
最近看到身边好几个朋友都在用“全民K歌”这款软件在手机上K歌,使用频率还是很高,于是就想来看看全民K歌平台的用户究竟是一群什么样的用户?他们有什么样的特征。然后进行数据分析,强化自己的分析思维与实战能力。这一个过程我将会分为四个部分来写:数据获取,数据清洗,数据的呈现,分析报告的撰写。本文是第一部分。
进入用户的个人中心,下面的图中画方框的地方就是我们需要获取的数据:
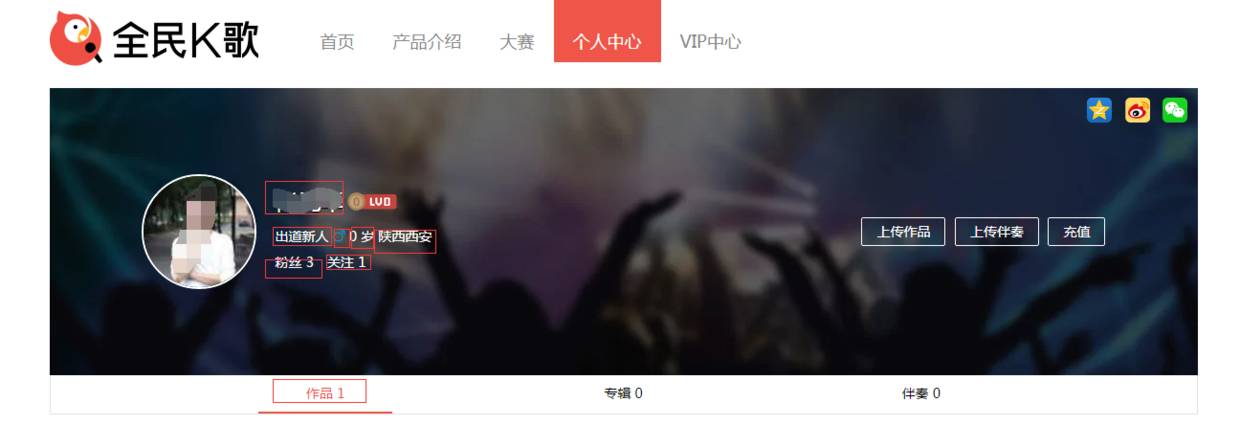
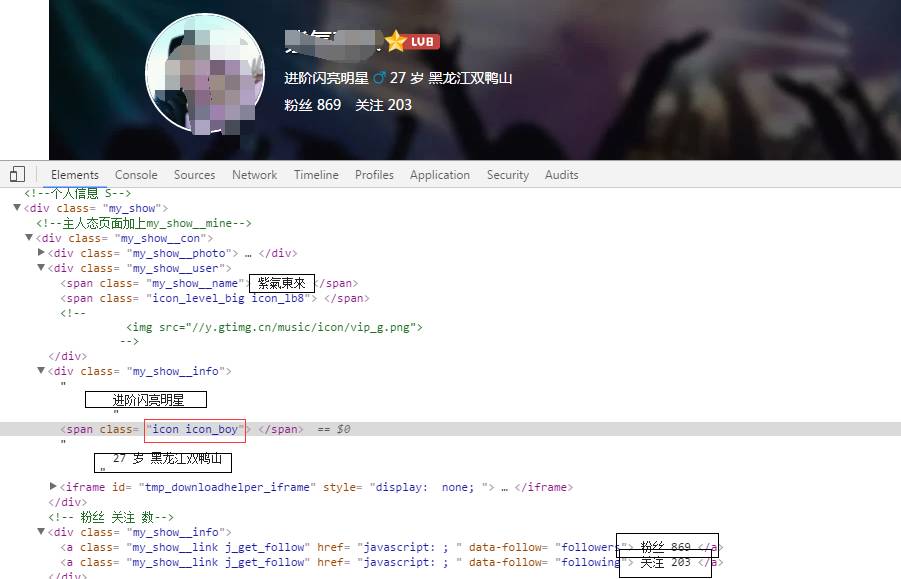
接下来我们看一下这些数据的存储方式,打开nt之后我们可以看见这些数据都存储在网页中,这样就非常容易获取了,这里需要注意的有两点:一个是年龄和地址,这两者需要在获取之后分开进行存储,便于后面分析(粉丝数,关注数也是同理);另外一点就是性别问题,在网页中我们没有发现直接指示性别的关键词,其实这里的性别是存放在画红色圈中的class的名字里面的“icon icon_boy”如果是女孩则是“icon icon_girl”,这里获取之后我们用split去掉无关字符,只取boy和girl关键词。
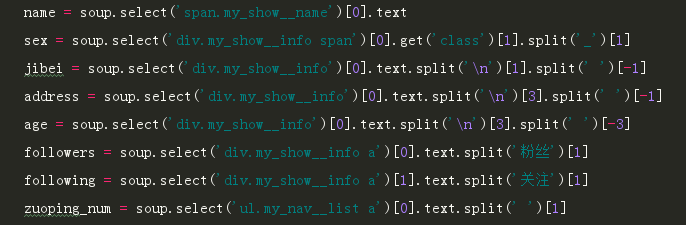
