdata[order(newdata$realtime),]# 将数据按讨论来分组group 1,dim(newdata2)[1])for (i in 2:dim(newdata2)[1]) {
d newdata2$realtime[i], newdata2$realtime[i-1],
units='mins'))
if ( d < 30) {
group[i] -1]
}
else {group[i] -1]+1}
}
barplot(table(group))
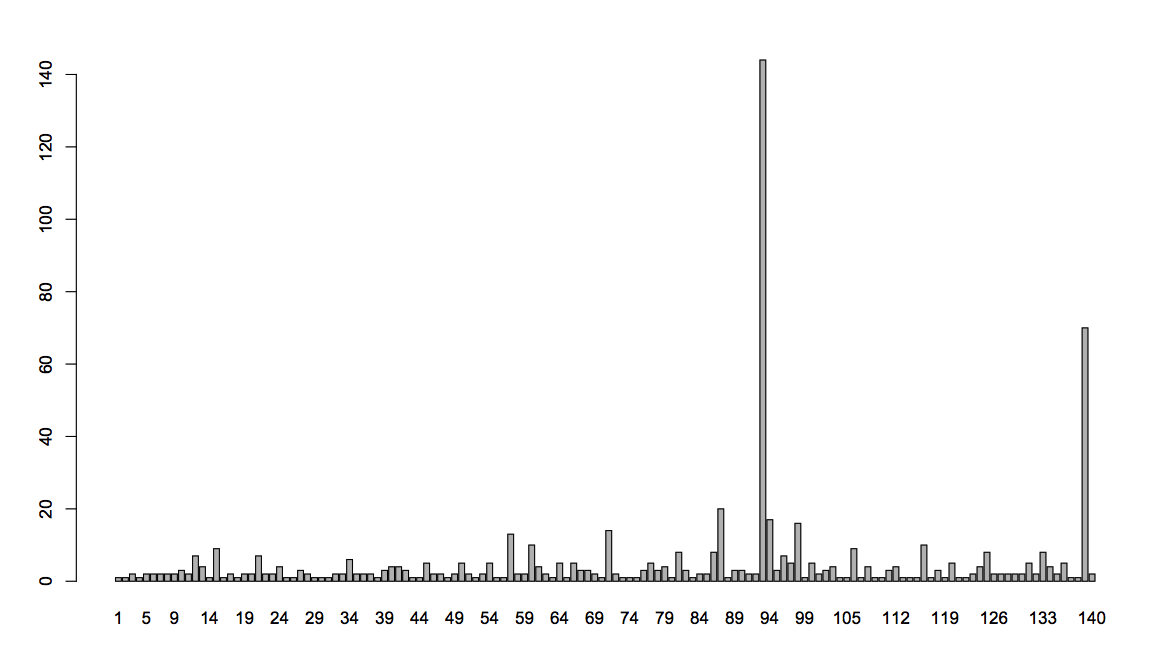
连续对话的次数
看来也就那一天多了。
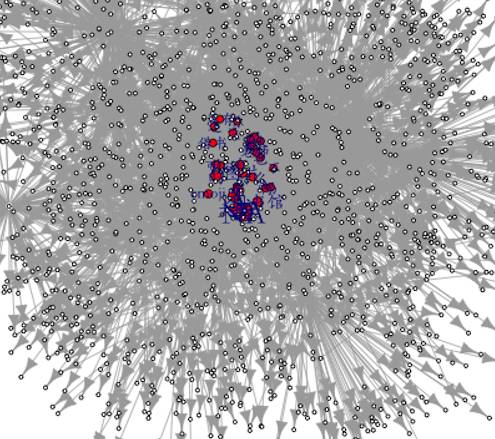
# 画社交网络图
# 得到 93 多组对话
newdata2$group group# igraph进行十强之间的网络分析
# 建立关系矩阵,如果两个用户同时在一次群讨论中出现,则计数+1
newdata3 sum,value.var='group',subset=.(user.name %in% user[1:10,]$Var1))#
newdata4 0, 1, 0)
rownames(newdata4) diag(diag(relmatrix))which(deldiag==max(deldiag),arr.ind=T)# 根据关系矩阵画社交网络画g graph.adjacency(deldiag,weighted=T,mode='undirected')g g)
V(g)$labelg)$degreeg)
layout1 g)#
egam E(g)$weight/max(E(g)$weight)
egam log(E(g)$weight)+1) / max(log(E(g)$weight)+1) +
V(g)$label.cex g)$degree / max(V(g)$degree)+
V(g)$label.color g)$frame.color E(g)$width E(g)$color plot(g, layout=layout1,vertex.label.family="STKaiti")

