(点击上方蓝字,快速关注我们)
编译:伯乐在线 - 努力学python
如有好文章投稿,请点击 → 这里了解详情
本文是 2014 年 12 月我在布拉格经济大学做的名为‘ Python 数据科学’讲座的笔记。欢迎通过 @RadimRehurek 进行提问和评论。
本次讲座的目的是展示一些关于机器学习的高级概念。该笔记中用具体的代码来做演示,大家可以在自己的电脑上运行(需要安装 IPython,如下所示)。
本次讲座的听众需要了解一些基础的编程(不一定是 Python),并拥有一点基本的数据挖掘背景。本次讲座不是机器学习专家的“高级演讲”。
这些代码实例创建了一个有效的、可执行的原型系统:一个使用“spam”(垃圾信息)或“ham”(非垃圾信息)对英文手机短信(”短信类型“的英文)进行分类的 app。

整套代码使用 Python 语言。 python 是一种在管线(pipeline)的所有环节(I/O、数据清洗重整和预处理、模型训练和评估)都好用的通用语言。尽管 python 不是唯一选择,但它灵活、易于开发,性能优越,这得益于它成熟的科学计算生态系统。Python 庞大的、开源生态系统同时避免了任何单一框架或库的限制(以及相关的信息丢失)。
IPython notebook,是 Python 的一个工具,它是一个以 HTML 形式呈现的交互环境,可以通过它立刻看到结果。我们也将重温其它广泛用于数据科学领域的实用工具。
想交互运行下面的例子(选读)?
安装免费的 Anaconda Python 发行版,其中已经包含 Python 本身。
安装“自然语言处理”库——TextBlob:安装包在这。
下载本文的源码(网址:http://radimrehurek.com/data_science_python/data_science_python.ipynb 并运行:$ ipython notebook data_science_python.ipynb
观看 IPython notebook 基本用法教程 IPython tutorial video 。
运行下面的第一个代码,如果执行过程没有报错,就可以了。
端到端的例子:自动过滤垃圾信息
In [1]:
%matplotlib inline
import matplotlib.pyplot as plt
import csv
from textblob import TextBlob
import pandas
import sklearn
import cPickle
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import SVC, LinearSVC
from sklearn.metrics import classification_report, f1_score, accuracy_score, confusion_matrix
from sklearn.pipeline import Pipeline
from sklearn.grid_search import GridSearchCV
from sklearn.cross_validation import StratifiedKFold, cross_val_score, train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.learning_curve import learning_curve
第一步:加载数据,浏览一下
让我们跳过真正的第一步(完善资料,了解我们要做的是什么,这在实践过程中是非常重要的),直接到 https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection 下载 demo 里需要用的 zip 文件,解压到 data 子目录下。你能看到一个大概 0.5MB 大小,名为 SMSSpamCollection 的文件:
$ <span class="kw">lsspan> -l data
<span class="kw">totalspan> 1352
<span class="kw">-rw-r--r--@span> 1 kofola staff 477907 Mar 15 2011 SMSSpamCollection
<span class="kw">-rw-r--r--@span> 1 kofola staff 5868 Apr 18 2011 readme
<span class="kw">-rw-r-----@span> 1 kofola staff 203415 Dec 1 15:30 smsspamcollection.zip
这份文件包含了 5000 多份 SMS 手机信息(查看 readme 文件以获得更多信息):
In [2]:
messages = [line.rstrip() for line in open('./data/SMSSpamCollection')]
print len(messages)
5574
文本集有时候也称为“语料库”,我们来打印 SMS 语料库中的前 10 条信息:
In [3]:
for message_no, message in enumerate(messages[:10]):
print message_no, message
0 ham Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...
1 ham Ok lar... Joking wif u oni...
2 spam Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's
3 ham U dun say so early hor... U c already then say...
4 ham Nah I don't think he goes to usf, he lives around here though
5 spam FreeMsg Hey there darling it's been 3 week's now and no word back! I'd like some fun you up for it still? Tb ok! XxX std chgs to send, £1.50 to rcv
6 ham Even my brother is not like to speak with me. They treat me like aids patent.
7 ham As per your request 'Melle Melle (Oru Minnaminunginte Nurungu Vettam)' has been set as your callertune for all Callers. Press *9 to copy your friends Callertune
8 spam WINNER!! As a valued network customer you have been selected to receivea £900 prize reward! To claim call 09061701461. Claim code KL341. Valid 12 hours only.
9 spam Had your mobile 11 months or more? U R entitled to Update to the latest colour mobiles with camera for Free! Call The Mobile Update Co FREE on 08002986030
我们看到一个 TSV 文件(用制表符 tab 分隔),它的第一列是标记正常信息(ham)或“垃圾文件”(spam)的标签,第二列是信息本身。
这个语料库将作为带标签的训练集。通过使用这些标记了 ham/spam 例子,我们将训练一个自动分辨 ham/spam 的机器学习模型。然后,我们可以用训练好的模型将任意未标记的信息标记为 ham 或 spam。
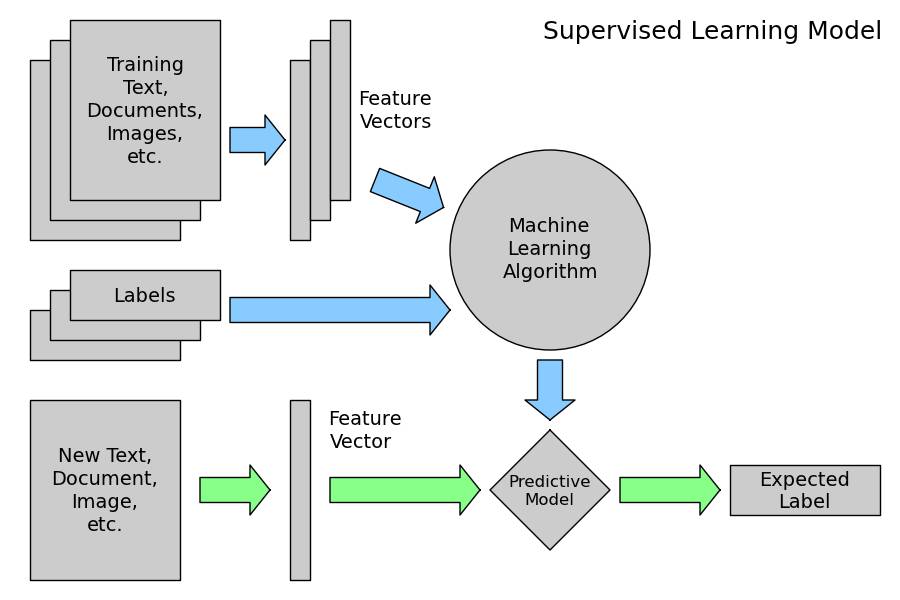
我们可以使用 Python 的 Pandas 库替我们处理 TSV 文件(或 CSV 文件,或 Excel 文件):
In [4]:
messages = pandas.read_csv('./data/SMSSpamCollection', sep='t', quoting=csv.QUOTE_NONE,
names=["label", "message"])
print messages

