36. 如果PC有异常,检查一下内存
我想在看了枚举类型的错误后,你肯定很累了。所以这次,让我们休息一会,不看代码了。
一个典型的场景——你们的项目没有正确运行。但你也不知道发生了什么。在这种情况下,我建议你不要急于去责备某个人,而应该把焦点放到你们的代码上。在99.9%的案例中,罪恶之源就是你们的开发团队中某个人引入了bug。通常这个 bug 都非常的愚蠢且平淡无奇。所以快点花点时间去找找。
实际上,这个一直出现的 bug 也不能说明什么。你可能只是遭遇了海森堡bug(Heisenbug)。
责备编译器也不是什么好主意。它当然也会出错啊,虽然真的非常少。比如说,你会发现就是仅仅错用了 sizeof(),这件事就会变得很棘手。我的博客里有篇博文就是关于它的:The compiler is to blame for everything。
但为了让记录更公正一点,我应该说,还是会有例外存在的。很少的情况下,bug 不对代码做什么。但我们还是应该注意到这种可能性的存在。这可以帮助我们保持理智。
我会用一个我曾经遭遇过的例子来证明这种可能性。非常幸运,我当时有截图。
当时,我在做一个简单的测试项目,想要去演示 Viva64 分析器(PVS-Studio 的前身)的功能,但是它没能正确运行。
经过漫长而令人讨厌的调查之后,我发现是一个内存槽引起这所有的问题。更确切地说,是1bit。你可以看看下面的照片,我当时正在调试,想往这个存储单元写入‘3’。
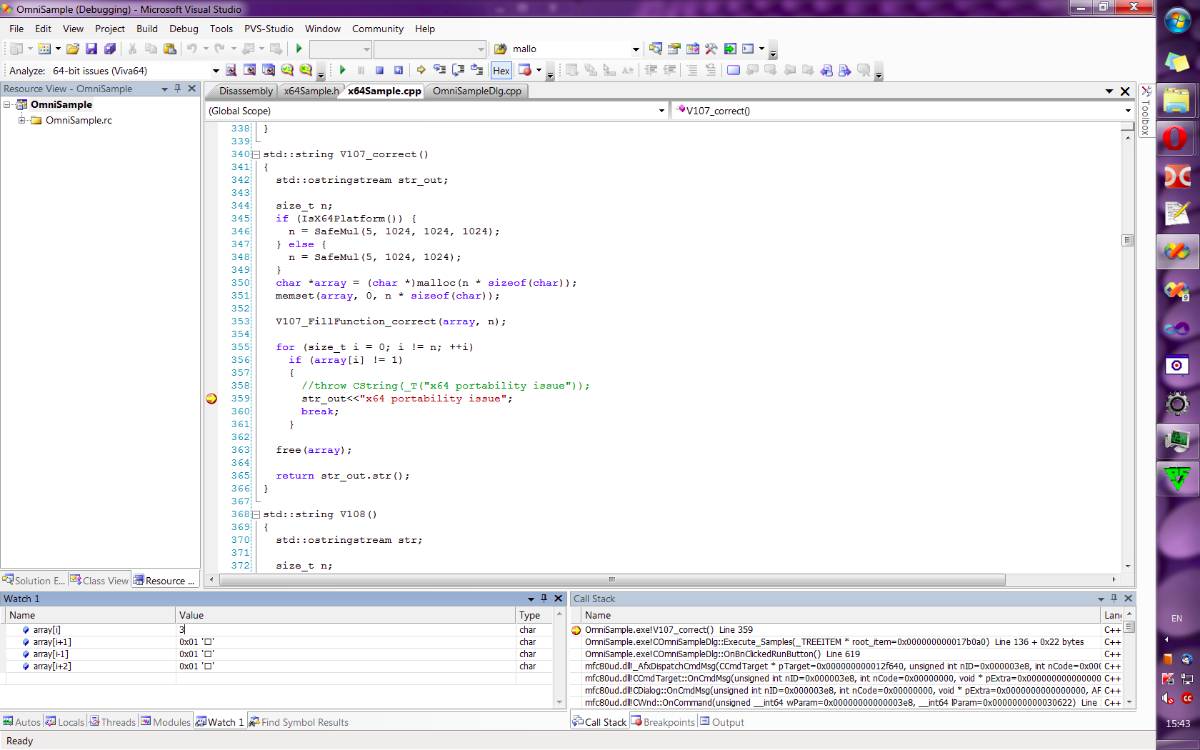
在改变内存之后,编译器开始读值并将其显示在窗口上,但它显示的是 2:看,地址是 0x02。尽管我已经把值设置为 3 了。低位总为 0。
