(点击上方公众号,可快速关注)
来源:fanjian0423,
fangjian0423.github.io/2014/09/26/mybatis-dynamic-sql%20/
如有好文章投稿,请点击 → 这里了解详情
前言
废话不多说,直接进入文章。
我们在使用mybatis的时候,会在xml中编写sql语句。
比如这段动态sql代码:
UPDATE users
name = #{name}
, age = #{age}
, birthday = #{birthday}
where id = ${id}
mybatis底层是如何构造这段sql的?
这方面的知识网上资料不多,于是就写了这么一篇文章。
下面带着这个疑问,我们一步一步分析。
介绍MyBatis中一些关于动态SQL的接口和类
SqlNode接口,简单理解就是xml中的每个标签,比如上述sql的update,trim,if标签:
public interface SqlNode {
boolean apply(DynamicContext context);
}
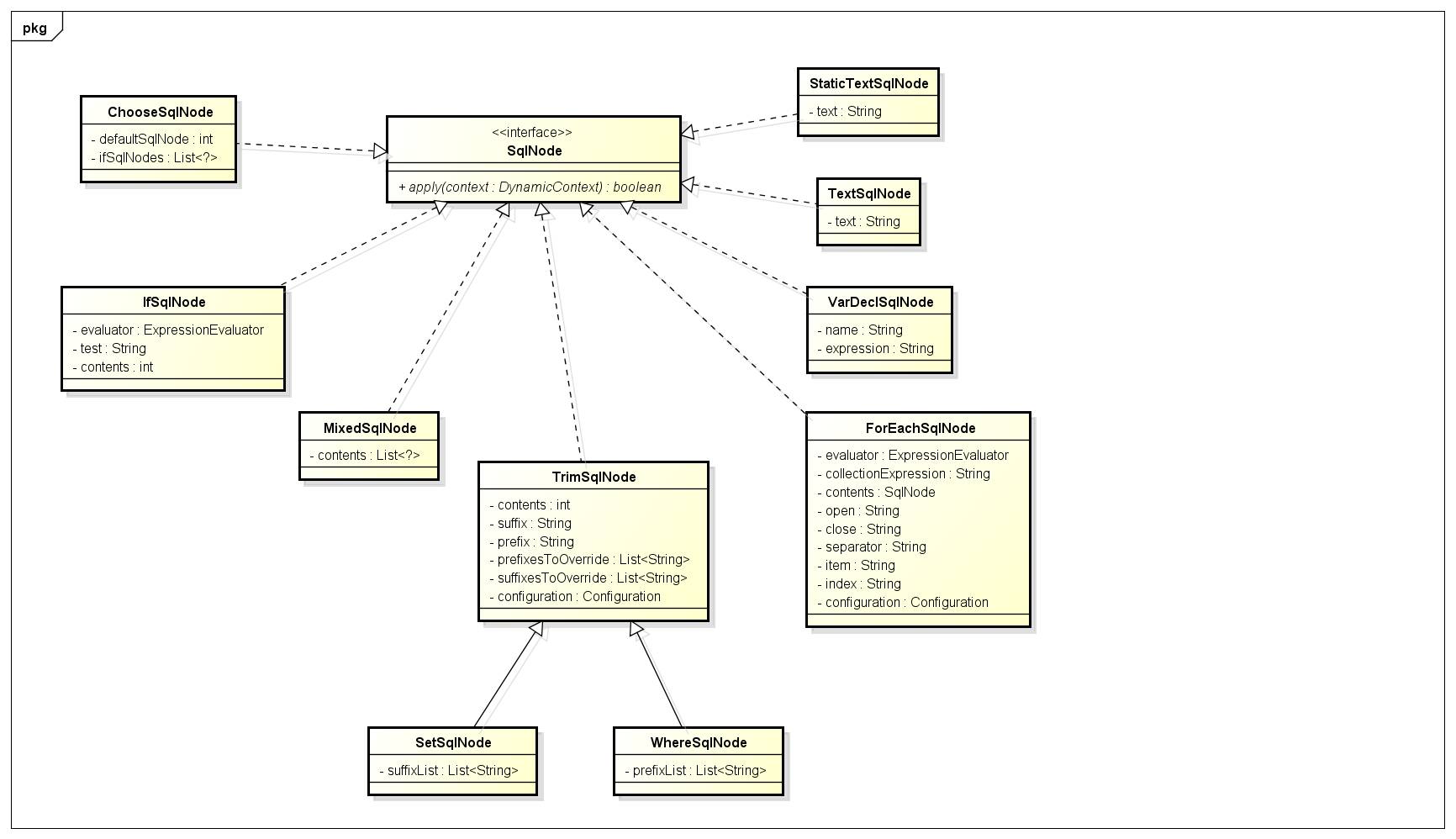
SqlSource Sql源接口,代表从xml文件或注解映射的sql内容,主要就是用于创建BoundSql,有实现类DynamicSqlSource(动态Sql源),StaticSqlSource(静态Sql源)等:
public interface SqlSource {
BoundSql getBoundSql(Object parameterObject);
}

BoundSql类,封装mybatis最终产生sql的类,包括sql语句,参数,参数源数据等参数:

XNode,一个Dom API中的Node接口的扩展类。
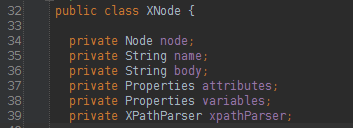
BaseBuilder接口及其实现类(属性,方法省略了,大家有兴趣的自己看),这些Builder的作用就是用于构造sql:
下面我们简单分析下其中4个Builder:
1 XMLConfigBuilder
解析mybatis中configLocation属性中的全局xml文件,内部会使用XMLMapperBuilder解析各个xml文件。
2 XMLMapperBuilder
遍历mybatis中mapperLocations属性中的xml文件中每个节点的Builder,比如user.xml,内部会使用XMLStatementBuilder处理xml中的每个节点。
3 XMLStatementBuilder
解析xml文件中各个节点,比如select,insert,update,delete节点,内部会使用XMLScriptBuilder处理节点的sql部分,遍历产生的数据会丢到Configuration的mappedStatements中。
4 XMLScriptBuilder
解析xml中各个节点sql部分的Builder。
LanguageDriver接口及其实现类(属性,方法省略了,大家有兴趣的自己看),该接口主要的作用就是构造sql:
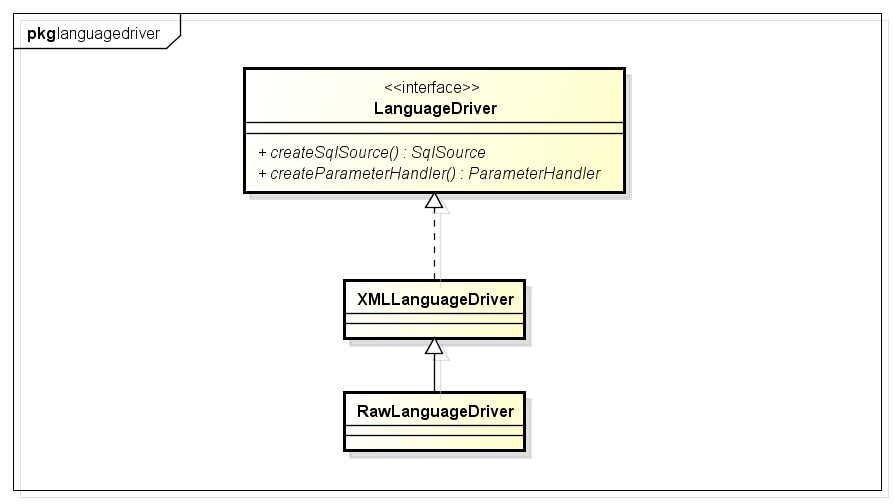
简单分析下XMLLanguageDriver(处理xml中的sql,RawLanguageDriver处理静态sql):
XMLLanguageDriver内部会使用XMLScriptBuilder解析xml中的sql部分。
ok, 大部分比较重要的类我们都已经介绍了,下面源码分析走起。
源码分析走起
Spring与Mybatis整合的时候需要配置SqlSessionFactoryBean,该配置会加入数据源和mybatis xml配置文件路径等信息:
我们就分析这一段配置背后的细节:
SqlSessionFactoryBean实现了Spring的InitializingBean接口,InitializingBean接口的afterPropertiesSet方法中会调用buildSqlSessionFactory方法
buildSqlSessionFactory方法内部会使用XMLConfigBuilder解析属性configLocation中配置的路径,还会使用XMLMapperBuilder属性解析mapperLocations属性中的各个xml文件。
部分源码如下:
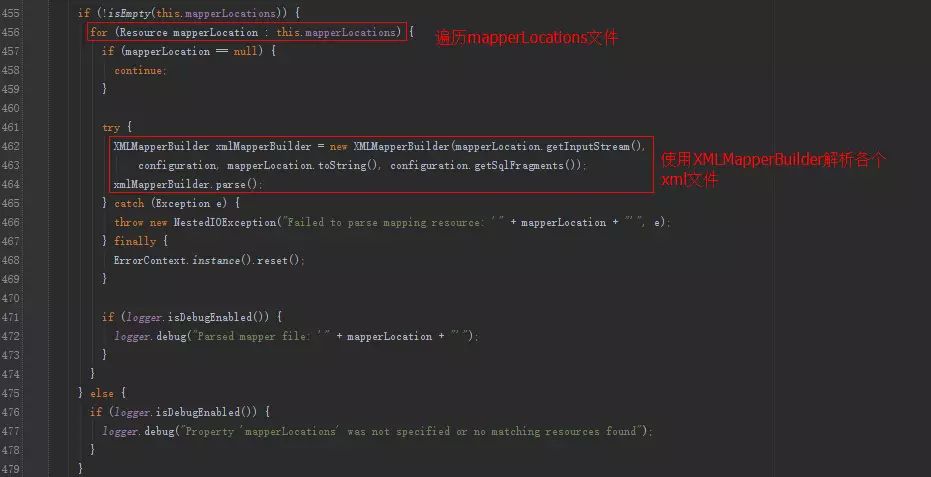
由于XMLConfigBuilder内部也是使用XMLMapperBuilder,我们就看看XMLMapperBuilder的解析细节。
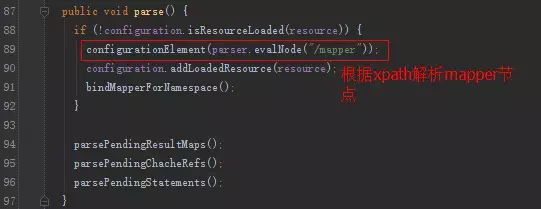
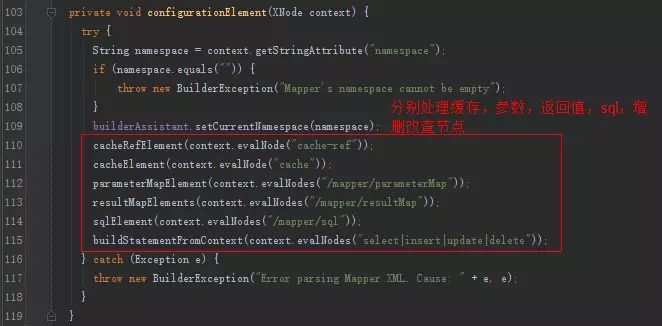
我们关注一下,增删改查节点的解析。
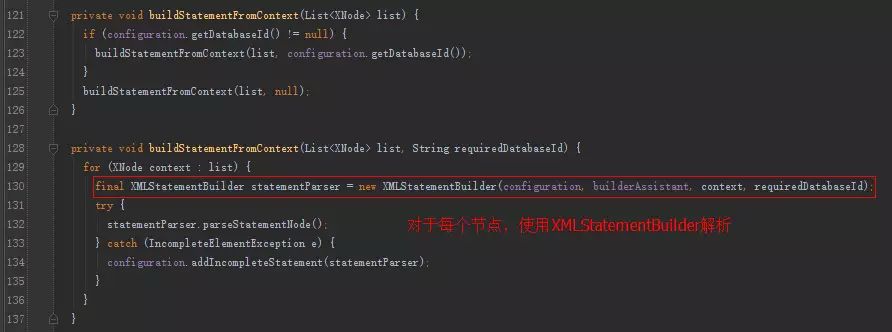
XMLStatementBuilder的解析:
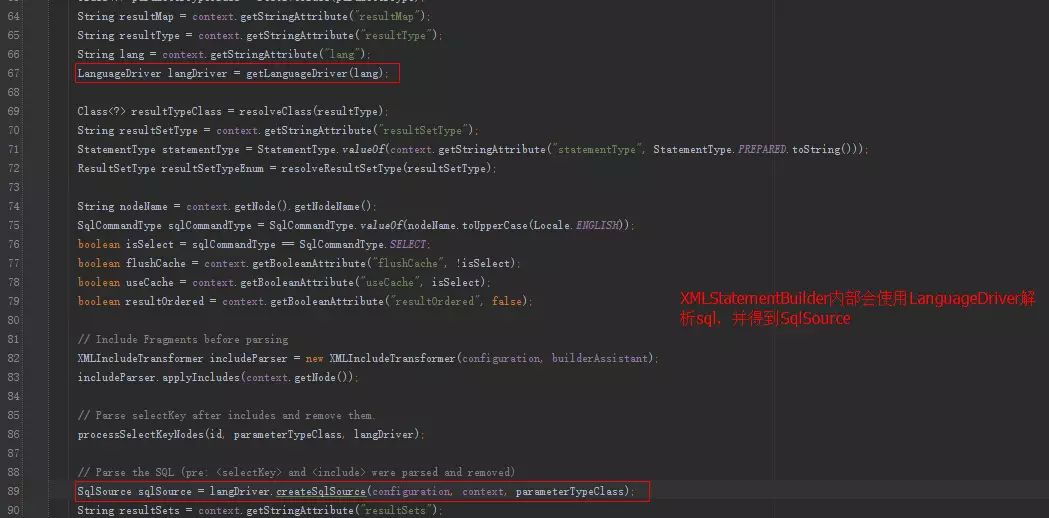
默认会使用XMLLanguageDriver创建SqlSource(Configuration构造函数中设置)。
XMLLanguageDriver创建SqlSource:

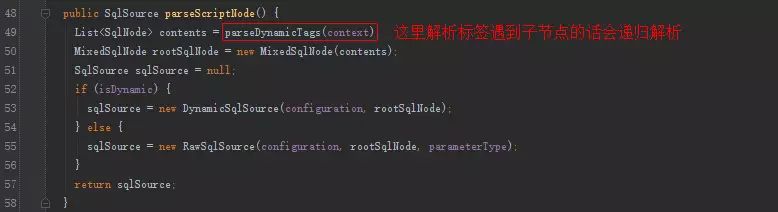
XMLScriptBuilder解析sql:
得到SqlSource之后,会放到Configuration中,有了SqlSource,就能拿BoundSql了,BoundSql可以得到最终的sql。
实例分析
我以以下xml的解析大概说下parseDynamicTags的解析过程:
UPDATE users
name = #{name}
, age = #{age}
, birthday = #{birthday}
where id = ${id}
parseDynamicTags方法的返回值是一个List,也就是一个Sql节点集合。SqlNode本文一开始已经介绍,分析完解析过程之后会说一下各个SqlNode类型的作用。
1 首先根据update节点(Node)得到所有的子节点,分别是3个子节点
(1)文本节点 \n UPDATE users
(2)trim子节点 …
(3)文本节点 \n where id = #{id}
2 遍历各个子节点
(1) 如果节点类型是文本或者CDATA,构造一个TextSqlNode或StaticTextSqlNode
(2) 如果节点类型是元素,说明该update节点是个动态sql,然后会使用NodeHandler处理各个类型的子节点。这里的NodeHandler是XMLScriptBuilder的一个内部接口,其实现类包括TrimHandler、WhereHandler、SetHandler、IfHandler、ChooseHandler等。看类名也就明白了这个Handler的作用,比如我们分析的trim节点,对应的是TrimHandler;if节点,对应的是IfHandler…
这里子节点trim被TrimHandler处理,TrimHandler内部也使用parseDynamicTags方法解析节点
3 遇到子节点是元素的话,重复以上步骤
trim子节点内部有7个子节点,分别是文本节点、if节点、是文本节点、if节点、是文本节点、if节点、文本节点。文本节点跟之前一样处理,if节点使用IfHandler处理
遍历步骤如上所示,下面我们看下几个Handler的实现细节。
IfHandler处理方法也是使用parseDynamicTags方法,然后加上if标签必要的属性。
private class IfHandler implements NodeHandler {
public void handleNode(XNode nodeToHandle, List targetContents) {
List contents = parseDynamicTags(nodeToHandle);
MixedSqlNode mixedSqlNode = new MixedSqlNode(contents);
String test = nodeToHandle.getStringAttribute("test");
IfSqlNode ifSqlNode = new IfSqlNode(mixedSqlNode, test);
targetContents.add(ifSqlNode);
}
}
TrimHandler处理方法也是使用parseDynamicTags方法,然后加上trim标签必要的属性。
private class TrimHandler implements NodeHandler {
public void handleNode(XNode nodeToHandle, List targetContents) {
List contents = parseDynamicTags(nodeToHandle);
MixedSqlNode mixedSqlNode = new MixedSqlNode(contents);
String prefix = nodeToHandle.getStringAttribute("prefix");
String prefixOverrides = nodeToHandle.getStringAttribute("prefixOverrides");
String suffix = nodeToHandle.getStringAttribute("suffix");
String suffixOverrides = nodeToHandle.getStringAttribute("suffixOverrides");
TrimSqlNode trim = new TrimSqlNode(configuration, mixedSqlNode, prefix, prefixOverrides, suffix, suffixOverrides);
targetContents.add(trim);
}
}
以上update方法最终通过parseDynamicTags方法得到的SqlNode集合如下:
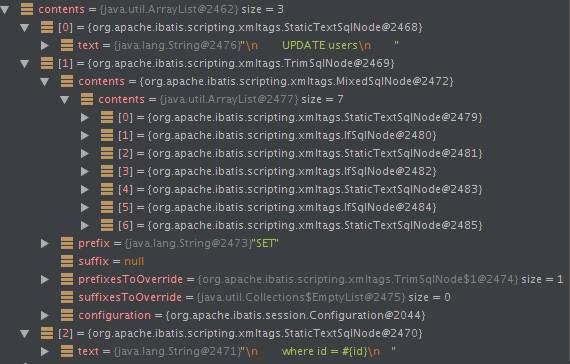
trim节点:
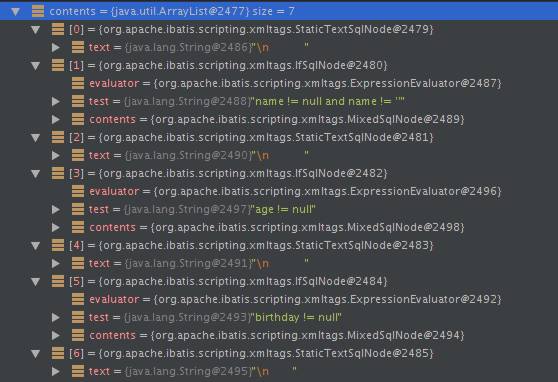
由于这个update方法是个动态节点,因此构造出了DynamicSqlSource。
DynamicSqlSource内部就可以构造sql了:
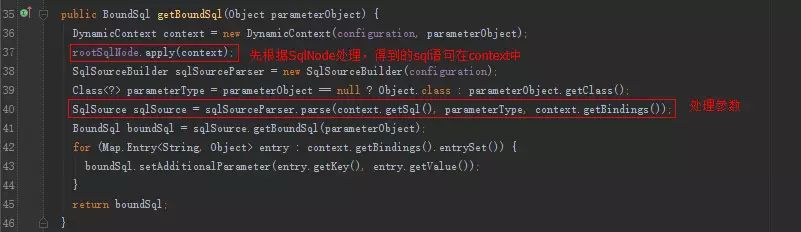
DynamicSqlSource内部的SqlNode属性是一个MixedSqlNode。
然后我们看看各个SqlNode实现类的apply方法
下面分析一下两个SqlNode实现类的apply方法实现:
MixedSqlNode:
public boolean apply(DynamicContext context) {
for (SqlNode sqlNode : contents) {
sqlNode.apply(context);
}
return true;
}
MixedSqlNode会遍历调用内部各个sqlNode的apply方法。
StaticTextSqlNode:
public boolean apply(DynamicContext context) {
context.appendSql(text);
return true;
}
直接append sql文本。
IfSqlNode:
public boolean apply(DynamicContext context) {
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}
这里的evaluator是一个ExpressionEvaluator类型的实例,内部使用了OGNL处理表达式逻辑。
TrimSqlNode:
public boolean apply(DynamicContext context) {
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
boolean result = contents.apply(filteredDynamicContext);
filteredDynamicContext.applyAll();
return result;
}
public void applyAll() {
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
if (trimmedUppercaseSql.length() > 0) {
applyPrefix(sqlBuffer, trimmedUppercaseSql);
applySuffix(sqlBuffer, trimmedUppercaseSql);
}
delegate.appendSql(sqlBuffer.toString());
}
private void applyPrefix(StringBuilder sql, String trimmedUppercaseSql) {
if (!prefixApplied) {
prefixApplied = true;
if (prefixesToOverride != null) {
for (String toRemove : prefixesToOverride) {
if (trimmedUppercaseSql.startsWith(toRemove)) {
sql.delete(0, toRemove.trim().length());
break;
}
}
}
if (prefix != null) {
sql.insert(0, " ");
sql.insert(0, prefix);
}
}
}
TrimSqlNode的apply方法也是调用属性contents(一般都是MixedSqlNode)的apply方法,按照实例也就是7个SqlNode,都是StaticTextSqlNode和IfSqlNode。 最后会使用FilteredDynamicContext过滤掉prefix和suffix。
总结
大致讲解了一下mybatis对动态sql语句的解析过程,其实回过头来看看不算复杂,还算蛮简单的。 之前接触mybaits的时候遇到刚才分析的那一段动态sql的时候总是很费解。
UPDATE users
name = #{name}
, age = #{age}
, birthday = #{birthday}
where id = ${id}
想搞明白这个trim节点的prefixOverrides到底是什么意思(从字面上理解就是前缀覆盖),而且官方文档上也没这方面知识的说明。我将这段xml改成如下:
UPDATE users
, name = #{name}
, age = #{age}
, birthday = #{birthday}
where id = ${id}
(第二段第一个if节点多了个逗号) 结果我发现这2段xml解析的结果是一样的,非常迫切地想知道这到底是为什么,然后这也促使了我去看源码的决心。最终还是看下来了。
看完本文有收获?请转发分享给更多人
关注「ImportNew」,看技术干货











