作者:wklken
来源:
http://blog.csdn.net/wklken/article/details/7884529
今天开新浪微博,才发现收藏已然有2000+了,足足104页,貌似需要整理下了,可是一页页整理,难以想象
所以想下载,然后进行提取处理,转为文档。
我们关注的:
1.微博正文+评论内容
2.图片
3.视频链接
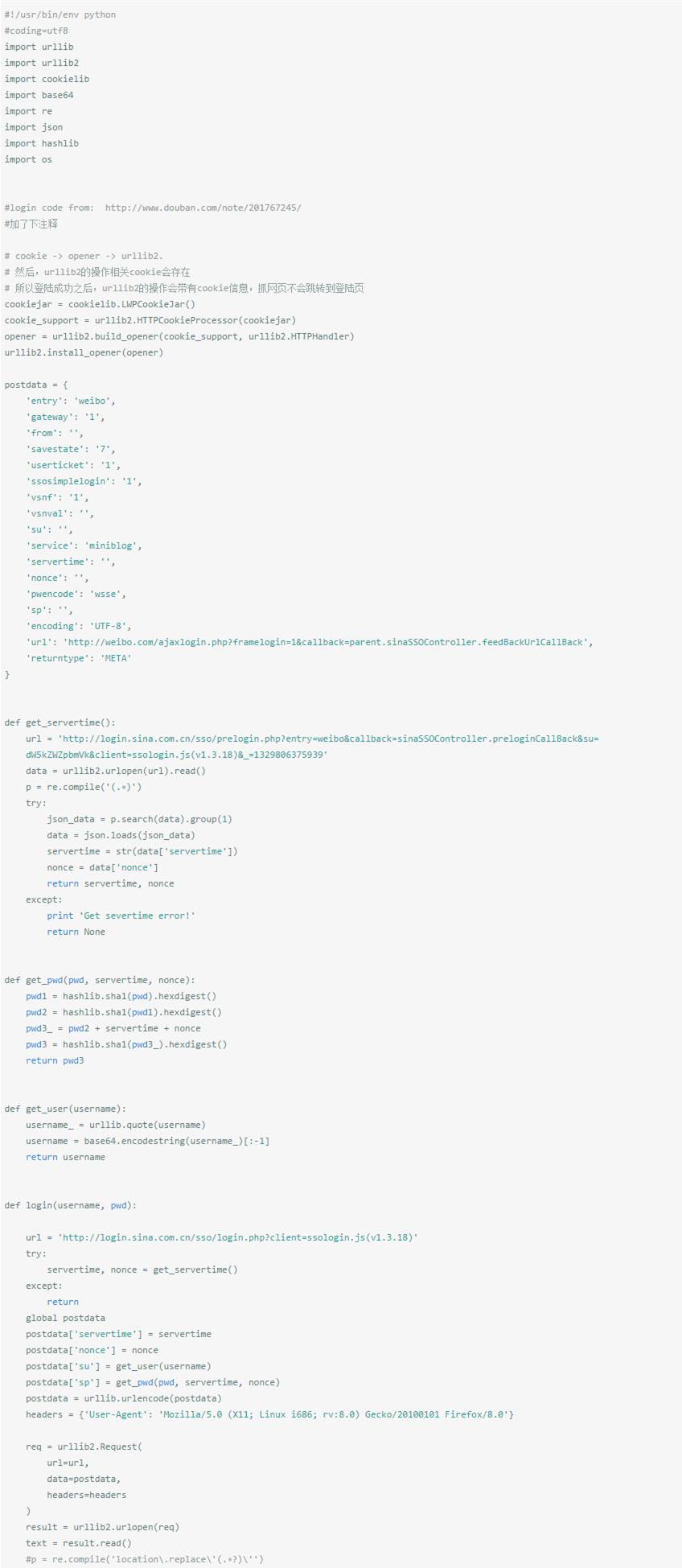
1.脚本模拟登陆新浪微博,保存cookie
2.有了cookie信息后,访问收藏页面url
3.从第一页开始,逐步访问,直到最后,脚本中进行了两步处理
A.直接下载网页(下载到本地,当然,要看的时候需要联网,因为js,图片神马的,都还在)
B.解析出微博需要的内容,目前只是存下来,还没有处理
后续会用lxml通过xpath读取,转换成文档,当然,图片和视频链接也会一同处理,目前未想好处理成什么格式。(困了,明后天接着写)
模拟登陆微博采用是http://www.douban.com/note/201767245/
里面很详细,直接拉来用了
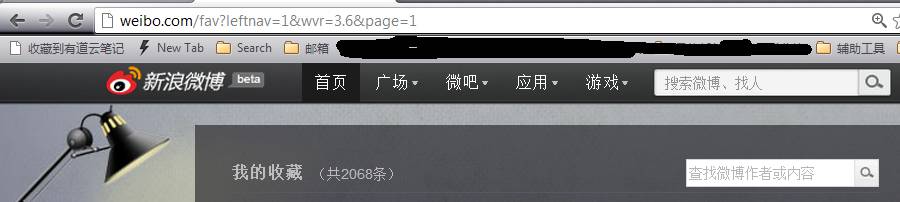
1.进入自己的微博,右侧,收藏,进入收藏页面
http://weibo.com/fav?leftnav=1&wvr=3.6&page=1
拿前缀
2.修改脚本填写
用户名
密码
前缀
http://weibo.com/fav?leftnav=1&wvr=3.6&page=
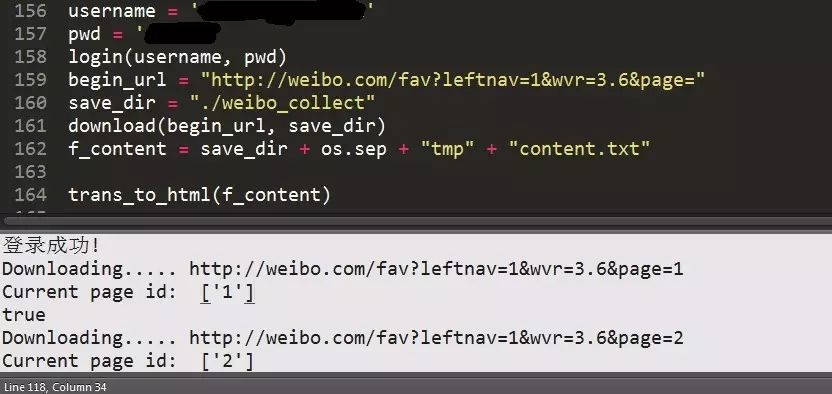
3.运行脚本
python weibo_collect.py
结果:
其中,带序号的,只能连网时点击打开有效
tmpcontent是包含所有微博内容信息,但目前还没有处理(还没想好提取成什么格式,容后再说)