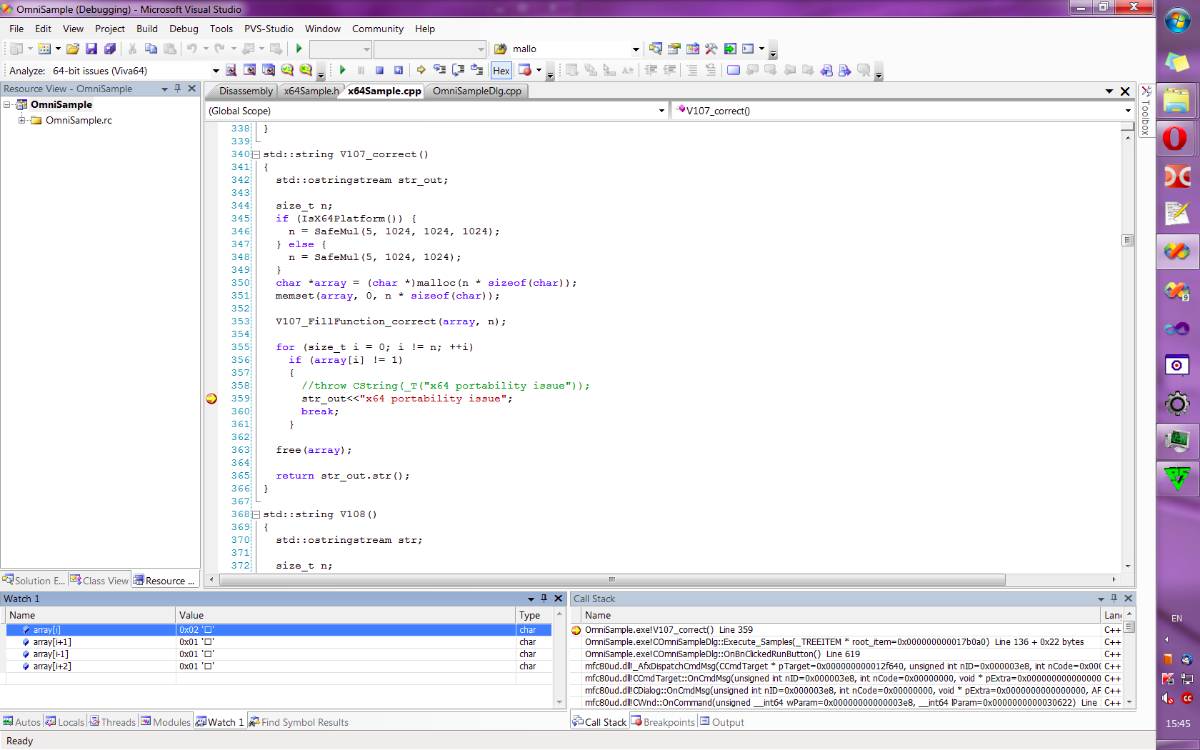
一个内存测试项目证实了这个问题。非常奇怪,这台电脑一直都工作得好好的,没出什么问题。最后为了让项目正确运行,我换了内存条。
我真的很幸运。当时我处理的是一个简单的测试项目。虽然我还是花了很多时间去了解发生了什么。我花了两个多小时去检查汇编器目录,想要找到引起这种奇怪行为的原因是什么。是的,我当时有因此责备编译器。
我无法想象,如果是一个实际的项目,我要花多大的时间精力去解决这个问题。谢天谢地,我当时不用去调试其他的东西。
建议
要时刻检查你代码中的错误。别想着推卸责任。
但是,如果一个 bug 只在你的电脑上出现,而且都快一周了。那么,可能不是因为你的代码。
要持续寻找 bug。但是在回家前,可以运行一个一整夜的 RAM 测试。或许,这个简单的测试步骤能节省你的时间精力。
37.要小心在do {...} while (...)里面的‘continue’操作
下面的代码来自 Haiku 项目(BeOS的继承者)。代码中包含的错误被 PVS-Studio 诊断为:V696. 'continue'操作会终止'do { ... } while (FALSE)' 循环,因为判断条件一直是 false。
do {
....
if (appType.InitCheck() == B_OK
&& appType.GetAppHint(&hintRef) == B_OK
&& appRef == hintRef)
{
appType.SetAppHint(NULL);
// try again
continue;
}
....