我们直接用BeautifulSoup来获取这些数据:
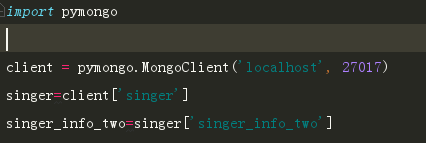
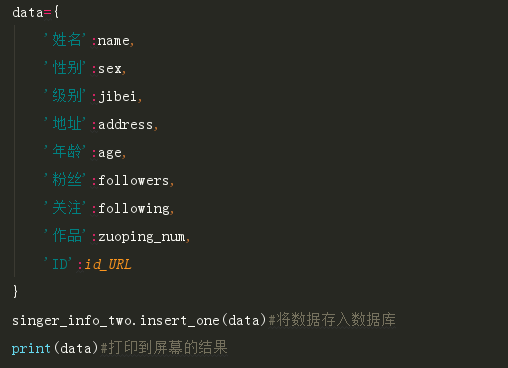
这些数据也就是我们最终需要的数据,我们将他们存放在Mongodb数据库中,以便于后面的分析与导出:
通过分析我们发现每一个用户的个人主页链接都仅仅只是ID不同,我们将这些ID也存放起来,方便后面获取这些用户所唱的歌曲,这个后面获取到id之后直接传回来就可以获得这个用户的个人信息了。
为了获得更多用户的数据,我们需要从用户A进入它的粉丝页面,获取粉丝的ID,然后再进入粉丝B的个人主页获取用户的信息,再从这些粉丝的主页获取他们的粉丝。类似一个递归的形式,思路是这样,但在后面实际运行的时候,python老师出错,个人感觉应该是堆栈溢出了,目前还是没有搞定,但是可以获取粉丝的二级列表,对于目前的分析来说,已经足够了。
在用户的粉丝页面我们看到用户的粉丝列表是逐步加载的,也就是异步加载的形式,我们就只能来抓包了。
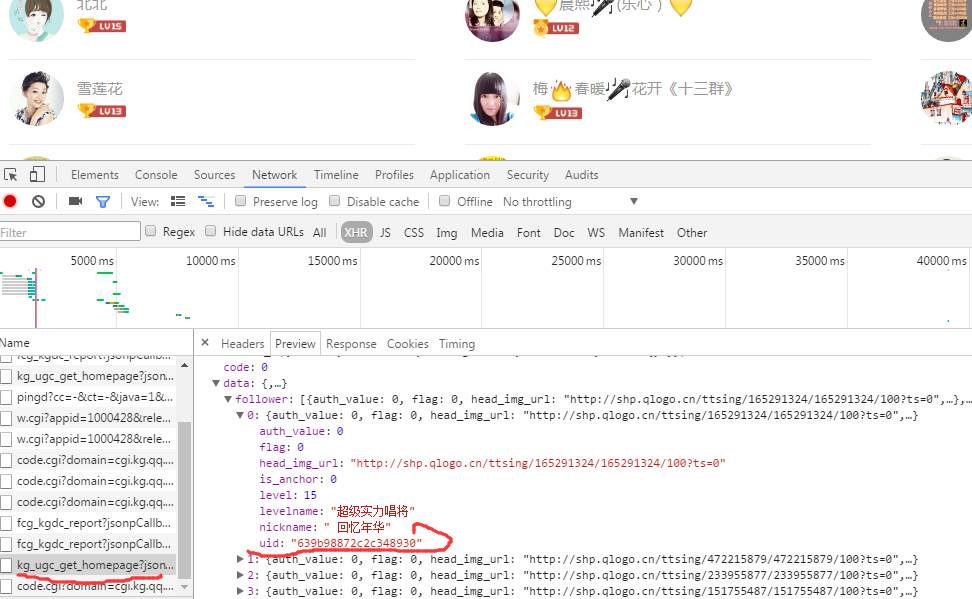
