原创:
许铁
混沌巡洋舰
4月19日
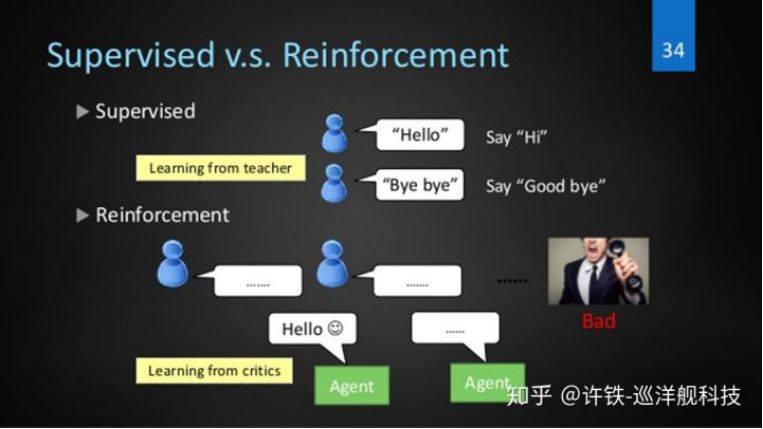
想像一下我们是人工智能体,我们有强化学习和监督学习可以选择,但干的事情是不一样的。
面对一只老虎的时候,如果只有监督学习就会反映出老虎两个字,但如果有强化学习就可以决定逃跑还是战斗,哪一个重要是非常明显的,因为在老虎面前你知道这是老虎是没有意义的,需要决定是不是要逃跑,所以要靠强化学习来决定你的行为。
强化学习有哪些实打实的应用呢?
只要在问题里包含了动态的决策与控制,
都可以用到强化学习
1, 制造业
强化学习之于制药业有一种天然的契合 , 把强化学习翻个牌子换个叫法, 也可以叫做控制论, 学习控制机器手的精确动作, 比如让它自动的做比目前所能及的更复杂的事情, 强化学习在制造业的应用潜力是显然的 。

2,
无人驾驶
这就不用多说了, 开车本质是个控制问题, 自动驾驶不仅需要模拟人类行为, 还需要对前所未遇的情况进行决策, 这需要强化学习。
3,
智能交通
智能交通, 显然这里包含了非常多的决策与控制问题, 就拿目前的共享汽车行业 ,滴滴和uber的派单系统时时都是一个动态的决策, 如何把正确的司机和乘客连接在一起, 如何让车辆调动到需求量最大的地方, 这些都要时时的考虑各种因素调整决策。我们说这里面既包含了效率的问题, 也包含了乘客的安全。比如这一次滴滴的事故如果修正强化学习的效用函数, 是有可能避免的。当然除了派单和调动问题, 在每个十字路口交通灯的控制等, 整个城市里的立体交通网络的协调, 本质都是强化学习问题, 所以强化学习在智能交通大有可为 。
4,
金融
金融的核心, 交易, 是一个动态控制问题, 即使你不能完全预测明天股市的涨跌, 你依然需要直到我今天要不要下单,下多少单, 这,就是一个强化学习的决策, 它可以影响明天的股市, 也会在非常长远的时间里让我收益或亏损。机器交易,本质是个强化学习问题。当然,金融里能够应用强化学习的绝不仅仅这一个。
5, 智能客服
智能客服本质是个强化学习问题, 如果你把它处理成监督学习问题, 那个对话机器人只能照猫画虎, 不能够真正从顾客的好恶的角度出发来发言, 而如果用强化学习, 那么机器人学习的就是如何正确的决策, 每句话都是为了最终讨得顾客欢心。
6, 电商
电商的本事是如何吸引人买更多的东西, 因此我们买了一个东西后它总会在下面给我们推荐其它的东西。然后我们看到了一个新的东西, 又会点开下一个连接, 这样一步步的就买了一大堆东西, 这样在每一步给你展示不同东西吸引你上钩的过程, 也可以看作是电商系统的动态决策过程, 是一个强化学习问题。
7, 艺术创作
艺术创作领域看起来与强化学习无关, 事实上它可以很灵活的把人类的好恶加在强化学习的过程里,通过强化学习, 机器作曲可以自发的得到取悦于人的风格,也就是范式。
让机器来决策,首先体现在如何模仿人类的决策。对于决策这个问题,
我们来看人类决策都要解决哪些难题。
强化学习最初的体现就是试错学习, 因此理解强化学习的第一个层次就是如何通过一个简单的机制在不确定的环境下进行试错, 掌握有用的信息。

在这个框架下,
我们需要掌握的只有两个基本要素,
一个是行为,一个是奖励。
在这个级别的强化学习,
就是通过奖励,强化正确的行为
。
所谓行为,行为的定义是有限的选项里选以恶搞,
所谓智能体的
决策
,走哪一个都有正确的可能,但是我们预先不知道这个东西。
所谓奖励, 就是环境在智能体作出一个行为后, 给它的反馈。
大家看到,如果这个奖励是已知的,那么也就没有了任何的游戏需要进行的可能了。
你为什么要学?
每个行为得到的后果是不知道的啊!
奖励具有随机性,
同样的条件性,
有的时候我们可以得到奖励,
有时候没有,
因此,
它也是一个随机变量,
理解这一点非常重要,
因此才可以理解很多的后面的算法。
奖励可以是正向的,也可以是负向的(惩罚)。

我们迅速的切入一个强化学习的最小实用例子,
又被称为
多臂赌博机的例子
:
你去赌场玩的,
都知道这个机器的存在,
它的构造就是很多个长得一样的摇臂,每个对应不同的中奖概率,
你要玩
N轮, 每次选择摇臂, 使得最终的收益最大。聪明的你一定可以设计一个方案, 让自己的收益最大, 怎么做呢?
首先, 你能不能一下子找到这里的行为和奖励是什么呢?
你能否设计一个算法解决这个问题呢?首先, 注意, 我此处的题设是N。假定这个N是一次你会怎么做?10次呢?无穷多次呢?
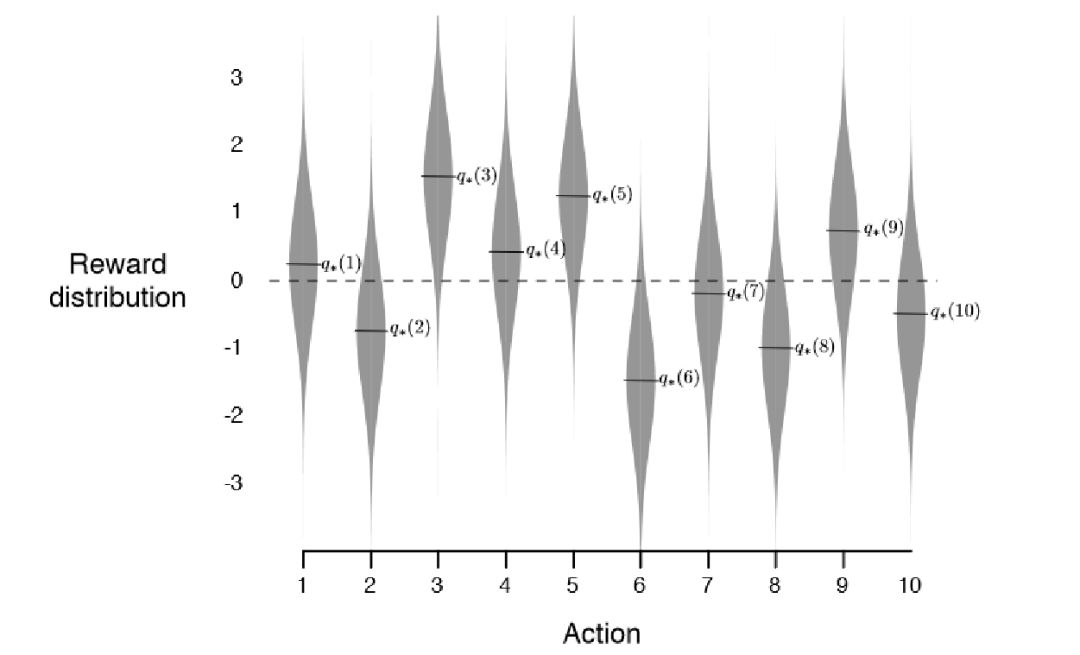
每次行动后带来不同的奖励
很自然的,我们就来到了这么一个问题,就是探索与收益的平衡,
只要
N不是1或无穷, 你都会有如下的窘境。假如你开始就中了 , 你会一直选择那个中奖的摇臂不放过吗?显然这可能是陷阱,因为还有收益更高的臂,或者只是这次的运气好。
反过来, 你会不停的随机试下去吗?显然不会, 因为存在收益比较高的臂。所以, 你就需要设计一个策略, 在有效探索的同时加大在那个最有收益可能的臂的概率, 每次玩, 又都增加你的信息。这就是一个极为典型的应对不确定的策略。
而且,
可以直接用到产品设计上,
我们也可以把它看成一个特别有方向性的试错。
在这里你要形成的第一个观点就是:
奖励是随机变量 为了量化奖励, 我们需要引入期望。
这,才是我们要优化的对象。我们所处的环境下,环境给我们的奖励分布是未知的,因此,你必须在一开始边测量, 边引入收益的机制。
刚刚的游戏,
和真实世界的大多数问题相差甚远,
因为它每轮只有一步就可以看到奖励,而且这一次抽取,
和下一次抽取一点关联都没有。
而事实上世界上的大部分游戏是一个连续多步骤,步步相连的过程。比如各种棋类,扫地机器人(连续离散化)等,
这样的问题,
很快前面的问题就不管用了。我们需要完善我们的框架来改进前面的东西。
好了,假定你是在设计这个东西,
那么你要加入一个什么要素呢?
时间?
步骤
?
No,
我们说, 解决这类问题, 首先引入的是状态。在围棋里, 你需要看到的是每一步其实你需要决策的信息都在当时的棋盘布局里,
而在扫地的游戏里, 每一步的信息都在当下的位置里, 也就是说, 我们把这些某个时间步骤出现的所有有用信息或特征叫做一个状态。有了这个概念, 多步游戏就可以看成根据状态来决策的游戏。
那么, 现在我所有的元素就是行为-状态-奖励,每一步, 我都要根据过去和当时的状态来决策此刻。
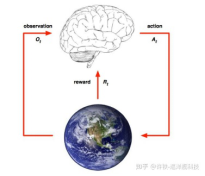
这样我们就有
state(observation)- action - reward 这样的一个组合。或者说环境给你一个state, 然后智能体得到一个action , 这个action改变环境, 并且环境返回智能体一个reward,如此循环, 当然在真实的游戏下我们并没有这样机械的一步步的过程, 而是一个连续的整体, 这种机械的方法是为了让问题可以轻松的被一个程序解决。
这样的思路和图灵最早提出的图灵机智能模型具有异曲同工之妙, 而图灵机被认为是智能产生的基本模型,因此你也可以理解为什么强化学习和强人工智能有关。
从状态到行为
action的函数,也就是刚刚提到的那个条件概率, 通常称之为
策略
,
犹如通常意义上说的战略,
也就是一个行为的指导方案。
当游戏结束的时候,
我们把所有环境给我们的奖励加在一起算分,
越好的策略得到的分数越高,
这就是强化学习的本质。
TD学习
那么如何得到一个好的策略呢?这就是强化学习的中心问题, 大家以看就知道这本质上还是一个优化问题。那么整个后面的篇章都围绕这个展开。
如何得到好的策略?在上个游戏里, 游戏没有很多步,而是一步就可以拿到奖励,这个游戏里, 游戏有很多步, 这里必然引入的一个基本问题就是, 如果我还有好多步才得到奖励, 那么根据奖励来强化学习,将是一个极为困难的事, 因为我今天的决策只能影响明天, 但是明天什么结果都看不到, 这将是一个十分令人绝望的事。因为还学习个什么啊, 没有奖励就没有强化。
你能否结合自己的生活设立一个解决方法呢?
想想我们高中三年,都是为了高考,
但是我们其实中间有无数小目标啊,
比如各种期末考,期中考。再看金融的一个例子,如果你是一个潜力股,
你是可以在你得到最终的结果前贷到款的对吧?
也就是说,
虽然明天并没有任何实际的奖励,
我们可以引入一个虚构的量,它能够把未来的收益给量化,这就是价值函数。它代表的不是当下的收益,而是未来的收益。
这里就有一个问题了,
如果这个奖励在一个月以后到达,
或者在一年之后到达,
这两种情况是否应该一视同仁呢?你可以以你的直观感受直接告诉我,
不可能的!
我们可以有一个心理学实验,就是马上给你
50元和, 和一年后给你100元, 你愿意选择哪一个(举手)。好了, 这样的机制事实上有着非常强大的现实意义。它的隐含含义就是, 我们需要一个贴现因子, 来惩罚未来的收益。
在大多数情况下,
我们都生活在这样一种情况里,
我们的游戏里有小的奖励有大的奖励,
有今天的奖励有明天的奖励,
而游戏是连续的。
比如扫地机器人,
你可以想象成每扫一小块,
它就得到一个奖励,
这个时候价值函数将变成一个不同时间点的奖励的求和。
那么,
你有没有发现,
这个贴现因子本身更深刻的含义
?
你能用它解释艰苦忍耐的人生观和即使享乐的人生观吗
?
平衡当下和未来, 建立当下和未来的桥梁,正是强化学习的第二个基本矛盾。也因为如此,当下和未来收益的统一者,价值函数就成为了强化学习的核心概念。这个函数的定义方法是首先把当下的奖励和未来的奖励加在一起, 由于奖励本身就是随机变量且未来是不确定的, 我们要是把奖励都加在一起, 依然得到的是一个随机变量, 你要衡量一个随机变量的大小, 只能对它取期望。这样, 这个带着未来收益的期望, 就是我们对价值函数的最终定义。强化学习, 就变成了如何找到那么一个策略, 使得我们这个value函数达到最优。
然后我们来说,
强化学习的核心,
策略。
所谓策略,
无非是把当下的这个对未来的估值,
我们也可以看作趋势,
和我们要的行动联系起来。
我们干脆把可能的行动也放在这个价值的条件里面去,
也就是,
我们定义目前每个行动下的值函数,
给它起个酷炫的名字,叫
action value, 每个行动的价值。我问你, 如果我有了这个函数, 该如何求得策略?
如果你告诉我这无非是找那个最高估值对应的行动,
恭喜你答对了。
你已经掌握了强化学习的精髓,
我们需要强化(选择)的行动,
就是那个使得整个走势,
也就是值函数最高的行动啊!
但是,同时我要告诉你没有完全答对。
为什么?
有没有同学能发现我刚刚的逻辑漏洞?
如果你告诉我老师,
哪里来的值函数,
你怎么算出来的,
就是非常聪明。
刚刚讲了这么多,
我实际上是偷懒了啊,
我讲的都是一堆定义,
实际怎么操作却一点没讲。
你记得我说的,
我们求的是期望,就需要概率。
这个概率,
就是我的行为,
引起环境如何的改变的概率,
但是,
正如我们在赌博机里不知道每个臂的筹码,
这里我们也不会知道环境给我们反馈的概率。
对于这个问题的解决,
一个是笨办法,
一个是聪明办法。
所谓笨办法,
就是不停的去实验,
从当下的状态和行为出发,
试它一万次测个平均,
所谓蒙特卡洛。
这个方法有着一个致命的弊病
,那就是你得等到游戏的结束才能更新一次
v值,速度太慢了,而且想想有些时候你只能进行一次或几次游戏, 比如人生的游戏你只有一次, 你不能死了再回来, 所以这个方法就不那么给力了。怎么办呢?
然后我们看聪明方法,这个办法就是不等到游戏结束就更新。这个思维有点逆向。也就是你假定游戏已经结束了, 你从终局往回看整个游戏, 假定游戏结束的时候有一个终极的奖励刺激。这个时候, 你能马上更新的v函数一定是那个你离终局最近的状态。而如果你已经更新了这个状态, 那么它之前的那个状态呢?请你想一下, 我可不可以接着更新这个状态?当然, 我离终点奖励差两步, 所以我无非是把终点奖励乘以两次贴现。哦, 这样看可以, 同样的方法, 你可以不可以更新前三步, 前四步, 前5部, 前n步的状态?
那么下一次游戏呢?
我是否还需要等到游戏的终局再更新呢?
No!在新的游戏里, 如果你走走走, 恰好达到了上次游戏里某个经过的状态, 你立刻会看到, 这里已经标记过了一个估值,
你可以怎么做?
Ok, 你可以利用这个估值, 并用它来更新你之前的一步!
因为你可以假定当你到大了这里,
一切的情景都是有过往经验支撑了,
如同你在一个城市里走走走,
误打误撞到了昨天走过的一条小路,
那么从这里,
一切都变成已知。
这个方法翻译成数学语言就是
TD时间差分学习。
数学上的表现就是估值函数v的迭代表达式, 你每次格按照v的迭代式定义来更新v函数,这样多步之后v也会趋于正确的值。好比当你在开车的时候, 你险些撞车, 游戏没有终止, 但是足以让你使用这个惊险来更新值函数。另外一个例子是你打公交车去上班, 每过一个站你看一个时间, 看和你的预计是否有差别, 这每一站的时间, 足以让你不停的调整对最终实现时间的预期。
我们看看这个故事背后的生物学故事。
所谓的时间差分,
正是条件反射的基础。
你记得巴甫洛夫的狗吗?
摇铃和食物有什么关系?
食物就是我们说的终极的奖赏,
而终极奖赏之前,
摇铃是一个中间步骤,
由于大量的经历里,
摇铃都导致了食物,
所以,
狗就会学会,
摇铃就是那个终极奖赏前的状态,因此,
摇铃也应该得到一个更高的值函数。
这时候,
摇铃也就具有了某种奖励的性质,可以引起狗的流口水了。
因此你可以继续往前推,
你是否看到,
摇铃前还可以放置一个灯光,灯光之前还可以放一个声音呢?
你是否看到了,
如果人生赢家是抱得美人归,
那之前的高考长夜,
之前的寒窗苦读,
之前的所有一切,
是不是都成为了我们趋之若鹜的奖励。
TD学习, 是所有生物行为学习的基础。
你可不可以用它的原理设计一个控制拖延症的方法呢?
有了
TD学习, 我们可以随时更新每个状态下所有可能行为对应的值函数, 这样, 我们就可以选择那个当下估值最高的选项来行动, 所谓策略的更新(比起之前的估值下的行动)。
当然,
由于我们每次更新的时候,
我们仅仅是比之前多了一点信息,我们的这个值函数依然是不完美的,
幸运的是,
每个行为最终都导致我们进入一个新的状态,
使得我们进一步的获得了上一个状态的信息,从而进一步的优化我们的值函数,
若干论之后,
我们将会得到一个最优的值函数和策略。这样的迭代过程,
值函数的更新紧跟着一个行为,
如同一组拉丁舞曲。这个算法就是大名鼎鼎的
salsa和Q学习(此处不做区分
)的简化版。
这就是强化学习的第二个阶段。
然后我们来看强化学习的第三个阶段, 所谓用想象和世界模型来填补的阶段。
首先,
我们刚刚遗漏了一个重要的
point, 这个世界难道真的是如刚描述的只有几个有限的状态吗?肯定不是。我们真实生活的状态是无限的。那么,人脑是如何由有限战胜无限的?我们有联想,有想象。
这,也是强化学习的第三个阶段。
首先,我们引入估值函数的近似解法。









