AI 科技评论按
:
美国时间10月31日,百度研究院发出博文,宣布发布新一代深度语音识别系统 Deep Speech 3。继2014首秀的第一代Deep Speech和被MIT科技评论评为“2016年十大突破技术之一”的 Deep Speech 2之后,百度再一次展现出自己的研究水平以及技术应用的愿景。AI 科技评论把百度研究院这篇博文编译如下。

准确的语音识别系统是许多商业应用中不可或缺的一环,比如虚拟助手接收命令、能理解用户反馈的视频评价,或者是用来提升客户服务质量。不过,目前想要构建一个水平领先的语音识别系统,要么需要从第三方数据提供商购买用户数据,要么就要从全球排名前几位的语音和语言技术机构挖人。
百度研究院的研究人员们一直都在努力开发一个语音识别系统,它不仅要有好的表现,而且系统的构建、调试、改进的时候都只需要一支语音识别入门水平、甚至完全不了解语音识别技术的团队就可以(不过他们还是需要对机器学习有深入的理解)。百度的研究人员们相信,一个高度易用的语音识别流水线可以让语音识别平民化,就像卷积神经网络带来了计算机视觉领域的革命一样。
在这个持续的努力过程中,百度首先开发出了第一代Deep Speech,这是一个概念验证性的产品,但它也表明了一个简单模型的表现就可以和当时顶尖模型的表现相媲美。随着Deep Speech 2的发布,百度表明了这样的模型对不同的语言具有良好的泛化性,并开始把它部署在许多实际应用中。
10月31日,百度的硅谷AI实验室发布了Deep Speech 3,这是下一代的语音识别模型,它进一步简化了模型,并且可以在使用预训练过的语言模型时继续进行端到端训练。
在
论文
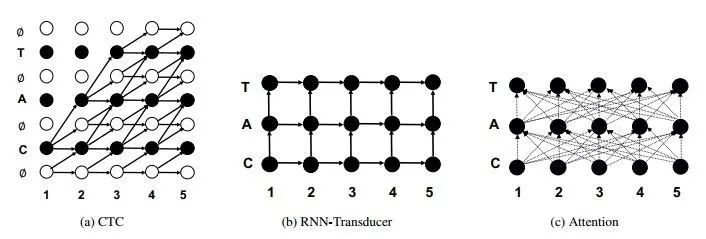
中,百度研究院的研究员们首先对三个模型进行了实证比较:Deep Speech 2的核心CTC、其它一些
Listend-Attend-Spell
语音识别系统中使用的基于注意力的Seq2Seq模型,以及端到端语音识别中应用的RNN变换器。这个RNN变换器可以看作一个编码器-解码器模型,其中假设输入和输出标识之间的对应关系是局部的、单调的。这就让RNN变换器的损失比基于注意力的Seq2Seq更适合用于语音识别(尤其在互联网应用中),它去除了带有注意力的模型中用来鼓励单调性的额外剪枝。
并且,CTC需要一个外部的语言模型用来输出有意义的结果,RNN变换器就不需要这样,它可以支持一个纯粹由神经网络构成的解码器,模型的训练和测试阶段之间也不会产生错位。所以自然地,RNN变换器比CTC模型具有更好的表现,都不需要一个外部的语言模型。
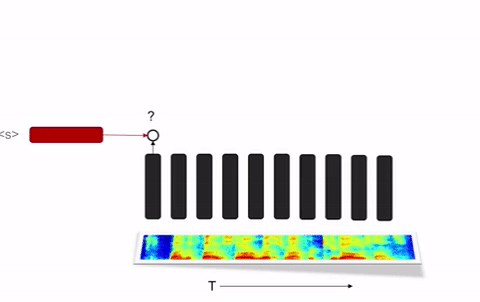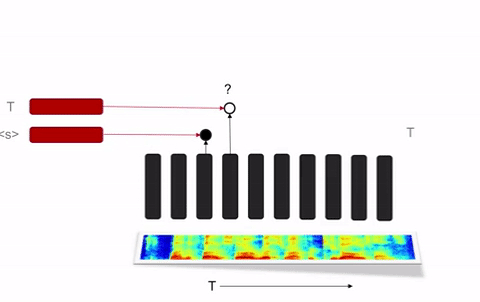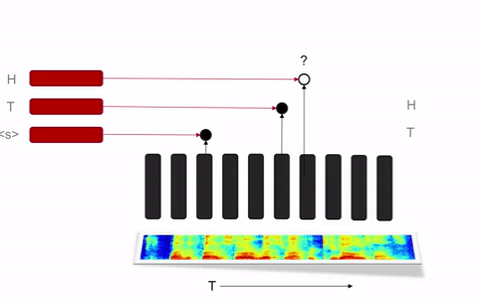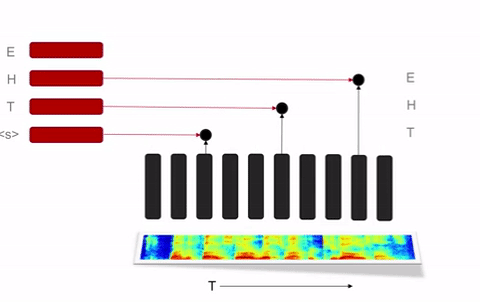
Seq2Seq和RNN变换器无需外部语言模型就可以达到良好表现的状况也提出了一个挑战。语言模型对语音识别很关键,因为语言模型可以用大得多的数据集快速训练;而且语言模型可以对语音识别模型做特定的优化,让它更好地识别特定内容(用户,地理,应用等等),同时无需给每一类的内容都提供有标注的语音语料。百度的研究人员们在部署Deep Speech 2的过程中发现,这后一条特点对用于生产环境的语音识别系统来说尤其重要。