社交图
# 找到配对
# 找到配对
pairlist=data.frame(pair=1:length(attributes(deldiag)$dimnames[[1]]))
rownames(pairlist)[[1]]for(i in(1:length(deldiag[1,]))){
pairlist[i,1]1]
}
pairlist
pairmatrix=data.frame(pairA=1:length(attributes(deldiag)$dimnames[[1]]),pairB=1:length(attributes(deldiag)$dimnames[[1]]))
pairmatrix=data.frame(pair=1:length(attributes(deldiag)$dimnames[[1]]))for(i in (1:dim(deldiag)[1])){
deldiag[i,] 1, 0)
}
deldiag
library(jiebaR)
cutterfor(i in 1:length(user.text$text)){
jiebatext list(cutter <= user.text$text[i]))
}library(wordcloud2)
library(dplyr)
target_words as.data.frame(table(unlist(target_words)))%>%
arrange(desc(Freq))
wordcloud2(p)

词云
大家都挺喜欢图片和表情的。把的、0等词删除后再看:
# 删除词target_words=gsub(pattern="[的],[NA],[0]","",target_words);
q=as.data.frame(table(unlist(target_words)))%>%
arrange(desc(Freq))wordcloud2(q)

删除部分后
果然大家的关注点在图书馆上和借书上。“我”字比较多,看来大多是自我介绍。。。
# 散点图
library(tm)
ovid "图片", "表情"))
dtm as.matrix(dtm)
qq.freq 2,sum)
qq.freq.top1:30]
plot(qq.freq);text(c(1:length(qq.freq),qq.freq,names(qq.freq)))

词汇散点图
本该看到词汇的散点图,没想到词汇有点多。
from for(i in 1:length(user.text$user.name)){
from length(jiebatext[[i]])))
to"")] "数据及内无用户名"library(igraph)
init.igraph rem.multi=T){ labels union(unique(data[,1]),unique(data[,2]))
ids 1:length(labels);names(ids)labels
from 1]);to2]) edges matrix(c(ids[from],ids[to]),nc=2)
g vertices(g,length(labels))
V(g)$labels=labels
g edges(g,t(edges)) if(rem.multi){
E(g)$weight remove.multiple = TRUE, remove.loops = TRUE, edge.attr.comb = 'mean')
}
g
}
g.dir std.degree.words=10words.index "in") >= std.degree.words)
words "in")[words.index]
names(words) labelslabels=NAlabels[words.index] 1max.d max(words)min.d min(words)
V(g.dir)[words.index]$size = 2*(words-min.d)/(max.d-min.d)+2V(g.dir)$color = "white"V(g.dir)[words.index]$color = "red"#svg(filename=paste(root,"words.svg",sep=""), width = 40, height =40)
png(filename="sin3.png",width=800,height=800)
par(family='STKaiti')
plot(g.dir,layout=layout.fruchterman.reingold,
vertex.label=labels,
vertex.label.cex=V(g.dir)$size/2,
vertex.color=V(g.dir)$color,
vertex.label.family="STKaiti")
dev.off()
核心词汇
其中可以看到,除了NA外,借书,保存是常见的词汇,大家的问题也常集中在这上面。
# 核心用户网络图std.degree.user=20user.index "out") >= std.degree.user)
user "out")[user.index]
names(user) labelslabels=NAlabels[user.index] 1max.d max(user)min.d min(user)
V(g.dir)[user.index]$size = 2*(user-min.d)/(max.d-min.d)+2V(g.dir)$color = "white"V(g.dir)[user.index]$color = "green"png(filename="sin2.png",width=800,height=800)
par(family='STKaiti')
plot(g.dir,layout=layout.fruchterman.reingold,
vertex.label=labels,
vertex.label.cex=V(g.dir)$size/3,
vertex.color=V(g.dir)$color,
vertex.label.family="STKaiti",
vertex.label.color="blue")
dev.off()

用户散点图
总结
通过上述的分析,我们得到了以下结论:
最活跃的时间。通过最活跃的时间,我们可以知道群成员的活跃时间在周内的哪一天,在一天的哪个时间段。这样发布消息的时间就有了参考。
最活跃的人和话痨。通过最活跃的人,可以了解群核心成员。
活跃的人数。通过了解活跃的人数,可以间接了解群的活跃度。
社交网络。建立起社交网络,可以知道群中成员的互动关系。
词云。通过词云可以知道群内主要话题关键词。
重点词条网络。通过建立关键词网络,可以知道哪些话题带动了更多的用户参与。入度越大,说明该话题带动的了更多的用户参与讨论。
重点用户网络。而建立了重点用户网络,则可以了解哪些用户涉及的哪些关键话题词条。出度越大,表示该用户涉及的话题词条越多。
参考:
《R语言与网站分析》
仅用四行代码就可以挖掘你的QQ聊天记录
使用 R 语言挖掘 QQ 群聊天记录
今天来挖挖你的QQ聊天记录
欢迎加入数据君数据分析秘密组织(收费)

(保存图到手机相册,然后微信扫一扫可以才可以加入)
这是一份事业!
数据挖掘与大数据分析
(datakong)

传播数据|解读行业|技术前沿|案例分享
2013年新浪百强自媒体
2016年中国十大大数据影响平台
荣誉不重要,干货最实在









