在数据时代的今天,我们并不缺乏数据。如果问问企业的分析师,可能动辄整出来几十上百个变量是家常便饭。在许许多多的场景中,我们并不缺乏数据,也拥有大规模存储数据的能力。

但是,这些就足够了吗?我们可能缺乏的是对数据的理解。举一个栗子,我们想要预测熊大明天是不是变得更帅,需要考虑:他过去一段时间是不是一直在变帅?最近他是不是在运动?最近他写了几篇万字长文?收获了多少粉丝?心情怎么样?有没有身体倍儿棒,吃嘛嘛香?……好的,我们能想出许许多多的变量。但是我们发现,好像只有为数不多的几个变量对因变量(熊大有没有变更帅)有显著的贡献,其他变量基本可以忽略。那么,哪些变量是重要的呢?这就是变量选择讨论的问题。
上世纪20年代,生物技术的兴起带来了高维数据。人体的DNA上有数以万计的基因数据。哪些基因是致病基因?哪些是无关基因?这是生物学家感兴趣的问题。另一方面,由于成本等问题的限制,无法收集到很多样本并进行基因检测。高维数据分析应运而生。时势造英雄,变量选择方法随之变得更加重要。今天,我们来讲一下变量选择中一个非常经典的模型和实现——
Lasso
。
从英文的字面意思,Lasso含义是“(套捕马、牛等用的)套索”。统计学中的Lasso跟套马索没啥关系,它其实是个缩写,全称是
The Least Absolute Shrinkage and Selection Operator
。LASSO于1996年由Tibshrani发表于统计期刊Journal of the Royal Statistical Society (Series B)上。全文并不长,只有22页。作者可以说是艺高人胆大:这篇发表于著名统计学期刊的文章没有一个证明。有关Lasso理论性质的证明在之后被逐渐建立起来,感兴趣的读者可以阅读:“On Model Selection Consistency of Lasso”,文中给出了一个几乎充分且必要的条件,叫做“
不可表示条件
”。该条件限制了重要变量(也就是系数不为0的变量)与其他变量的相关关系。