} while (false);
解释
在 do-while 循环里的 continue 的运作机制可能跟某些程序员想象的不一样。当遇到continue 的时候,会先要检查循环的终止条件。我想要更详细的解释这个问题。假设有个程序员写了这么一段代码:
for (int i = 0; i {
if (blabla(i))
continue;
foo();
}
或者是这样的:
while (i {
if (blabla(i++))
continue;
foo();
}
很多程序员凭直觉理解,当遇到 continue,就要(重新)评估控制条件(i),然后只有为真的时候才会进入下一个循环迭代。但,如果程序员的代码是这么写的:
do
{
if (blabla(i++))
continue;
foo();
} while (i
直觉就不起作用了哦。因为他们没有在 continue 上面看到判断条件,而且,似乎对于他们来说,continue 会马上触发下一个循环迭代。事情并非如此,continue 还是像它平常所做的那样——先重新评估控制条件。
除非踩了狗屎运,不然缺乏对 continue 的理解真的很难不出错。无论如何,如果循环条件 一直是 false,这个错误肯定会发生。因为在上面给出的代码中,程序员打算在之后的循环中执行特定的操作。代码中的注释“//try again ”证明了他们有这个意图。当然不会有‘again’啦,因为判断条件一直是false,而且一遇到 continue,循环就会终止哦。
换句话说,在这个do {...} while (false)结构中,continue 就相当于 break。
正确代码
要写正确代码有很多选项。比如,创造一个无限循环,然后用 continue 继续,用 break 退出。
for (;;) {
....
if (appType.InitCheck() == B_OK
&& appType.GetAppHint(&hintRef) == B_OK
&& appRef == hintRef)
{
appType.SetAppHint(NULL);
// try again
continue;
}
....
break;
};
建议
尝试着不要在 do { ... } while (...) 用 continue。即使你真的知道这是如何运作的。因为一不小心你就会犯这种错误,而且/或者你的同时就不能正确理解代码啦,最后把它错改。我一直都这么说:一个优秀的程序员不是知道并使用其他语言技巧的那一个,而是能够写出干净易懂的,即使新手也能理解的代码的那一个。
38. 从现在开始,用nullptr不要用NULL
新的C++ 标准引入很多有用的改变。有些我现在还没有用到,但是有些应该马上用起来,因为用它们有诸多益处。
其中一个现代化标准就是关键字nullptr, 其旨在代替 NULL 宏。
让我提醒你一下,在 C++ 中,NULL 的定义是 0 ,没有其他的了。
当然,看起来它好像就是一些语法糖(syntactic sugar)。那么当我们写 nullptr 或者 NULL 的时候,其中的区别是什么呢?真的有区别!用 nullptr 可以帮我们避免大量的错误。我将会用一些例子来证明。
假设有两个重载函数:
void Foo(int x, int y, const char *name);
void Foo(int x, int y, int ResourceID);
一个程序员可能会这么写函数调用:
Foo(1, 2, NULL);
然后那个程序员坚信自己这么做是在调用第一个函数。但因为 NULL 是 0 而非其他东西,然后0又是整形,所以其实调用的是第二个函数。
然而,如果程序员用的是 nullptr,就不会出现这样的问题,而且第一个函数也能正确调用。另一种比较常见的使用 NULL 的例子是这样的:
if (unknownError)
throw NULL;
在我看来,传一个指针到异常里面真的很奇怪。尽管如此,还是有人这么做。这样看来,那些程序员应该是这么写代码的。无论如何,关于这样写是好是坏的讨论已经超纲了。
最重要的是,那个程序员打算在处理未知错误的时候抛出一个异常,然后‘发送’一个空指针到外部世界。
事实上,这不是一个指针,而是一个整形。结果就是,异常处理的结果不像程序员所期望的那样。
"throw nullptr;"这行代码能让我们避免不幸,但是并不意味着我相信这样的代码能被接受。
在一些例子中,如果你用nullptr,不正确的代码就不会被编译。
假设有些 WinApi 函数返回一个 HRESULT 类型。HRESULT 类型没有能用来处理指针的东西。然而还是有可能会写出类似这种无意义的代码:
if
(WinApiFoo(a, b, c) != NULL)
这行代码能够编译,因为NULL 是 0,是一个整形,然后 HRESULT 是一个长整形。长整形和整形是可以比较值的。如果你有 nullptr,那下面的代码就不会编译。
if
(WinApiFoo(a, b, c) != nullptr)
因为编译错误,程序员就能够注意到并修改这行代码。
我想你已经明白我的意思了。有很多这样的例子。但大部分是人为的例子。而有的时候这种例子不那么有说服力。所以,有真实的例子吗?有的。这是其中一个。唯一的问题——它不是那么好看或者简短。
这个代码是来自MTASA项目。
所以,有 RtlFillMemory() 哈。这可以是一个真实的函数或者一个宏。没关系。类似于memset()函数,但第二第三个参数互换了位置。我们先来看一下这个宏是如何声明的:
#define RtlFillMemory(Destination,Length,Fill) \
memset((Destination),(Fill),(Length))
还有 FillMemory(),它跟 RtlFillMemory() 没什么区别:
#define FillMemory RtlFillMemory
是,一切都很长很复杂。但至少这是一个真实案例中的错误代码。
这里还有个用到了 FillMemory 宏的代码。
LPCTSTR __stdcall GetFaultReason ( EXCEPTION_POINTERS * pExPtrs )
{
....
