前段时间和朋友交流,我说从现在开始AI会是芯片技术进步的主要推动力。他问具体体现在什么方面,我说“方法,架构,实现和工具都会有吧”。后来我一直也在考虑这个问题,似乎可以更全面的回答一下。不过,讨论这么大的话题我也没什么把握,说的不对的,讲的不清的,或者说漏了的,请大家多指教。
现在说AI是未来人类技术进步的一大方向,相信大家都不会反对。说到AI和芯片技术的关系,我觉得主要体现在两个方面:
第一,AI的发展要求芯片技术不断进步
;
第二,AI可以帮助芯片技术向前发展
。
AI将成为芯片技术的主要驱动力
人工智能,特别是深度学习,这几年爆发性的发展,很大程度上得益于芯片技术多年的积累。如果不是芯片技术已经发展到了一定的高度,能够给大规模的机器学习提供足够的处理能力,我们肯定看不到战胜人类顶尖棋手的AlphaGo。可以说,过去十几年驱动芯片技术发展的主要是通信,多媒体和智能手机这些应用。不夸张的说,是苹果在赶着芯片产业往前跑。而随着这些应用增长放缓,相信未来赶着我们向前跑的主要会是各种AI的需求。当然,即使没有AI,芯片技术也会发展。这里我想和大家分享几个例子,个人感觉AI的驱动效应在这些技术上会有更明显的体现。
异构计算(Heterogeneous Computing)
按照Wikipedia的定义“
Heterogeneous computing refers to systems that use more than one kind of processor or cores. These systems gain performance or energy efficiency not just by adding the same type of processors, but by adding dissimilar coprocessors, usually incorporating specialized processing capabilities to handle particular tasks
”。首先,异构计算中使用多种类型的处理器是为了能够更好的提升整个并行处理系统的效率。比如下图就是高通的
Snapdragon 820芯片的框图,可以看出它包括了各种类型的处理器和硬件加速器。这还没包括软件栈的复杂度。
同时,异构计算又面临更多的挑战“
The presence of multiple processing elements raises all of the issues involved with homogeneous parallel processing systems, while the level of heterogeneity in the system can introduce
non-uniformity
in system development, programming practices, and overall system capability
.
” 简单来说也就是
不一致性
带来诸多问题。对于异构计算,Nvidia和AMD最早提出了一些标准的方法,主要面向在CPU+GPU的系统,比如CUDA和OpenCL。
目前来看,神经网络的Training使用CPU+GPU的硬件平台比较理想。而对于这类系统,Nvidia的CUDA已经做的很不错了。但对于一个Inference硬件平台来说,异构计算要复杂的多,除了CPU,GPU,系统里很可能还会有DSP,ASP,硬件加速器和FPGA这些硬件模块,以及相应的固件和软件。在这种环境下,如何有效的
发挥各类硬件的效率,提供统一易用的编程模型和软件接口
,就是个很大的问题。之前的很多尝试,比如OpenCL,HSA(Heterogeneous System Architecture) Foundation,都没能真正解决这个问题。而这个问题能不能解决,既是技术挑战,也有利益上的角力。Intel,Nvidia,AMD,Qualcomm,ARM都有自己的算盘,都想推自己的标准。不管怎样,在AI应用的驱动下,硬件平台的多样性和效率要求的挑战会越来越明显。整个产业对AI的热情能不能推动这个问题的解决,很值得关注。
DSC和DSA(Domain-Specific Computing/Architecture)
在最近的一个演讲中,当回答“
请问除了之前演讲中提到的以外,还有哪些处理器领域的未来趋势是值得关注的?
”这一问题时,计算机体系结构宗师David Patterson说到,“
我认为未来之星是深度学习领域的DSA处理器。深度学习的重要性我想在座的都很清楚。另外,使用更高级的设计描述语言,例如Chisel,来加速设计,也会成为趋势。
”我个人一直关注DSC领域,也基本同意Patterson的看法(Chisel的部分我不予置评)。道理也很简单,神经网络处理是一个新兴的特殊domain,而且是一个有足够体量来支持专门的方法学的domain。换句话说,在这个领域我们值得投入资源来实现一套完善的方法学,一旦成功会有巨大的回报。同时,这条路还很长,我们也还有足够的时间这么做。
不过,Domain-Specific Computing这个方向的提出也不是一天两天了,要实现它的愿景,确实需要做大量的工作
。它是一整套方法学,需要从设计语言到模型和工具的多方面支持。虽说我们都知道“工欲善其事,必先利其器”的道理,但在实践中,
我们
很多时候并没有这个耐心。希望AI能给这个“看起来很美”的方法学一个有力的推动吧。
Dataflow VS Controlflow
严格的说,Dataflow架构本来是计算机体系结构中实现并行计算的一种软硬件架构。有自己一套完整的方法学。下图摘自Shaaban教授的课程[2], 就是dataflow architecture的一个概述。
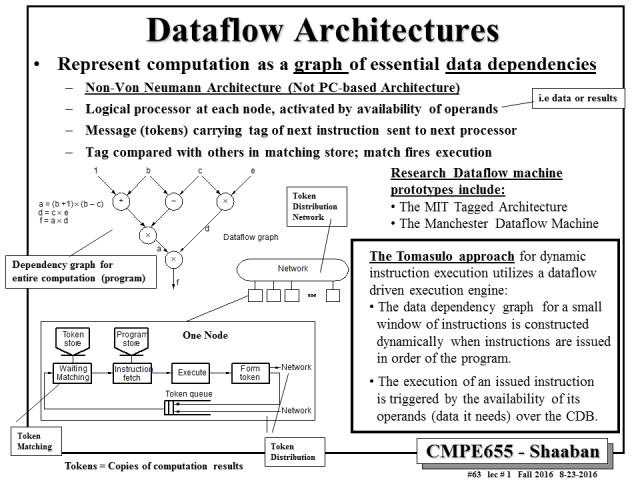
但是,如果我们看这种架构的主要特征:1. 没有PC(Program Counter),也就是说没有复杂的程序流控制;2. 节点的处理由操作数(availability of operands)激活。简单来说这种架构是
数据驱动
的。这一点和深度神经网络Inference的需求是非常一致的,因为神经网络是分层顺序处理的,有大量的数据处理,但不需要复杂的控制流程。这也是为什么我们现在看到的很多神经网络加速器的主要工作都放在了数据流的优化上。[1]中就指出“
For spatial architectures used in accelerators, we will discuss how dataflows can increase data reuse from low cost memories in the memory hierarchy to reduce energy consumption
.” GoogleTPU的脉动阵列
架构,虽然并不是个严格意义上的Dataflow Machine,但它也可是认为dataflow驱动的设计。
同时,Dataflow programming也是一种重要的编程模型。用Wikipedia的说法,就是“
dataflow programming is a programming paradigm that models a program as a directed graph of the data flowing between operations, thus implementing dataflow principles and architecture.
”。而我们知道,Google的TensorFlow深度学习框架就是一个“
open source software library for numerical computation using data flow graphs
”.
另外一个例子是做深度神经网络加速的Startup公司,Wave Computing(同时指出cloud的training和inference)[2],把他们的架构称作“A Coarse Grain Reconfigurable Array (CGRA) for Statically Scheduled Data Flow Computing” 。具体来讲,“
Wave uses a data flow computing on a hybrid coarse grain/fine grain reconfigurable array (CGRA) of processors in a Wave dataflow processing unit (DPU). In this model, data flows between software kernels, which are called data flow agents. Each agent is
compiled and statically scheduled across a reconfigurable array of data flow processing elements
. The entire data flow computation is
managed autonomously by the agents without the need for the control or memory of a host CPU
.
”
总的来说,dataflow驱动是深度神经网络的一大特点。因此在设计神经网络处理器的时候,其硬件架构和编程模型采用这些比较特殊的dataflow架构也是自然的选择。而目前很多神经网络硬件加速器的设计,也都借鉴了脉动阵列,CGRA(Coarse-Grain Reconfigurable Architecure)这些“古老”的技术。实际上,我们现在需要解决的问题(比如卷积运算的加速),并不是一个全新的问题,前人已经有了很完整的研究。虽然AI是个全新的应用,但它却给了很多老的架构和技术新的机会。这也是一个很有意思的现象。
Clockless设计
在Wave Computing的设计中还有一个很有意思的地方,就是采用了Clockless CGRA Synchronization,从而实现了“
In the large-scale CGRA, data flows between clusters of PEs at a
nominal frequency of 6.7 GHz
without the need for FIFOs used in other Globally Asynchronous Locally Synchronous(GALS) schemes
”。