我们也可以使用 pandas 轻松查看统计信息:
In [5]:
messages.groupby('label').describe()
out[5]:

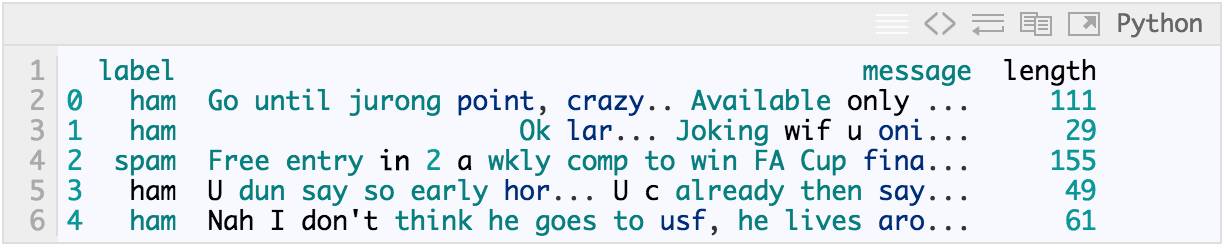
这些信息的长度是多少:
In [6]:
messages['length'] = messages['message'].map(lambda text: len(text))
print messages.head()
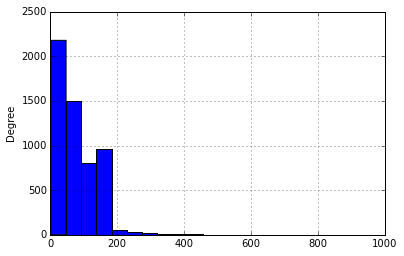
In [7]:
messages.length.plot(bins=20, kind='hist')
Out[7]:
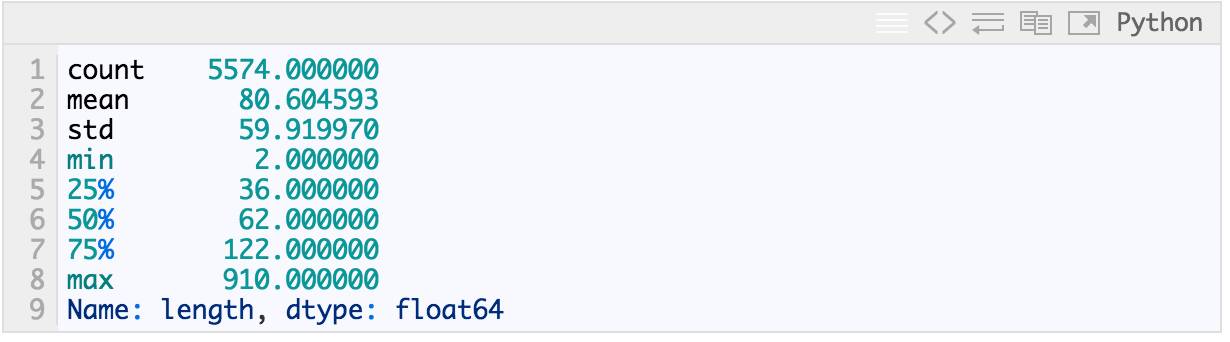
In [8]:
messages.length.describe()
Out[8]:
哪些是超长信息?
In [9]:
print list(messages.message[messages.length > 900])

spam 信息与 ham 信息在长度上有区别吗?
In [10]:
messages.hist(column='length', by='label', bins=50)
Out[10]:
array([,
], dtype=object)
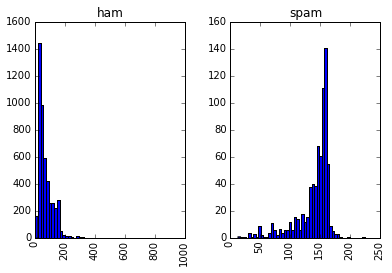
太棒了,但是我们怎么能让电脑自己识别文字信息?它可以理解这些胡言乱语吗?
第二步:数据预处理
这一节我们将原始信息(字符序列)转换为向量(数字序列);
这里的映射并非一对一的,我们要用词袋模型(bag-of-words)把每个不重复的词用一个数字来表示。
与第一步的方法一样,让我们写一个将信息分割成单词的函数:
In [11]:
def split_into_tokens(message):
message = unicode(message, 'utf8') # convert bytes into proper unicode
return TextBlob(message).words
这还是原始文本的一部分:
In [12]:
messages.message.head()
Out[12]:
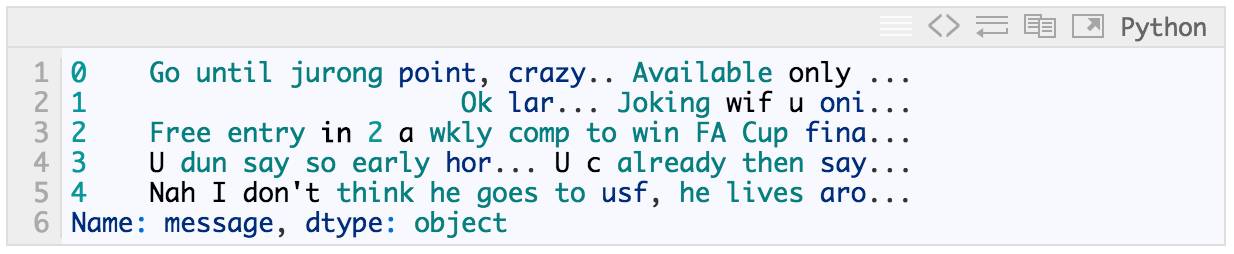
这是原始文本处理后的样子:
In [13]:
messages.message.head().apply(split_into_tokens)
Out[13]:

自然语言处理(NLP)的问题:
大写字母是否携带信息?
单词的不同形式(“goes”和“go”)是否携带信息?
叹词和限定词是否携带信息?
换句话说,我们想对文本进行更好的标准化。
我们使用 textblob 获取 part-of-speech (POS) 标签:
In [14]:
TextBlob("Hello world, how is it going?").tags # list of (word, POS) pairs
Out[14]:
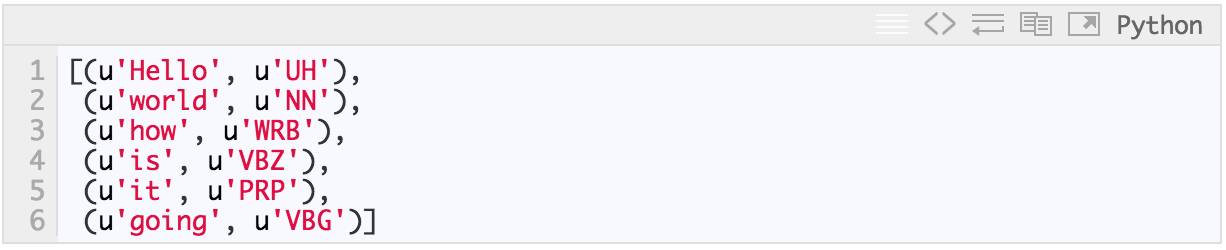
并将单词标准化为基本形式 (lemmas):
In [15]:

Out[15]:

这样就好多了。你也许还会想到更多的方法来改进预处理:解码 HTML 实体(我们上面看到的 & 和 <);过滤掉停用词 (代词等);添加更多特征,比如所有字母大写标识等等。
第三步:数据转换为向量
现在,我们将每条消息(词干列表)转换成机器学习模型可以理解的向量。
用词袋模型完成这项工作需要三个步骤:
1. 对每个词在每条信息中出现的次数进行计数(词频);
2. 对计数进行加权,这样经常出现的单词将会获得较低的权重(逆向文件频率);
3. 将向量由原始文本长度归一化到单位长度(L2 范式)。
每个向量的维度等于 SMS 语料库中包含的独立词的数量。
In [16]:
bow_transformer = CountVectorizer(analyzer=split_into_lemmas).fit(messages['message'])
print len(bow_transformer.vocabulary_)
8874
这里我们使用强大的 python 机器学习训练库 scikit-learn (sklearn),它包含大量的方法和选项。
我们取一个信息并使用新的 bow_tramsformer 获取向量形式的词袋模型计数:
In [17]:
message4 = messages['message'][3]
print message4
U dun say so early hor... U c already then say...
In [18]:
bow4 = bow_transformer.transform([message4])
print bow4
print bow4.shape
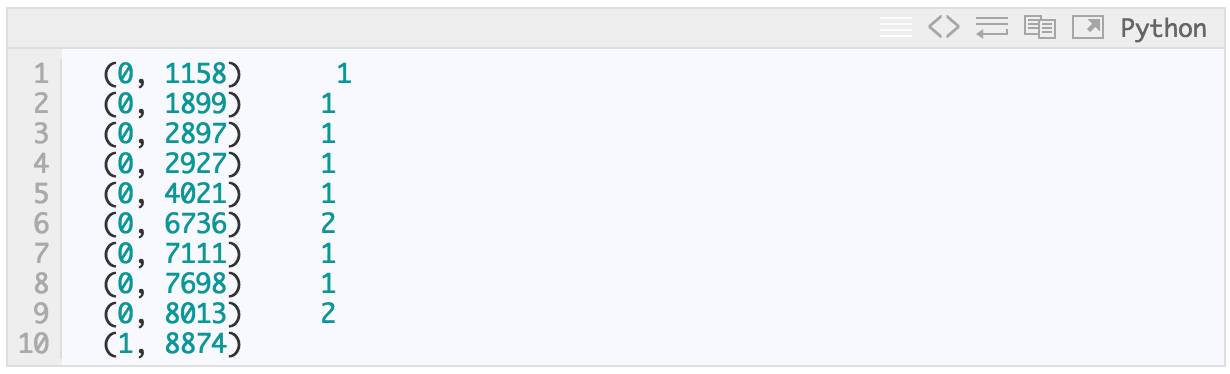
message 4 中有 9 个独立词,它们中的两个出现了两次,其余的只出现了一次。可用性检测,哪些词出现了两次?
In [19]:
print bow_transformer.get_feature_names()[6736]
print bow_transformer.get_feature_names()[8013]
say
u
整个 SMS 语料库的词袋计数是一个庞大的稀疏矩阵:
In [20]:
messages_bow = bow_transformer.transform(messages['message'])
print 'sparse matrix shape:', messages_bow.shape
print 'number of non-zeros:', messages_bow.nnz
print 'sparsity: %.2f%%' % (100.0 * messages_bow.nnz / (messages_bow.shape[0] * messages_bow.shape[1]))

最终,计数后,使用 scikit-learn 的 TFidfTransformer 实现的 TF-IDF 完成词语加权和归一化。
In [21]:

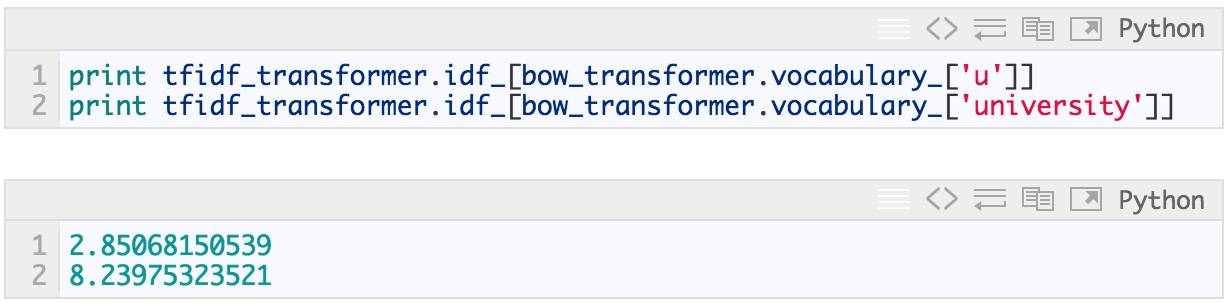
单词 “u” 的 IDF(逆向文件频率)是什么?单词“university”的 IDF 又是什么?
In [22]:
将整个 bag-of-words 语料库转化为 TF-IDF 语料库。
In [23]:
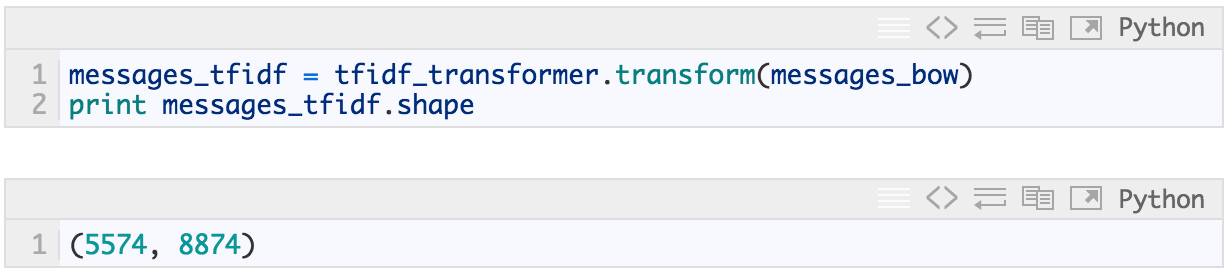
有许多方法可以对数据进行预处理和向量化。这两个步骤也可以称为“特征工程”,它们通常是预测过程中最耗时间和最无趣的部分,但是它们非常重要并且需要经验。诀窍在于反复评估:分析模型误差,改进数据清洗和预处理方法,进行头脑风暴讨论新功能,评估等等。
第四步:训练模型,检测垃圾信息
我们使用向量形式的信息来训练 spam/ham 分类器。这部分很简单,有很多实现训练算法的库文件。
这里我们使用 scikit-learn,首先选择 Naive Bayes 分类器:
In [24]:
我们来试着分类一个随机信息:
In [25]:
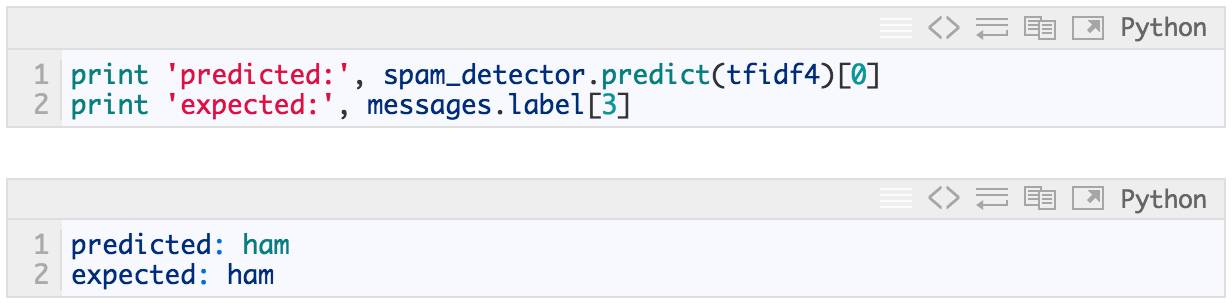
太棒了!你也可以用自己的文本试试。
有一个很自然的问题是:我们可以正确分辨多少信息?
In [26]:
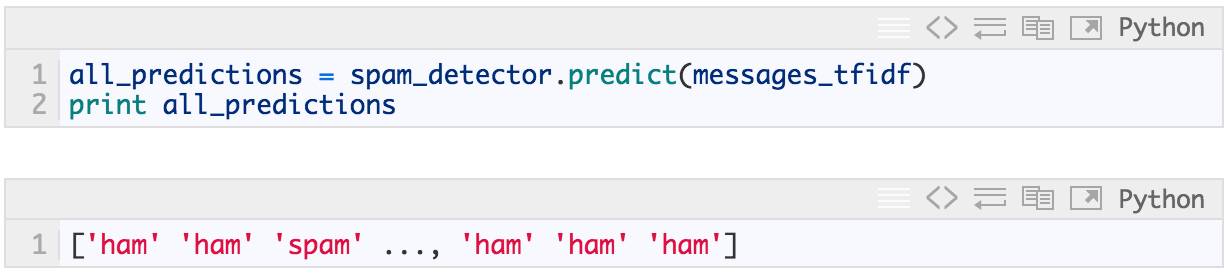
In [27]:
print 'accuracy', accuracy_score(messages['label'], all_predictions)
print 'confusion matrixn', confusion_matrix(messages['label'], all_predictions)
print '(row=expected, col=predicted)'