图为Robert Tibshirani教授,现任斯坦福大学统计与健康研究与政策系教授。

图为1996年Lasso论文标题和摘要
在讲这个模型之前,我们先讲讲一个基本的假设,也就是这个模型的世界观是啥。这个假设就是:稀疏性假设。简单来说,我们认为,尽管世界如此复杂,但有用的信息却非常有限。套用到常见的统计学模型中,假如,我们考虑一个线性回归模型,有一个因变量Y,但有成百上千的自变量X。我们假设,只有有限个X的回归系数不为0,但其余的都是0。也就是说他们跟Y并没有啥子特别显著的关系。找到其中重要的X,对我们理解数据有重要的意义。对应前文的例子,生物学家想要研究基因对于某类疾病的影响,面对上万个可能的基因,生物学家们倾向于认为只有其中的一小部分对于该类疾病有着显著的影响;而为了预测消费者对于电影和书籍的喜好,线上电影和书店也倾向于认为一个消费者的喜好可以从少量的评分数据中得到。而“稀疏性假设”就是对于人们这种倾向的具体体现,举个例子,在分析基于和疾病的关系时,对于我们放入的10000个可能的基因,我们认为这10000个基因在回归模型中的回归系数只有少量的不为0。
在之前提到的高维变量和稀疏性假设的情况下,Lasso算法应运而生。
下面我们来说说Lasso的想法。Lasso相比于普通最小二乘估计,可以在变量众多的时候快速有效地提取出重要变量,简化模型。我们举一个线性回归的例子:隔壁老王卖耗子药生意越来越大,在经过一段时间销售后,他想知道耗子药销售量跟哪些因素有关。他考虑了这些因素:这个片区大概有多少耗子?卫生状况如何?片区是大叔大妈多还是年轻小两口多?有多少猫?耗子药广告应该投放在哪里?需要包括哪些关键词?……夜不能寐,越想越多。这些因素有的是“关键因素”,有的仅仅是打个酱油,与销量关系不大。对应到回归问题中:
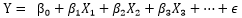
对应的自变量X的系数应取值为0,代表相应的自变量跟Y关系不大。Lasso就可以帮助我们得到。
现在一切听起来很完美,Lasso可以产生稀疏估计,让我们对这个世界的理解更进一步。但是,世界上没有免费的午餐:Lasso产生的是有偏估计。那我们实际得到了什么?Tibshirani 在他的原作中提出了两方面好处:
1、虽然最小二乘估计是无偏估计,但是在变量过多的情况下,往往带有较大的方差。我们再回味一下我们熟知的MSE(Mean Square Error)分解:
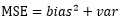
也就是MSE由偏差和方差两部分组成;这两部分很难“鱼和熊掌兼得”。 Lasso虽然是有偏估计,但是在引入一定的偏差的同时,可能可以大量降低估计的方差,从而降低整体的MSE。Lasso的优点不言而喻:如果我们拥有的样本信息是有限的,那么我们想要用有限的信息去估计过多的系数,此时信息很可能会出现不够用的情况,所以筛选变量提高估计效果十分必要。
2、对于最后得到的回归方程,我们需要在估计出每一个放入模型的自变量的系数后,能够更好地解释它。正如前面提到的例子,当得到稀疏估计之后,我们就能够明确得知:到底哪些因素对耗子药销量有显著的影响,从而调整商业决策。举个例子,假如发现卫生情况较差的小区耗子药销量较好,那就可以增加对应地方的库存,做好物流管理。
说了这么久Lasso的优点,那Lasso是如何实现这些优点的呢?从数学上,它有非常简单而优美的表达。我们先来看看Lasso的表达式:
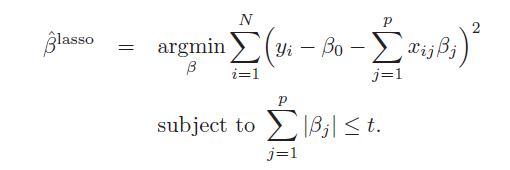
我们也可以用另一种常见的形式来表示:
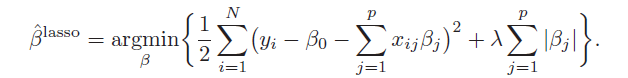
两个式子是等价的,但在实际应用中更多地提到第二个式子。在第一个式子中,第一行是我们熟知的OLS的目标函数,但在Lasso的估计过程中加上了第二行的限制条件,这个限制条件就对应与第二个式子中的第二项。t越小,或者
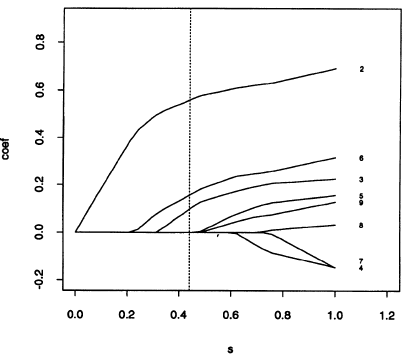
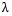 越大,对估计参数的压缩作用就越强。当我们对这个目标函数求最小时,一些不那么重要的自变量的系数将被压缩为0,从而达到筛选变量的作用。下面小编来详细介绍其筛选变量的原理。
越大,对估计参数的压缩作用就越强。当我们对这个目标函数求最小时,一些不那么重要的自变量的系数将被压缩为0,从而达到筛选变量的作用。下面小编来详细介绍其筛选变量的原理。
为了简单起见,我们可以以二维的情况为例,如左下图所示,图中椭圆表示上式第一项在
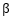 不同的取值时的图像(椭圆上的点取值相同),越靠近椭圆中心越优。而图中以原点为中心的正方形则表示满足一式第二行的限制条件的点集,所以我们也只能选取落入该正方形的点。最终Lasso的估计值为椭圆和下面矩形的交点,除非椭圆与矩形正好相切在矩形的某条边上,否则交点将落在矩形的顶点上,这时某参数的估计值将被压缩到0,即该变量已被剔除出模型。
不同的取值时的图像(椭圆上的点取值相同),越靠近椭圆中心越优。而图中以原点为中心的正方形则表示满足一式第二行的限制条件的点集,所以我们也只能选取落入该正方形的点。最终Lasso的估计值为椭圆和下面矩形的交点,除非椭圆与矩形正好相切在矩形的某条边上,否则交点将落在矩形的顶点上,这时某参数的估计值将被压缩到0,即该变量已被剔除出模型。
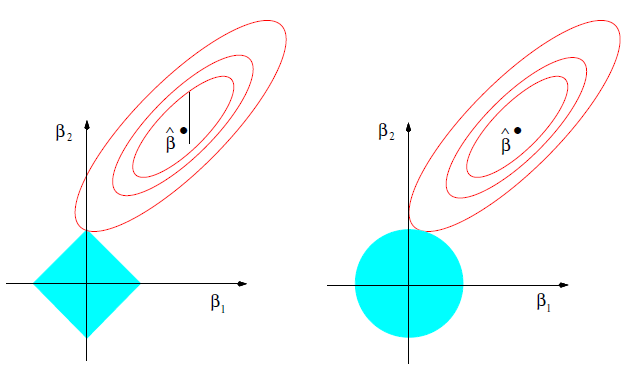
而右上角这幅图则是经常来来和Lasso进行对比的ridge regression,其表达式如下:
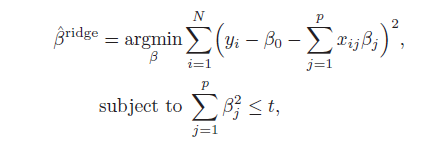
其与Lasso的不同在于第二行的限制条件,Lasso限制各系数绝对值之和,而ridge regression则是限制各系数的平方和,所以在二维的情况下,其可行域为以原点为圆心的圆,其最终的估计值也为不断扩大的椭圆与可行域的第一个交点。我们可以发现,由于可行域从矩形变成的圆,其交点将为椭圆与圆的切点,且难以刚好落在坐标轴上。这也使得ridge regression很多时候并不能将多余变量的系数压缩为0。
除了Lasso对应的L1惩罚以及ridge regression对应的L2惩罚,还有许多著名的惩罚函数。比如,在牺牲了惩罚函数凸性的情况下,一些non-concave的惩罚函数(如SCAD、MCP惩罚等)能够获得渐近无偏的估计,与之而来的是较高的计算成本,感兴趣的读者可以进一步阅读相关文献。
通过下面这幅图我们来了解一下Lasso筛选变量的动态过程,以及更直观地了解“压缩估计参数”的意思: