第 5 节 复杂问题回答
这一节详细阐述如何回答复杂问题。首先第 5.1. 节将问题形式化为一个最优化问题。第 5.2. 节和第 5.3. 节分别阐述优化量度和算法。
5.1. 问题陈述
本节着重关注由一系列 BFQ 组成的复杂问题,例如表 1.1 中的问题 ○f 可以被分解为两个 BFQ:(1) BarackObama’swife (MichelleObama);(2) WhenwasMichelleObama born? (1964 年)。显然,第二个问题的答案依赖于第一个问题的答案。在解答复杂问题时,分而治之框架可以自然而然地被利用:(1) 系统首先把问题分解为一系列 BFQ,(2) 然后系统依次回答每个问题。既然在第 3 节已经给出了如何回答 BFQ,那么这一节中的关键步骤就是问题分解。
需要强调的是,在一个问题分解的序列中,除了第一个问题之外的每个问题都是一个具有实体变量的问题。只有当变量被指派到一个特定实体之后,问题序列中的问题才能被具体化,而这个特定实体也就是前一个问题的答案。回到之前的例子中去,第二个问题 When was Michelle Obama born? 在问题序列中是 When was $e born?。在这里,$e 作为一个变量来代表第一个问题 Barack Obama’s wife 答案。从而当给定一个复杂问题 q 后,系统需要将其分解为由 k 个问题形成的序列 A = (qˇi)ki=0,使得:
例 5.5 (问题序列)考虑表 1.1 中的问题 ○f 。 一个自然问题序列是 qˇ0 = Barack Obama’s wife 和 qˇ1 = when was $e1 born? 系统也可以替换任意一个子串来构造问题序列,诸如 qˇ′0 =Barack Obama’s wife born 和 qˇ′1=When was $e?。但因为 qˇ′0 既不是一个可回答的问题也不是一个 BFQ,所以后者是无效的。
给定一个复杂问题,系统用递归的方式构造一个问题序列。系统首先用一个实体变量来替换一个子串。如果这个子串是可以被直接回答的 BFQ,使它为 q0。否则对子串重复以上步骤直到得到一个 BFQ 或者子串是一个单独的词汇。然而,正如例 5.5 所示,许多问题分解是不可行的(或不可回答的)。因此,系统需要度量一个分解的序列有多大可能被回答。更形式化地,使 A(q) 成为 q 所有分解可能的集合。对于一个分解 A ∈ A(q),规定 P(A) 为 A 是有效(可回答)问题序列的概率。从而问题被简化为:

接下来的第 5.2. 节和第 5.3. 节将分别阐述对 P(A) 的估计以及如何有效求解最优化问题。
5.2. 度量标准
根据直觉,如果问题序列 A = (qˇi)ki=0 中的每个问题 qˇi 都是有效的,那么该序列是有效的。因此,需要首先估计 P(qˇi)(qi 是有效的概率),然后将每个 P(qˇi) 合起来来计算 P(A)。
算法用 QA 语料库来估计 P(qˇi)。qˇ 是一个 BFQ。如果可以通过将 q 的一个子串替换为 $e 得到 qˇ,那么认为问题 q 与 qˇ 是匹配的。本节称匹配是有效的, 当被替换的子串是 q 中的实体时。例如 When was Michelle Obama born? 匹配 when was $e born? 和 when was$e?。但是,只有前者是有效的因为只有 Michelle Obama 是一个实体。本节用 fo(qˇ) 来表示 QA 语料库中匹配 qˇ 的所有问题的数量,用 fv(qˇ) 来表示有效匹配 qˇ 的问题数量。
fv(qˇi) 和 fo(qˇi) 都从 QA 语料库得到计数。这样算法估计 P(qˇi) 为:

这个式子明显是合理的:匹配数越多,qˇi 可回答的可能性越大。fo(qˇi) 被用来惩罚过于笼统的问题样式。下面给出一个 P(qˇi) 的例子。
例 5.6. 令 qˇ1 = When was $e born?,qˇ2 = When was $e?,QA 语料库如表 5.2 所示。显然,q1 满足 qˇ1 和 qˇ2 的样式。但是,因为只有当 q1 匹配 qˇ1 时,被替换的子串才对应一个有效实体“Barack Obama”,因此只有 q1 是 qˇ1 的有效样式。从而得到 fv(qˇ1) = fo(qˇ1) = fo(qˇ2) = 2。且有 qˇ0 ≡ 0。由式 5.26, P(qˇ1) = 1, P(qˇ2) = 0。
对于每个给定的 P(qˇi),定义 P(A)。假设 A 中的每个 qˇi 有效是独立事件。则当且仅当问题序列 A 中所有 qˇi 有效时,该序列有效。所以 P(A) 可以计算如下:

5.3. 算法
给定 P(A),算法的目标是找到使 P(A) 最大的问题序列。因为搜索空间巨大,因此这步不能忽略。考虑一个长度也就是字数为 |q| 的复杂问题 q。q 中共有 O(|q|2) 个子串。如果 q 最终被分解为 k 个子问题,那么总搜索空间为 O(|q|2k),这是不能被接受的。本节提出一个基于动态规划的方法来求解最优化问题。该方法复杂度为复杂度为 O(|q|4)。方法利用了最优化问题的局部最优解性质。定理5.7证明了这个性质。
定理 5.7(局部最优解)对于复杂问题 q,令 A *(q) = (qˇ*0,...,qˇ*k) 是 q 的最优分解,则 ∀1≤ i ≤ k, ∃qi ⊂q, A *(qi) = (qˇ*0,..,qˇ*i ) 也是 qi 的最优分解。
基于定理5.7,可以得到一个动态规划(DP)算法。考虑 q 中的一个子问题 qi 是 (1) 一个初始 BFQ(不可分解)或(2)一个可被进一步分解的问题串中的其中一个。对于情形(1),A*(qi) 包括一个元素也就是 qi 本身。对于情形(2),A *(qi) = A *(qj) ⊕r(qi,qj),其中 qj ⊂qi 有最大 P(r(qi,qj))P(A *(qj)),r(qi,qj) 是通过将 qi 中的 qj 用一个占位符“$e”替换而生成的问题。从而得到动态规划方程:
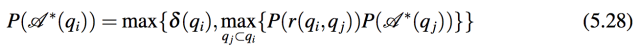
其中 δ(qi) 是决定 q1 是否为初始 BFQ 的指示函数。也就是说,当 qi 是初始 BFQ 或 δ(qi) =0 时,δ(qi)=1。
算法 2 描述了动态规划算法。算法在外层循环(第 1 行)中枚举 q 的所有子串。在每个循环中,算法首先初始化 A *(qi)和P(A *(qi))(第 2-4 行)。在内层循环中,算法枚举 qi 的所有子串 qj(第 5 行),然后更新 A *(qi) 与 P(A *(qi))(第 7-9 行)。注意到算法按照长度升序枚举所有 qi,这确保了通过每个被枚举的 qj,可以知道它们的 P(A *()) 和 A *()。
因为每个循环枚举 O(|q|2) 个子串,从而算法 2 的复杂度为 O(|q|4)。在实验的 QA 语料库中,超过 99% 的问题字数少于 23 个 (|q| < 23),因此这样的复杂度是可以接受的。

第 6 节 属性扩展
在知识图谱中,许多关系不是由一个直接属性表达的,而是由一条由许多属性组成的路径表示的。正如图 1.1 所示,在 RDF 数据库中,“spouse of”关系是由三个属性 marriage → person → name 表达的。本章称这些多属性的路径为扩展属性。利用扩展属性来回答问题可以高效提升 KBQA 的覆盖率。
定义 5.8(扩展属性)一个扩展属性 p+ 是一个属性序列 p+ = (p1,..., pk)。本章把 k 称为 p+ 的长度。如果存在一个宾语序列 s = (s1,s2,...,sk) 使得 ∀1 ≤ i < k,(si, pi,si+1) ∈ K 且 (sk, pk,o) ∈ K ,则说 p+ 连接了主语 s 和宾语 o。正如 (s, p,o) ∈ K 表示了 p 连接了 s 和 o,这里将 p+ 连接 s 和 o 记作 (s, p+,o) ∈ K 。
第3节中提出的KBQA模型可以充分适应属性拓的问题。系统只需要一些轻微的调整就可以使得KBQA对扩展属性有效。第6.1.节展示了这种调整。第6.2.节展示了如何 使得它对十亿级别的数据库有效。最后,第6.3.节中展示了如何选择一个合理的属性长度来保证最高的效率。
6.1. 对扩展属性的 KBQA
上文曾提到,对单一属性的 KBQA 由两大部分组成。在离线部分,系统计算对给定模板的属性分布 P(p|t);在线上部分,系统抽取问题的模板 t,然后通过 P(p|t) 计算它的属性。当把 p 替换成 p+ 之后,系统做了如下调整:
在离线部分,系统学习了对扩展属性的问题模板。例如计算 P(p+|t)。 P(p+|t) 的计算仅仅只要知道 (e, p+ , v) 是否在 K 中。如果系统生成了所有的 (e, p+ , v) ∈ K ,就可以计算这一存在性。第 6.2. 节展示了这一生成过程。
在线上部分,系统用扩展属性来回答问题。系统可以通过 RDF 数据库中的 e 到 p+ 来计算 P(v|e, p+)。例如,让 p+ = marriage → person → name,为了从图 1.1 中的数据库来计算 P(v|Barack Obama, p+),系统从节点 a 开始遍历,然后经过节点 b 和 c,最后得到了 P(Michelle Obama|Barack Obama, p+) = 1。
6.2. 扩展属性的生成
一个简单的生成所有的扩展属性的方式是对数据库中的每一个节点进行广度优先搜索(BFS)。然而,扩展属性的数量随着属性的长度指数级增长。所以当数据量达到十亿级别的时候,BFS 的开销是无法承受的。
为了实现扩展属性的生成,系统首先对属性的长度 k 设置了限制来提升延展性,也就是说,它只搜索长度小于等于 k 的扩展属性。下一个小节会展示如何得到一个合适的 k。本节通过另外两个方面来提升延展性:(1) s 的约减;(2) 内存高效的 BFS。
s 的约减:离线处理的过程只对在 QA 语料库中出现过至少一次的 s 有兴趣。因此,系统只用那些在 QA 语料库中的问题中出现过的宾语作为 BFS 的起始节点。这一策略很大程度上减少了生成的 (s, p+ , o) 的数量,因为这些实体的数量比起在十亿级别数据库中的要少得多。在系统使用的数据库(15 亿实体)和 QA 语料库(79 万不同实体)中,这一过滤策略理论上可以减少 (s, p+ , o) 的数量 1500/0.79 = 1899 倍。
内存高效的 BFS:为了在 1.1TB 大小的数据库中使用 BFS,本节使用了基于磁盘的多源 BFS 算法。在一开始,系统将在 QA 语料库(记作 S0)中出现过的所有的实体读取入内存,并在 S0 创建了一个散列索引。第一轮中,系统通过扫描磁盘上的所有 RDF 三元组一次,并将三元组的主语和 S0 结合,我们就得到了所有长度为 1 的 (s, p+,o)。本节建立的对 S0 的散列索引,允许算法在线性时间内完成这一操作。第二轮中,系统将所有的三元组读入进内存中,然后建立对所有的宾语 o 建立散列索引(记作 S1)。然后再次扫描 RDF,并将 RDF 中三元组的主语和 s ∈ S1 结合。现在系统得到所有的长度为 2 的 (s, p+,o),并将它们读入进内存中。系统重复上述的“索引+扫描+结合”操作 k 次来得到所有的长度为 p+.length ≤ k 的 (s, p+,o)。
这个算法非常高效,其时间消耗主要用在了 k 次扫描数据库上。散列索引的建立和结合的操作在内存中执行,时间消耗对于磁盘上的 I/O 来说是可以忽略不计的。注意到从 S0 开始的扩展属性的数量总是比数据库的大小要小得多,因此可以被容纳在内存中。对于实验使用的数据库(KBA,更多细节请参阅实验章节)和 QA 语料库,只需要存储 21M 的 (s, p+,o) 三元组。所以很容易将他们读入内存。假设 K 的大小是 |K |,算法找到的 (s, p+,o) 三元组的数量是 #spo,它消耗了 O(#spo) 的内存,算法的时间复杂度是 O(|K |+#spo)。
6.3. k 的选择
扩展属性的长度限制k影响了属性扩展的效率。k 越大,(s, p+,o) 越多,导致更高的答案覆盖率。然而,这也产生了更多的无意义的 (s, p+,o) 三元组。例如,图 1.1 中,扩展属性 marriage → person → dob 连接了“Barack Obama” 和 “1964”,但是他们明显没有关系,对于 KBQA 也没有用。
属性扩展需要选择一个能够得到最多的有意义的关系,并且排除最多无意义的关系的 k 的值。本文使用 Wikipedia 的 Infobox 估计最佳的 k。Infobox 存储了实体的一些知识,并且大部分条目都是以“主语- 属性-宾语”的三元组的形式存储的。Infobox 中的条目可以被视作有意义的关系。因此,k 的选择中首先列举一些长度为 k 的 (s, p+,o) 三元组,然后测试它们中有多少在 Infobox 中出现。选择过程希望看到 k 值的减少。
特别地,实验按照它们出现的频率的顺序,从 RDF 数据库中选择了前 17000 个实体。实体 e 出现的频率被定义为在 K 中存在的使得 e = s 的 (s, p, o) 三元组的数量。选取这些实体是因为他们有更多的知识,因此更值得信任。对于这些实体,使用第 6.2. 节中提出的 BFS 生成了他们的长度为 k 的 (s, p+,o) 三元组。然后,对于每一个 k,计算这些可以在 Wikipedia 的 Infobox 中找到对应的 (s, p+,o) 三元组的数量。更形式化地,假设 E 是作为例子的条目的集合,SPOk 是长度为 k 的 (s, p+,o) ∈ K 。定义 valid(k) 来度量 k 对于有意义的关系的数量,方法如下:
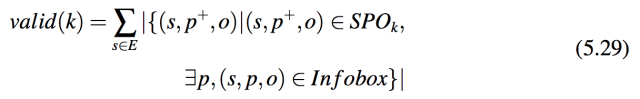
在 KBA 和 DBpedia 上得出的 valid(k) 的值在表 5.3 中展示。当 k = 3 时,有效的扩展属性的数量显著减少。这说明了大部分有意义的因素在这个长度内可以被表示出来,所以系统选择了 k = 3。
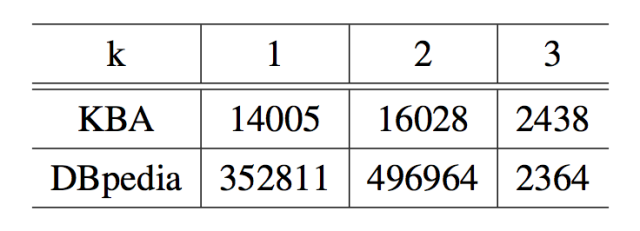
表 5.3: valid(k)
第 7 节 实验
第 7.1. 节中阐明实验设置;第 7.2. 节验证了概率模型的合理性;第 7.3. 节和第 7.4. 节中分别评估了系统的有效性和效率;第 7.5. 节验证了 KBQA 的三个组成部分的有效性。
7.1. 实验设置
KBQA 系统运行在在一台装配了 Intel Xeon CPU, 2.67 GHz, 2 processors, 24 cores, 96 GB 内存, 64 bit windows server 2008 R2 的服务器上。它使用 Trinity.RDF [110]作为 RDF 引擎,这一引擎被部署在了 6 台服务器上,并且一共使用了 284.1GB 的内存和 1.5TB 的磁盘资源。
数据库 实验部分使用了三个开放领域的 RDF 数据库。由于商用保密协议本文无法公开第一个数据库的名称,在这里称它为 KBA。KBA 有 15 亿实体和 115 亿 SPO 三元组,共占 1.1TB 空间。SPO 三元组包含了 2658 个不同的属性和 1003 种不同的种类。为了实验的再现性,实验也在其他两个知名的数据库 Freebase 和 DBpedia 上测试了 KBQA 系统。Freebase 包含 1.16 亿个条目和 29 亿 SPO 三元组,占了 380GB 存储空间。DBpedia 包含了 560 万条目,1.11 亿三元组,占了 14.2G 存储空间。
QA语料库 QA 语料库包含了从 Yahoo!Answer 上得到的 4100 万 QA 二元组。如果对于一个问题由多个回答,则只考虑“最佳答案”。
测试数据 实验在 QALD-5 [99],QALD-3 [96] 和 QALD-1 [95] 上分别测试了 KBQA,它们是测评基于知识图谱的问答系统设计的。这些测试数据的基本信息展示在了表 5.4 中。由于 KBQA 关注问答的 BFQ,所以也展示了对于这些数据库中 BFQ 问题的数量(#BF Q)。
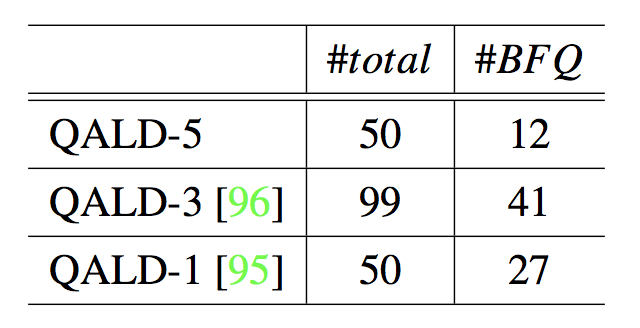
表 5.4:评估标准
对比方法 实验把 KBQA 和 13 个 QA 系统进行比较,表 5.5 列举了这些系统。
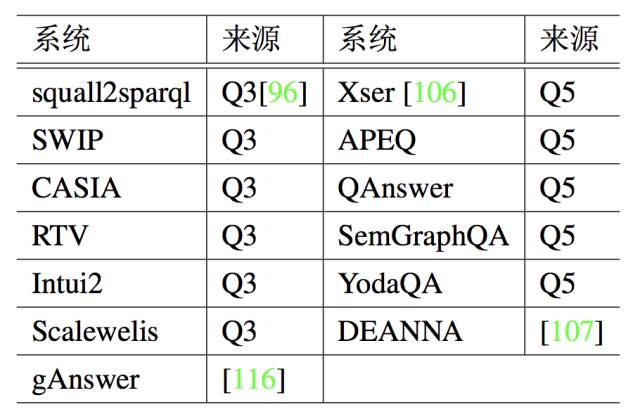
表 5.5:对比方法。 Q5 表示 QALD-5;Q3 表示 QALD-3
7.2. 概率模型的合理性
接下来实验解释为什么一个概率模型是必须的。在问题理解的每一个步骤中,有些选择会给系统的决策带来不确定性,在表 5.6 中展示了每一个决策的候选答案数量。这种不确定性需要系统使用一个好的概率模型来表示。
举例来说,P(t|e,q) 表示将一个问题和它的实体转化成模型的时候的不确定性。比如对问题 How long it Mississippi river? 来说,系统很难从一些候选项中直接决定这个实体的概念是 river 或是 location。

表 5.6:概率图模型中每个随机变量的不同取值个数
7.3. 有效性
为了评估 KBQA 的有效性,本节进行了如下实验。对于线上部分,实验评估了回答问题的准确性和召回率。在线下部分,实验评估了属性推断的覆盖率和准确性。
7.3.1. 问题回答的有效性
指标 当一个 QA 系统发现当前问题没有答案时,它可能会返回 null,所以实验对一 个 QA 系统返回的非空(不一定是正确答案)(#pro)的答案的数量和正确答案(#ri)的数量做了记录。然而,事实上,一个系统只能部分正确地回答一个问题(例如,仅仅找到正确答案的一部分)。因此实验评测也需要那些部分正确的答案(#par)的数量。当 KBQA 找到一个属性时,问题的答案便可以从 RDF 数据库中被找到。因此对于 KBQA 来说 #pro 是 KBQA 找到的属性的数量。#ri 是 KBQA 找到正确的属性的数量。#par 是 KBQA 找到部分正确的属性的数量。例如,对于问题 Which city was $person born? 来说,“place of birth”是一个部分正确属性。因为它可能返回一个国家或者一个村庄,而不是问题所要找的一个城市。
现在实验部分已经定义了评估指标:准确性 P,部分准确性 P*,召回率 R 和部分召回率 R*:
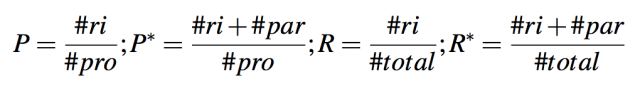
实验也对关于 BFQ 的召回率和部分召回率有兴趣,分别记作 RBF Q 和 R*BF Q:
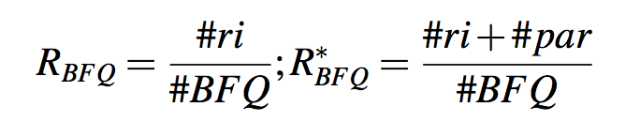
QALD-5 和 QALD-3 的结果 表 5.7 和表 5.8 中展示了结果。对于所有的竞争者,表格直接使用了它们论文中的结果,可以发现在所有的数据库上,除了在准确性上略逊于 squall2sparql,KBQA 战胜了其他所有的竞争者。这是为 squall2sparql 对于所有的问题都使用了真人来标注识别实体和属性。另外 KBQA 在 DBpedia 上表现的最好,这是因为 QALD 主要是为了 DBpedia 设计的。对于大多数 QALD 中的问题,KBQA 可以直接从 DBpedia 中找到正确的答案。
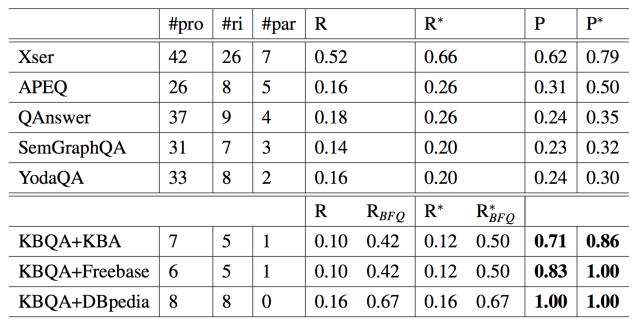
表 5.7:QALD-5 的结果
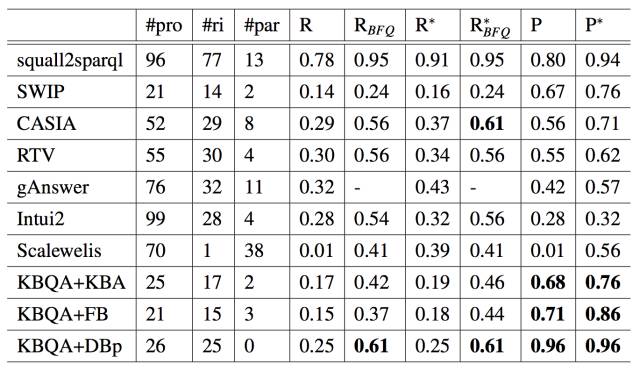
表 5.8:QALD-3 的结果
召回率分析 表 5.7 和表 5.8 中的结果表明了 KBQA 有一个相对低的召回率。主要原因是 KBQA 只回答 BFQ(二元事实性问题),然而 QALD 包含了很多非 BFQ 问题。当只考虑 BFQ 时,召回率分别上升至 0.67 和 0.61。实验对于 KBQA 在 QALD-3 上没有回答的问题进行了研究,结果发现原因很大程度上是因为 KBQA 对模型匹配用了相对严苛的标准。无法回答的情况通常发生在一个稀少的属性和一个稀少的问题进行了匹配时。15 个无法回答的情况中有 12 个是因为这个原因。例如,对于问题 In which military conflicts did Lawrence of Arabia participate?,在 DBpedia 中这个问题的属性是 battle。KBQA 对于这部分属性没有充分进行训练。如果将 KBQA 和一个同义词 QA 系统结合起来,可能就会有效增加召回率率。当 KBQA 中发生了误匹配时,系统可以用基于同义词的 QA 系统的答案作为替代。这超出了本章主要讨论的内容,因此不在这里进行阐释。
QALD-1的结果 实验将 KBQA 和 DEANNA 进行了比较, 结果列在了表 5.9 中。DEANNA 是基于同义词的 BFQ 问答系统。 对于 DEANNA 来说, #pro 是被转化成 SPARQL 的问题数量。 结果表明 KBQA 的准确性比 DEANNA 高得多。 由于 DEANA 是一个典型的基于同义词的 QA 系统, 这一结果表明了基于模板的问答系统在准确性方面比基于同义词的要好。
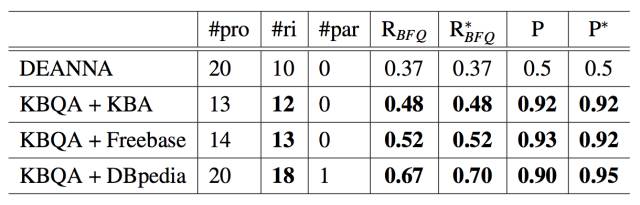
表 5.9:QALD-1 的结果
7.3.2. 属性推断的有效性
接着本节阐释 KBQA 属性推断的有效性:(1) KBQA 学习了大量的自然语言的问题的模板和属性(覆盖率),(2) 对大多数的模板,KBQA 可以推断出正确的属性(准确率)。
覆盖率 表 5.10 中展示了 KBQA 学习的模板和属性的数量,并与最新的基于同义词的 Bootstrapping [107, 97]进行了对比。Bootstrapping 从数据库和网络文本中对属性学习 了同义词(BOA 式样,主要是网络文本中主语和宾语之间的部分)。BOA 可以被看做是一种模板,它们之间的关系可以被看做是属性。
结果表明,即使 Bootstrapping 用了更大的语料库,KBQA 依然比它找到了明显更多的模板和属性。这意味着 KBQA 在属性推断方面更有效:(1) 模板的数量确保了 KBQA 对不同问题的理解;(2) 属性的数量确保了 KBQA 对于不同关系的理解。因为 KBA 是实验使用的最大的数据库,基于 KBA 的 KBQA 生成了数量最多的模板,所以在接下来的实验中主要关注对 KBA 的测试。
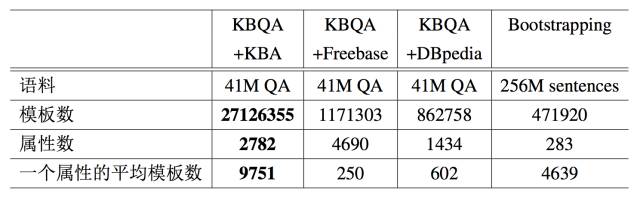
表 5.10:属性推断的覆盖率
准确性 此评测的目标是评估对于一个给定的模板,KBQA 是否能生成正确的属性。为了这个目的,实验按照出现频率选择了最高的 100 个模板。实验也随机选择了 100 个频率大于 1(只出现一次的模板可能意义十分模糊)的模板。对于每一个模板 t,使用人工核对它的属性 p(最大值化 P(p|t))是否正确。和 QALD-3 上的评估相似,在某些情况下属性是部分正确的。结果被展示在了表 5.11 中。对于两个模板集,KBQA 都有更高的准确率。对于频率最高的 100 个模板,KBQA 的准确率甚至达到了 100%。这表明了基于模板的属性推断的质量。
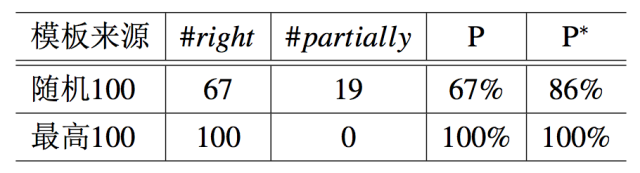
表 5.11:属性推断的准确率
7.4. 效率
本节首先给出和其他问答系统的运行时间比较,然后给出 KBQA 的时间复杂度分析。
运行时间实验 运行时间由两部分组成:线下与线上。线下的处理过程,主要是学习模板, 用了 1438 分钟。 时间的消耗主要是由庞大的数据量造成的:十亿级别的数据库和上百万的 QA 对。 鉴于线下部分只用运行一次, 这个时间的消耗是可以承受的。 线上部分主要负责回答问题, 实验把线上部分的时间消耗在表 5.12 中和 gAswer 和 DEANNA 进行了比较。 KBQA 用了 79ms,比 gAnswer 快了 13 倍,比 DEANNA 快了 98 倍,这意味着 KBQA 可以有效地支持实时的 QA。
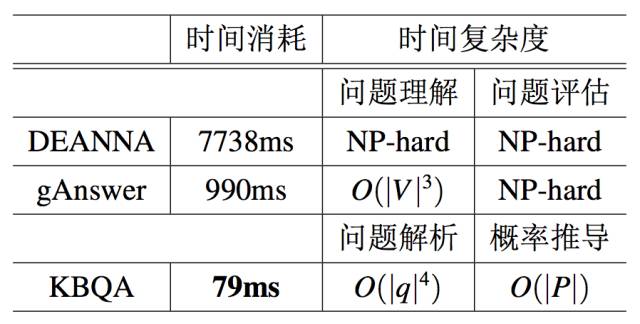
表 5.12:时间消耗
复杂度分析 表 5.12 中展示了它们的时间复杂度,|q| 表示问题的长度, |V| 表示 RDF 图中向量的个数。 所有的 KBQA 的步骤都可以在多项式时间内完成, 然而 gAnswer 和 DEANNA 都有 NP-hard 的步骤。 gAnswer 的问题理解的时间复杂度是 O(|V|3),这种复杂度对于十亿级别的数据库来说是不能接受的。相比之下,KBQA 的时间复杂度是 O(|q|4) 和 O(|P|) (|P|是不同属性的数量),和数据库的大小无关。正如第 5.3. 节中提到的,超过 99% 的问题的长度都是小于 23 的。因此,在时间复杂度方面,KBQA 比其他 QA 系统有着更好的表现。
7.5. KBQA 的具体模块评估
实验评估了 KBQA 的三个关键模块:实体-值的识别(第 4.1. 节),复杂问题的回答(第 5 节),属性扩展(第 6 节)。
实体和值的识别的准确性 大多数过去的研究都主要关注实体的抽取,这种技术并不能被用在同时抽取实体和值上。所以,实验只能和最新的实体识别的研究对比[33]。实验随机从问题语料中选择了 50 个答案在知识图谱中的问答对。通过人工判断抽取的结果是否正确。本文的方法正确识别了 36 个问答对(72%)。相比之下,斯坦福 NER 只识别的 15 个问答对(30%)。结果表明对于实体的共同抽取要比单独抽取要好。
回答复杂问题的有效性 因为没有对复杂问题回答的有效基准测试集,实验构造了如表 5.13 中的 8 个问题。这里列举的所有问题都是真实的用户提出的典型复杂问题。实验比较了 KBQA 和其他两个最新的 QA 系统:Wolfram Alpha 和 gAnswer。表 5.13 中展示了结果,实验发现 KBQA 在回答复杂问题方面战胜了它的对手,这表明 KBQA 对回答复杂问题是有效的。

表 5.13: 复杂问题回答。WA 表示 Wolfram Alpha, gA 表示 gAnswer
属性扩展的有效性 接下来实验将会测评系统在属性扩展在两方面的有效性。第一,属性扩展可以识别更多的属性。第二,扩展属性使 KBQA 学习更多的模板。表 5.14 中展示了评估结果。可以发现 (1) 相较于直接属性(长度为 1),扩展属性(长度为 2 到 k)生成了十倍于前者的属性数量;(2) 归因于扩展属性,模板的数量增加了 57 倍。
实验进一步使用了两个案例来阐明:(1) 扩展的属性是有意义的,(2) 扩展属性是正确的。表 5.16 中列举了学习出的 5 个扩展属性。可以发现 KBQA 识别出的这些属性都是有意义的。实验进一步选择了一个扩展属性 marriage → person → name,来验证从这一属性中学习出的模板是否正确并有意义。表 5.15 中列举了 5 个模板,这些模板都是合理的。
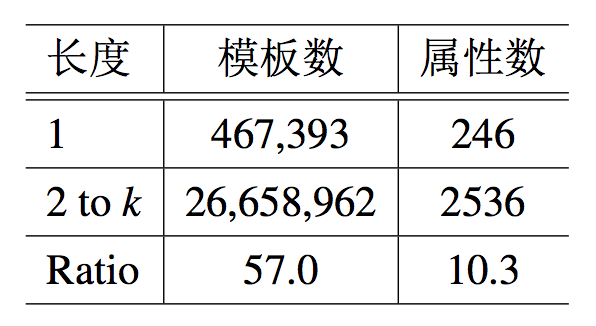
表 5.14:属性扩展的效果

表 5.15:marriage → person → name 的对应属性

表 5.16:属性扩展的例子
第 8 节 相关工作
在计算机领域,问答系统是一个经典的研究问题。在信息检索(IR),数据挖掘和自然语言处理(NLP)领域它都被广泛研究。本节首先根据数据来源调研了一些相关工作。然后本节调研基于知识图谱的的问答系统。最后调研了 RDF 数据管理的最新进展。
自然语言文本 vs 知识库 问答系统对于语料库的质量有着很强的依赖性。传统的问答系统使用 web 文本或是 Wikipedia 作为它们的语料库来回答问题。在这一分类中的最新的方法[78, 56, 22, 44]通常将网络文档或是 Wiki 中的句子作为问题的答案,并根据它们和问题的相关性来进行打分。他们也使用一些去噪音的方法,比如说问题分类[66, 111],来增加答案的质量。最近几年,许多大规模知识库的诞生,例如 Google Knowledge Graph,Freebase[10]和 YAGO2[45],为建立新的 QA 系统提供了机会[72, 98, 97, 36, 107, 31]。这些知识库比起依赖于网络文本的 QA 系统,有着更系统的架构,并且有着更清晰和可靠的回答。
基于知识图谱的问答系统 基于知识图谱的问答系统的核心处理是对问题的属性识别。例如,对于问题 How many people are there in Honolulu,如果系统能找到属性“population”,这个问题就能被回答。根据属性识别的方式分类,这些知识库的发展经历了三个主要的阶段:基于规则,基于关键词,和基于同义词 。基于规则的方法用人为创造的规则将问题映射到属性。例如,Ou et al. [72]认为形如 What is the xxx of entity? 的问题应该被映射到属性 xxx。人为构建的规则通常有高的准确率,但是召回率很低。基于关键词的方法[98]用问题中关键词或词组作为特征来找到问题和属性之间的映射。但是通常,很难用关键词来找到问题和复杂属性之间的映射。系统很难基于关键词,例如“how many”, “people”, “are there”等,来映射问题 how many people are there in ...? 到属性“population”。基于同义词的方法[97, 107]通过考虑属性的同义词,扩展了基于关键词方法。这使得它可以回答更多的问题。这个方法的主要影响因素是同义词的质量。Unger et al. [97]用 bootstrapping [36] 来生成同义词。Yahya et al. [107]则用 Wikipedia 来生成同义词。然而,由于和基于关键词的方法相同的原因,基于同义词的方法仍然不能回答复杂问题。True knowledge [94]用关键词和词组来表示一个模板。True knowledge 应该被分类到基于同义词的方法。相比之下,本章的问题模板将实体概念化来表示问题。
总而言之,相比于本章使用问题模板的理解方式,之前所有的基于知识库的 QA 系统仍然在准确率和召回率方面有着他们的弱点。
第 9 节 小结
基于知识库的 QA 系统现在已经成为了一项重要且可行的工作。本章在一个大型开放领域 RDF 知识库的基础上建立了一个问答系统。系统和之前的工作有以下四点不同:(1) 它用模板理解问题,(2) 它用模板抽取来学习从模板到属性的映射,(3) 用 RDF 中的扩展属性来提升知识库的覆盖率,(4) 理解复杂问题来提高对于问题的覆盖率。实验表明 KBQA 是有效且高效的,尤其是在准确性方面,比其他的 QA 系统都要优秀。 










