在微信公众号目前的算法下,为了及时看到,建议星标☆我的投资会。
李想访谈说,AI是超过谷歌的大机会。
最近幻方悄悄上线了DeepSeek V3,
作为量化巨头,幻方一向是中国大模型价格战的发动者,当时DeepSeek v2出圈也是因为做到好用又便宜,盛传幻方是中国持有高性能GPU最多的公司。
有人做了初步评测,结论就是:已经与GPT-4o、Claude-3.5-sonnet推理能力相当,甚至编程媲美最领先的3.5 Sonnet,超过GPT-4o。
今天出圈并对市场有所扰动的信息是是:
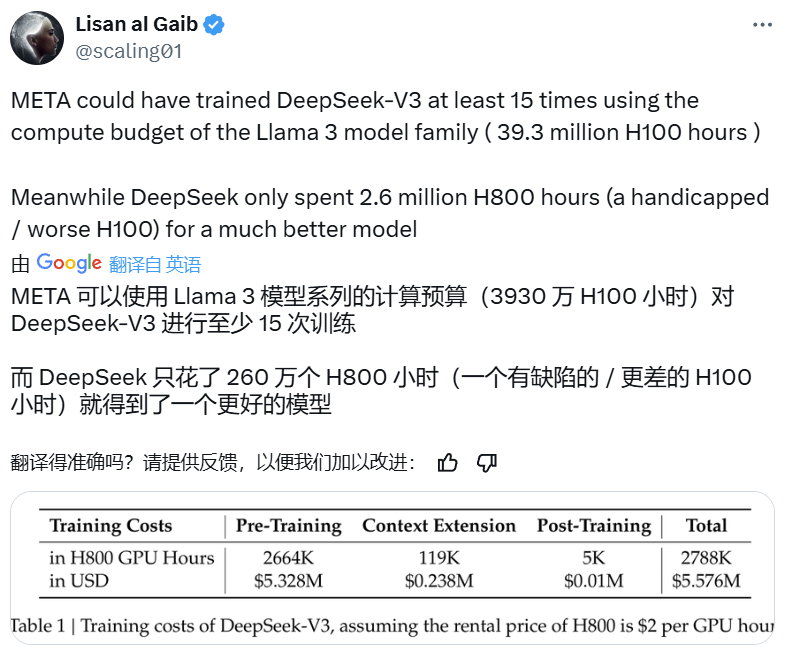
这个参数量高达 671B 的大型语言模型的预训练过程竟然只用了 266.4 万 H800 GPU Hours,
再加上上下文扩展与后训练的训练,总共也只有 278.8 H800 GPU Hours。相较之下,Llama 3 系列模型的计算预算则多达 3930 万 H100 GPU Hours—— 如此计算量足可训练 DeepSeek-V3 至少 15 次。
几乎所有投资者圈层都在问:幻方Deepseek v3只用了2048卡的H800,训练两个月就完成了。你们公司买了10万张卡,单集群万卡,都搞出什么成果来了?有人质疑OpenAI干什么去了。
目前有这么几个解释:
-训练只有一次,推理是无数次。推理需求实质上远大于训练需求,尤其是用户基数大了。
- Deepseek是站在巨人的肩膀上,使用大量高质量合成数据。
- Deepseek这个统计口径只计算了训练,但数据的配比需要做大量的预实验,合成数据的生成和清洗也需要消耗算力。
- Deepseek的模型的MoE每个专家都可以单独拿出来训练,本身相比于dense架构就是省力一些的方案。
- Deepseek采用FP8训练,而FP8的训练本身就不怎么耗资源,相比FP16或BF16,FP8的Tensor Core可提供两倍的TFlops算力此外,FP8的数据类型占用的比特数更少,可以降低内存占用消耗在实际测试中,FP8训练吞吐对比BF16性能可提升30%至50%。
- 所谓节省90%算力还能和chatgpt匹敌的这个大模型不太行,噱头为主。
-人人都超越了GPT 4o,llama 3天天被踩在脚底下,消费者和企业界实际使用用的最多的还是这两个模型。这些宣传的成绩未必可靠。
另一个出
圈的是
小米ALL in AI:12月26日,界面新闻独家获悉,小米正在着手搭建自己的GPU万卡集群,将对AI大模型大力投入。
而DeepSeek开源大模型
DeepSeek-V2的关键开发者之一罗福莉将加入小米,有望加入小米AI实验室领导大模型团队。
- AI基础:金山云
- AI生态:人车家全生态
- AI应用场景:小米AI智能lOT+小米AI手机+WPS AI+小米AI智驾

为什么要做万卡集群?
本质上是加速强化自身大模型,对模型能力的补强。海外对标的大厂包括Google、Meta、微软都是软硬件结合,预期25年开始国内大厂都会对标海外、平推大模型各个环节。小米原先在硬件制造/供应链上通过手机、耳机等系列智能终端中完成了能力储备,但是对于“软”的部分(大模型)还有所欠缺。
为什么要对AI生态平推式的进入?
究其根本是在于追求下一代互联网时代的入口,强化自身模型能力,且不能放过任何一个可能成为下一代终端的产品——包括手机/耳机/眼镜
对于小米当前宣布万卡集群的看法?