In [28]:
plt.matshow(confusion_matrix(messages['label'], all_predictions), cmap=plt.cm.binary, interpolation='nearest')
plt.title('confusion matrix')
plt.colorbar()
plt.ylabel('expected label')
plt.xlabel('predicted label')
Out[28]:
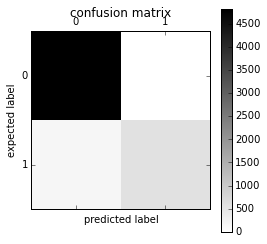
我们可以通过这个混淆矩阵计算精度(precision)和召回率(recall),或者它们的组合(调和平均值)F1:
In [29]:
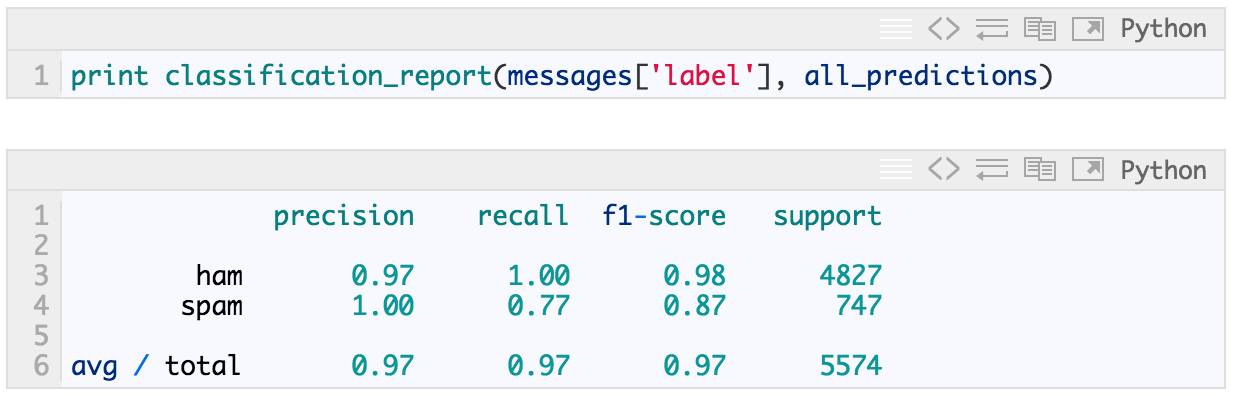
有相当多的指标都可以用来评估模型性能,至于哪个最合适是由任务决定的。比如,将“spam”错误预测为“ham”的成本远低于将“ham”错误预测为“spam”的成本。
第五步:如何进行实验?
在上述“评价”中,我们犯了个大忌。为了简单的演示,我们使用训练数据进行了准确性评估。永远不要评估你的训练数据。这是错误的。
这样的评估方法不能告诉我们模型的实际预测能力,如果我们记住训练期间的每个例子,训练的准确率将非常接近 100%,但是我们不能用它来分类任何新信息。
一个正确的做法是将数据分为训练集和测试集,在模型拟合和调参时只能使用训练数据,不能以任何方式使用测试数据,通过这个方法确保模型没有“作弊”,最终使用测试数据评价模型可以代表模型真正的预测性能。
In [30]:
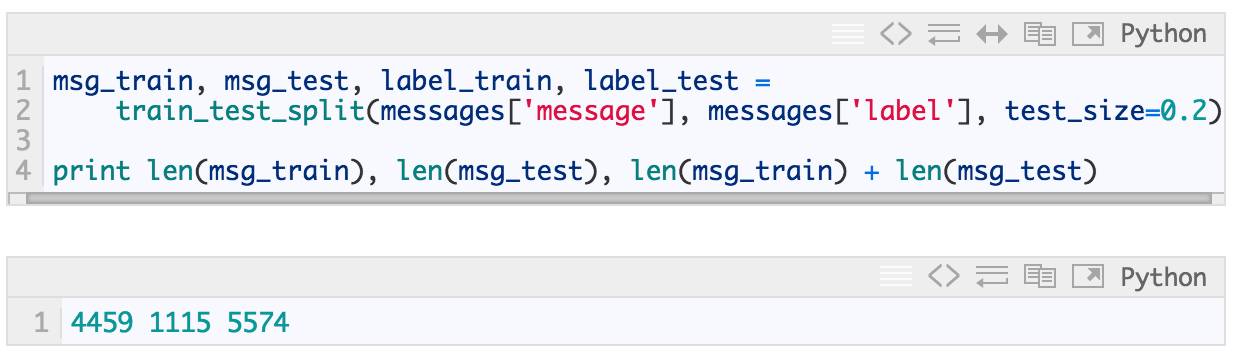
按照要求,测试数据占整个数据集的 20%(总共 5574 条记录中的 1115 条),其余的是训练数据(5574 条中的 4459 条)。
让我们回顾整个流程,将所有步骤放入 scikit-learn 的 Pipeline 中:
In [31]:

实际当中一个常见的做法是将训练集再次分割成更小的集合,例如,5 个大小相等的子集。然后我们用 4 个子集训练数据,用最后 1 个子集计算精度(称之为“验证集”)。重复5次(每次使用不同的子集进行验证),这样可以得到模型的“稳定性“。如果模型使用不同子集的得分差异非常大,那么很可能哪里出错了(坏数据或者不良的模型方差)。返回,分析错误,重新检查输入数据有效性,重新检查数据清洗。
在这个例子里,一切进展顺利:
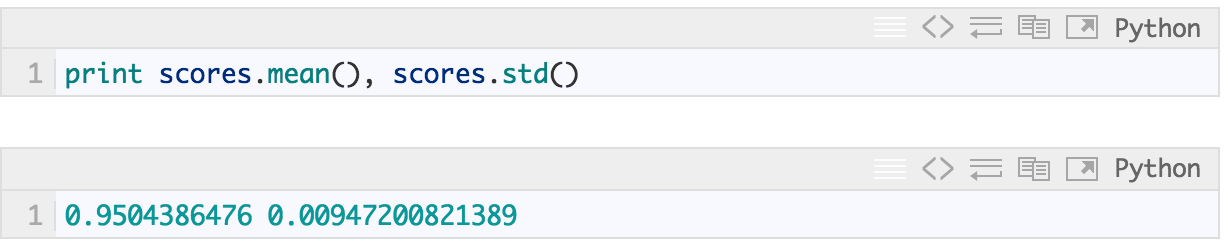
In [32]:


得分确实比训练全部数据时差一点点( 5574 个训练例子中,准确性 0.97),但是它们相当稳定:
In [33]:
我们自然会问,如何改进这个模型?这个得分已经很高了,但是我们通常如何改进模型呢?
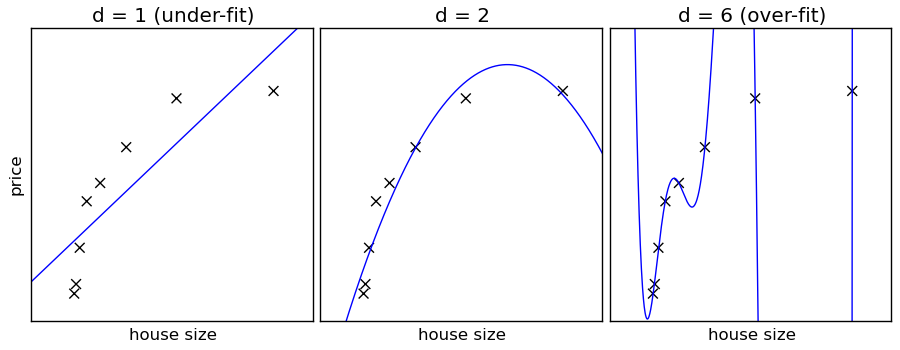
Naive Bayes 是一个高偏差-低方差的分类器(简单且稳定,不易过度拟合)。与其相反的例子是低偏差-高方差(容易过度拟合)的 k 最临近(kNN)分类器和决策树。Bagging(随机森林)是一种通过训练许多(高方差)模型和求均值来降低方差的方法。
换句话说:
In [34]:

In [35]:
%time plot_learning_curve(pipeline, "accuracy vs. training set size", msg_train, label_train, cv=5)
CPU times: user 382 ms, sys: 83.1 ms, total: 465 ms
Wall time: 28.5 s
Out[35]:

(我们对数据的 64% 进行了有效训练:保留 20% 的数据作为测试集,保留剩余的 20% 做 5 折交叉验证 = > 0.8*0.8*5574 = 3567个训练数据。)
随着性能的提升,训练和交叉验证都表现良好,我们发现由于数据量较少,这个模型难以足够复杂/灵活地捕获所有的细微差别。在这种特殊案例中,不管怎样做精度都很高,这个问题看起来不是很明显。
关于这一点,我们有两个选择:
使用更多的训练数据,增加模型的复杂性;
使用更复杂(更低偏差)的模型,从现有数据中获取更多信息。
在过去的几年里,随着收集大规模训练数据越来越容易,机器越来越快。方法 1 变得越来越流行(更简单的算法,更多的数据)。简单的算法(如 Naive Bayes)也有更容易解释的额外优势(相对一些更复杂的黑箱模型,如神经网络)。
了解了如何正确地评估模型,我们现在可以开始研究参数对性能有哪些影响。
第六步:如何调整参数?
到目前为止,我们看到的只是冰山一角,还有许多其它参数需要调整。比如使用什么算法进行训练。
上面我们已经使用了 Navie Bayes,但是 scikit-learn 支持许多分类器:支持向量机、最邻近算法、决策树、Ensamble 方法等…
我们会问:IDF 加权对准确性有什么影响?消耗额外成本进行词形还原(与只用纯文字相比)真的会有效果吗?
让我们来看看:
In [37]:
In [38]:
%time nb_detector = grid.fit(msg_train, label_train)
print nb_detector.grid_scores_
CPU times: user 4.09 s, sys: 291 ms, total: 4.38 s
Wall time: 20.2 s
[mean: 0.94752, std: 0.00357, params: {'tfidf__use_idf': True, 'bow__analyzer': <function split_into_lemmas at 0x1131e8668>}, mean: 0.92958, std: 0.00390, params: {'tfidf__use_idf': False, 'bow__analyzer': <function split_into_lemmas at 0x1131e8668>}, mean: 0.94528, std: 0.00259, params: {'tfidf__use_idf': True, 'bow__analyzer': <function split_into_tokens at 0x11270b7d0>}, mean: 0.92868, std: 0.00240, params: {'tfidf__use_idf': False, 'bow__analyzer': <function split_into_tokens at 0x11270b7d0>}]
(首先显示最佳参数组合:在这个案例中是使用 idf=True 和 analyzer=split_into_lemmas 的参数组合)
快速合理性检查
In [39]:
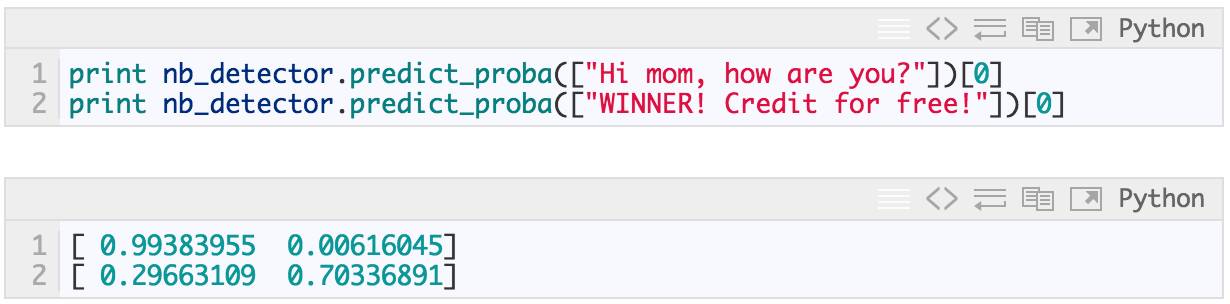
predict_proba 返回每类(ham,spam)的预测概率。在第一个例子中,消息被预测为 ham 的概率 >99%,被预测为 spam 的概率 <1%。如果进行选择模型会认为信息是 ”ham“:
In [40]:
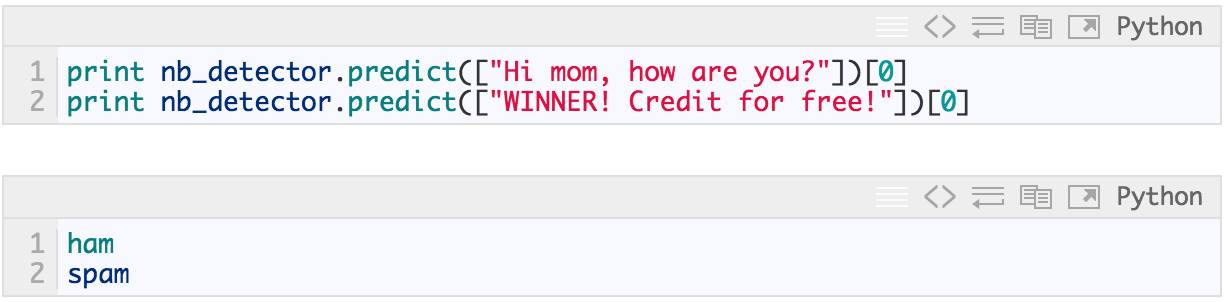
在训练期间没有用到的测试集的整体得分:
In [41]:
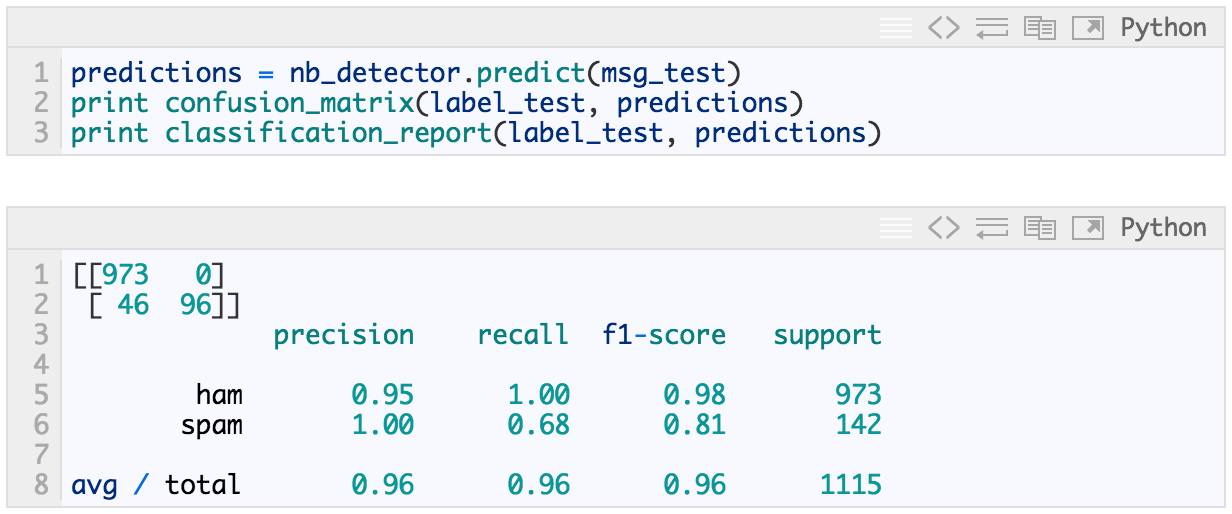
这是我们使用词形还原、TF-IDF 和 Navie Bayes 分类器的 ham 检测 pipeline 获得的实际预测性能。
让我们尝试另一个分类器:支持向量机(SVM)。SVM 可以非常迅速的得到结果,它所需要的参数调整也很少(虽然比 Navie Bayes 稍多一点),在处理文本数据方面它是个好的起点。
In [42]:
pipeline_svm = Pipeline([
('bow', CountVectorizer(analyzer=split_into_lemmas)),
('tfidf', TfidfTransformer()),
('classifier', SVC()), # <== change here
])
# pipeline parameters to automatically explore and tune
param_svm = [
{'classifier__C': [1, 10, 100, 1000], 'classifier__kernel': ['linear']},
{'classifier__C': [1, 10, 100, 1000], 'classifier__gamma': [0.001, 0.0001], 'classifier__kernel': ['rbf']},
]
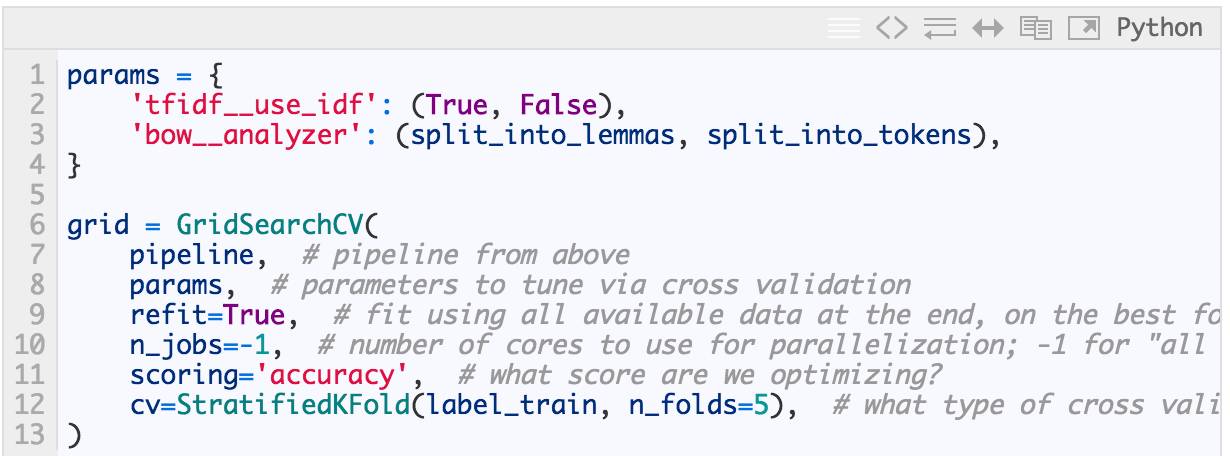
grid_svm = GridSearchCV(
pipeline_svm, # pipeline from above