我们可以看见用户的粉丝数据是用json形式存储的,在每一次加载,一共加载20名粉丝的信息,这里我们只获取uid标签的值。接下来问题来了,我们获取的只是用户的前20名粉丝,如何获取其他的粉丝呢?方法肯定就是替换链接了,经过反复的查找,发现在已有的链接中每次加载变化的起作用的字段就是这个红色圈内的字段:

但是这样的一个数据是从哪里来的呢?如果是随机生成的就没有办法了获取下一级列表了。经过查找,我们发现这个last_tm的值在上一级的数据中存放着。这一下就好办了,只需要在第一次获取用户id的同时,将last_tm的值也同时获取下来,下一次加载时,直接掉用即可。

我们知道了如何分页,如何获取存储的数据,那么到底该循环多少次才能把所有的用户都获取下来呢?在最开始,我们已经知道了用户粉丝有多少,那么分多少也不就简单了。用粉丝数除以每页粉丝数20然后取整就是我们的循环次数了。
下面是获取用户粉丝的代码:
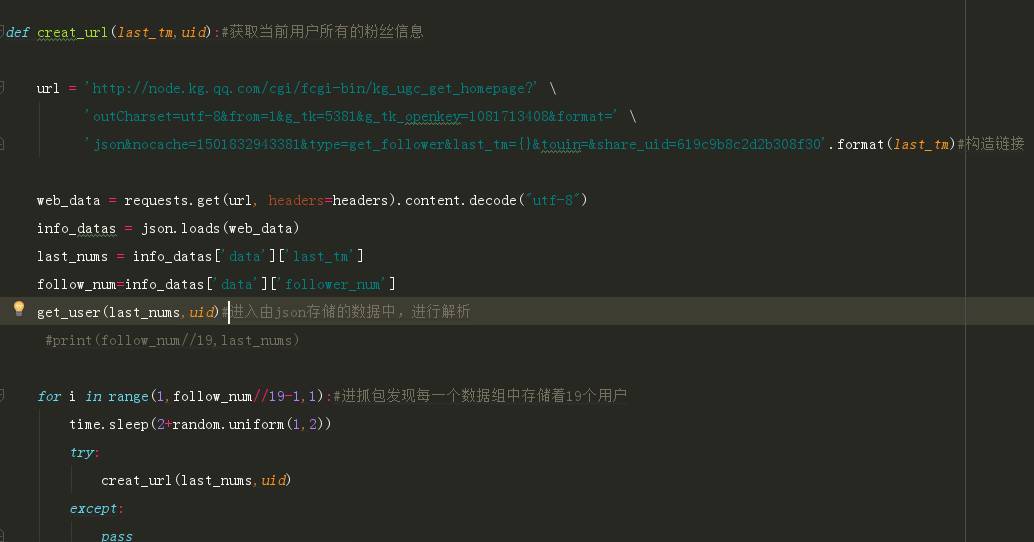
粉丝列表分页获取
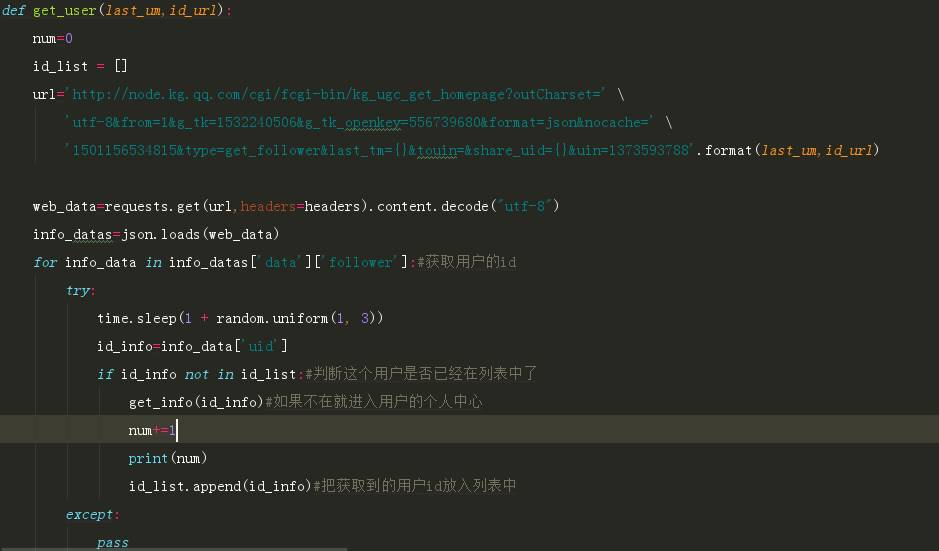
获取每一个粉丝的id

进入粉丝二级列表
最后一共只爬取了8671条用户数据,数据量还是比较少,但做分析之用,基本够了。

存储的数据