param_grid=param_svm, # parameters to tune via cross validation
refit=True, # fit using all data, on the best detected classifier
n_jobs=-1, # number of cores to use for parallelization; -1 for "all cores"
scoring='accuracy', # what score are we optimizing?
cv=StratifiedKFold(label_train, n_folds=5), # what type of cross validation to use
)
In [43]:
%time svm_detector = grid_svm.fit(msg_train, label_train) # find the best combination from param_svm
print svm_detector.grid_scores_
CPU times: user 5.24 s, sys: 170 ms, total: 5.41 s
Wall time: 1min 8s
[mean: 0.98677, std: 0.00259, params: {'classifier__kernel': 'linear', 'classifier__C': 1}, mean: 0.98654, std: 0.00100, params: {'classifier__kernel': 'linear', 'classifier__C': 10}, mean: 0.98654, std: 0.00100, params: {'classifier__kernel': 'linear', 'classifier__C': 100}, mean: 0.98654, std: 0.00100, params: {'classifier__kernel': 'linear', 'classifier__C': 1000}, mean: 0.86432, std: 0.00006, params: {'classifier__gamma': 0.001, 'classifier__kernel': 'rbf', 'classifier__C': 1}, mean: 0.86432, std: 0.00006, params: {'classifier__gamma': 0.0001, 'classifier__kernel': 'rbf', 'classifier__C': 1}, mean: 0.86432, std: 0.00006, params: {'classifier__gamma': 0.001, 'classifier__kernel': 'rbf', 'classifier__C': 10}, mean: 0.86432, std: 0.00006, params: {'classifier__gamma': 0.0001, 'classifier__kernel': 'rbf', 'classifier__C': 10}, mean: 0.97040, std: 0.00587, params: {'classifier__gamma': 0.001, 'classifier__kernel': 'rbf', 'classifier__C': 100}, mean: 0.86432, std: 0.00006, params: {'classifier__gamma': 0.0001, 'classifier__kernel': 'rbf', 'classifier__C': 100}, mean: 0.98722, std: 0.00280, params: {'classifier__gamma': 0.001, 'classifier__kernel': 'rbf', 'classifier__C': 1000}, mean: 0.97040, std: 0.00587, params: {'classifier__gamma': 0.0001, 'classifier__kernel': 'rbf', 'classifier__C': 1000}]
因此,很明显的,具有 C=1 的线性核函数是最好的参数组合。
再一次合理性检查:
In [44]:
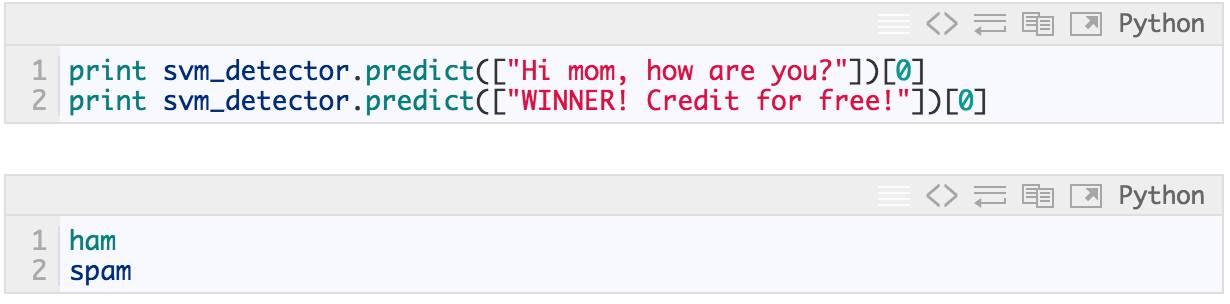
In [45]:
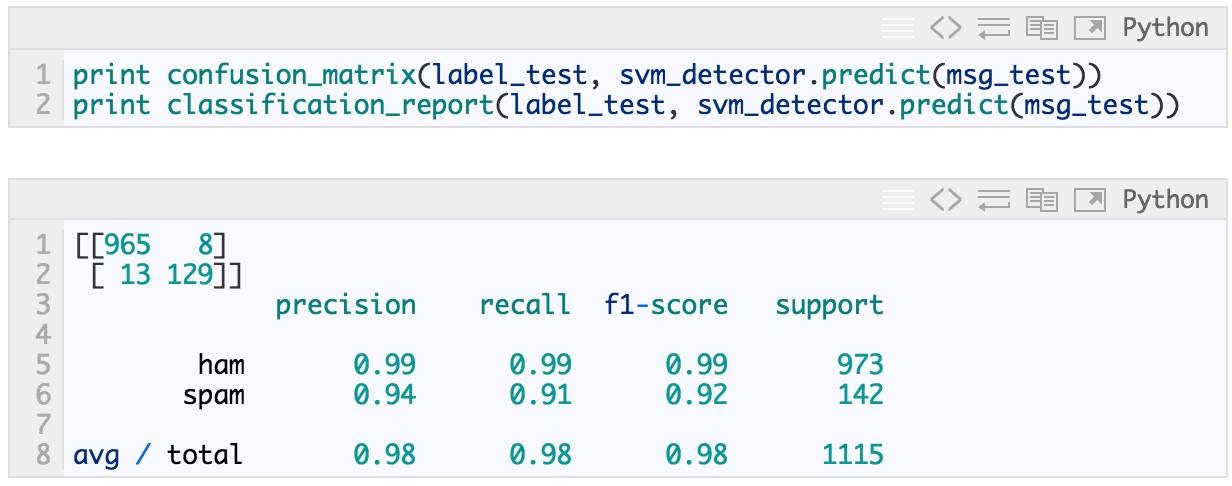
这是我们使用 SVM 时可以从 spam 邮件检测流程中获得的实际预测性能。
第七步:生成预测器
经过基本分析和调优,真正的工作(工程)开始了。
生成预测器的最后一步是再次对整个数据集合进行训练,以充分利用所有可用数据。当然,我们将使用上面交叉验证找到的最好的参数。这与我们开始做的非常相似,但这次深入了解它的行为和稳定性。在不同的训练/测试子集进行评价。
最终的预测器可以序列化到磁盘,以便我们下次想使用它时,可以跳过所有训练直接使用训练好的模型:
In [46]:

加载的结果是一个与原始对象表现相同的对象:
In [47]:
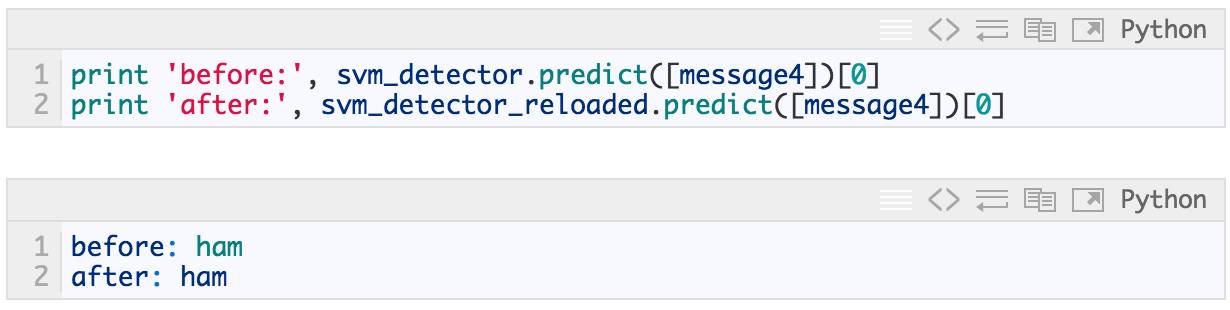
生产执行的另一个重要部分是性能。经过快速、迭代模型调整和参数搜索之后,性能良好的模型可以被翻译成不同的语言并优化。可以牺牲几个点的准确性换取一个更小、更快的模型吗?是否值得优化内存使用情况,或者使用 mmap 跨进程共享内存?
请注意,优化并不总是必要的,要从实际情况出发。
还有一些需要考虑的问题,比如,生产流水线还需要考虑鲁棒性(服务故障转移、冗余、负载平衡)、监测(包括异常自动报警)、HR 可替代性(避免关于工作如何完成的“知识孤岛”、晦涩/锁定的技术、调整结果的黑艺术)。现在,开源世界都可以为所有这些领域提供可行的解决方法,由于 OSI 批准的开源许可证,今天展示的所有工具都可以免费用于商业用途。
其他实用概念
数据稀疏性
在线学习,数据流
用于内存共享的 mmap,系统“冷启动”负载时间
可扩展性、分布式(集群)处理
无监督学习
大多数数据没有结构化。了解这些数据,其中没有自带的标签(不然就成了监督学习!)。
我们如何训练没有标签的内容?这是什么魔法?
分布假设“在类似语境中出现的词倾向于具有相似的含义”。上下文=句子,文档,滑动窗口……
查看 google 关于无监督学习的 word2vec 在线演示。简单的模型、大量数据(Google 新闻,1000 亿词,没有标签)。
下一步做什么?
这个 notebook 的静态版本(非交互版本)的 HTML,地址: http://radimrehurek.com/data_science_python (你可能已经在看了,但以防万一)
交互式 notebook 源文件在 GitHub 上,
http://radimrehurek.com/data_science_python/data_science_python.ipynb(见上面的安装说明)。
看完本文有收获?请转发分享给更多人
关注「大数据与机器学习文摘」,成为Top 1%