PIMAGEHLP_SYMBOL pSym = (PIMAGEHLP_SYMBOL)&g_stSymbol ;
FillMemory ( pSym , NULL , SYM_BUFF_SIZE ) ;
....
}
这段代码有很多 bug。我们可以清晰的看到这里至少2到3个参数很混乱。这就是为啥分析器给出了两个警告 V575:
V575 'memset' 函数要处理”512“值。检查第二个参数。crashhandler.cpp 499
V575 'memset' 函数要处理”0“元素。检查第三个参数。crashhandler.cpp 499
代码可以编译是因为NULL是0. 结果就是0数组元素被填充。但实际上,问题不仅仅是这个。一般来说,NULL出现在这里是不合适的。memset()函数按字节处理,所以让内存充满NULL值没什么意义。这有点荒谬。正确的代码应该是这样:
FillMemory(pSym, SYM_BUFF_SIZE, 0);
或者这样:
ZeroMemory(pSym, SYM_BUFF_SIZE);
但还不是重点,重点是,这段没什么意义的代码会编译成功。然而,如果一个程序员已经养成了用 nullptr 不是用 NULL 的习惯,那他应该就会这么写:
FillMemory(pSym, nullptr, SYM_BUFF_SIZE);
这样的话,编译器就会给出一个错误信息,然后程序员就会意识到他们可能哪里出错了,然后就会更加注意他们编程的方式。
注意。我知道,在这个例子中,我们不能把一切都归咎于 NULL。但是也因为NULL,不正确的代码成功编译了,没有输出任何警告。
建议
开始使用 nullptr。从此刻开始。还有,在你的公司的编程标准中做必要的修改。
用 nullptr 会帮助你避免某些愚蠢的错误,然后就可以稍微加快开发进程。
39. 为什么不正确的代码也能运行
这个 bug 是在 Miranda NG 的项目中发现的。代码中包含的错误被 PVS-Studio 分析器诊断为:V502 可能'?:' 操作的结果和预期的有差。'?:' 的优先级低于'|'。
#define MF_BYCOMMAND 0x00000000L
void CMenuBar::updateState(const HMENU hMenu) const
{
....
::CheckMenuItem(hMenu, ID_VIEW_SHOWAVATAR,
MF_BYCOMMAND | dat->bShowAvatar ? MF_CHECKED : MF_UNCHECKED);
....
}
解释
我们有看到过很多例子,即使代码逻辑不对也能运行。这一次,我想提出一个不一样的、发人深思的话题来讨论。有时我们会看到完全不正确的代码很偶然的,即使困难重重,还是运行了。现在,对于有经验的程序员来说,这没什么好惊讶的(这是另一个故事了),但对那些C/C++的初学者来说,这就有点令人感到困惑了。所以,今天我们来看看这样的例子。
在上面给出的代码中,我们需要调用带有一定标志的 CheckMenuItem(); 而且,猛地一看我们会觉得,如果 bShowAvatar 是 true,那就做或运算 MF_BYCOMMAND | MF_CHECKED,相反的,如果是 false,就是 MF_BYCOMMAND | MF_UNCHECKED。很简单。
在上面给出的代码中,程序员选用了最意料之中的三元运算符来表达这个意思(这个表达式是 if-then-else 的简便版本):
MF_BYCOMMAND | dat->bShowAvatar ? MF_CHECKED : MF_UNCHECKED
但问题是,‘|’的优先级高于‘?: ’的(参看C/C++中的运算优先级)。这样就导致了一下子有两个错误。
第一个错误是,条件改变了。它不再是——像某人可能理解的——"dat->bShowAvatar",而是"MF_BYCOMMAND | dat->bShowAvatar"。
第二个错误——只剩下一个标志可以选择——不是MF_CHECKED 就是MF_UNCHECKED.标志MF_BYCOMMAND已经缺失了。
尽管有这些错误,代码还是正确运行了!原因——踩了狗屎运。那个程序员很幸运,因为标志MF_BYCOMMAND等于0x00000000L。而因为MF_BYCOMMAND等于0,所以最后没有影响到代码。可能一些有经验的程序员已经知道我想要表达的意思了,但我还是再做写解释吧,以便初学者理解。
首先,让我们看一眼加了括号的正确表达式。
MF_BYCOMMAND | (dat->bShowAvatar ? MF_CHECKED : MF_UNCHECKED)
然后用具体的值来代替宏:
0x00000000L | (dat->bShowAvatar ? 0x00000008L : 0x00000000L)
如果‘|’的其中一个操作数是0,那么我们就可以简化上面的表达式,得到:
dat->bShowAvatar ? 0x00000008L : 0x00000000L
现在我们再来看原先那个不正确的表达式:
MF_BYCOMMAND | dat->bShowAvatar ? MF_CHECKED : MF_UNCHECKED
把具体的值代入:
0x00000000L | dat->bShowAvatar ? 0x00000008L : 0x00000000L
在子表达式"0x00000000L | dat->bShowAvatar" 中,其中一个操作数是0。简化可得:
dat->bShowAvatar ? 0x00000008L : 0x00000000L
最后,我们得到了相同的表达式,这就是为什么有错误的代码还是能正确运行了。又一个编程奇迹发生了。
正确代码
有很多种方法来修正这段代码。其中一种就是加括号,另一种——加一个中间变量。还有比较老的 if 运算也是可以的:
if (dat->bShowAvatar)
::CheckMenuItem(hMenu, ID_VIEW_SHOWAVATAR,
MF_BYCOMMAND | MF_CHECKED);
else
::CheckMenuItem(hMenu, ID_VIEW_SHOWAVATAR,
MF_BYCOMMAND | MF_UNCHECKED);
我其实并不坚持让你用这个方法来修正代码。这样看上去是更易读了,但是有点长。所以,这更多的是偏好的问题。
建议
我的建议很简单——避免使用太复杂的表达式,尤其是三元运算符。还有,别忘了加括号。
就像在第四章已经说过的,‘?: ’这个运算真的很危险。有的时候一疏忽你就忘了它的优先级非常的低,然后你就会写一个不正确的表达式。人们会在他们想要阻塞一个字符串的时候用到它,所以,你别这么做。
40. 开始使用静态代码分析
读了那么长一篇由静态代码分析器开发者所写的文章,却没有看到关于使用它的建议,是不是很奇怪。所以我们现在就讲这个。
下面的代码选自 Haiku 项目(BeOS 的继承者)。代码中包含的错误被 PVS-Studio 诊断为:V501.'表达式左右两边的操作数是一样的:lJack->m_jackType
int compareTypeAndID(....)
{
....
if (lJack && rJack)
{
if (lJack->m_jackType m_jackType)
{
return -1;
}
....
}
解释
这是一个很常见的拼写错误。在右边应该是 rJack,然后被错写成了 lJack。
这个拼写错误实际上是很简单的一种,但这种情况真的蛮复杂的。因为无论是编程风格,或者是其他的方法,在这里都无济于事。有的时候就是在拼写的时候犯了个错误,对此,你能做什么呢?
要特别强调说这不是某个人或者项目的问题。无疑,世人皆会出错,即使是在重大项目中的专业人员也会。这是关于我这个言论的证明。你可以看到最简单的拼写错误,诸如A == A,在Notepad++, WinMerge, Chromium, Qt, Clang, OpenCV, TortoiseSVN, LibreOffice, CoreCLR, Unreal Engine 4等等这些项目中出现。
所以这个问题是真实存在的,而且这不是学生的实验课作业。当有人跟我说,有经验的程序员是不会犯这样的错误的时候,我一般都会把这个链接甩给他们。
正确代码
if
(lJack->m_jackType m_jackType)
建议
首先,让我们先来讲几个不那么有用的小贴士。
那么,有用的建议呢?
代码审查
单元测试(测试驱动开发「TDD」)
静态代码分析
我应该说,每一种方法都有各自的强处和弱处。这就是为什么要写出最高效可靠的代码是把它们都用起来。
代码审查能帮我们找到大量的,不同的错误,而且最重要的是,它可以帮我们提高代码的可读性。但不幸的是,分享式阅读(Shared reading)代码有点昂贵、无聊而且不会保证正确性。很难一直保持警惕,然后在阅读这种代码的时候发现拼写错误:
qreal l = (orig->x1 - orig->x2)*(orig->x1 - orig->x2) +
(orig->y1 - orig->y2)*(orig->y1 - orig->y1) *
(orig->x3 - orig->x4)*(orig->x3 - orig->x4) +
(orig->y3 - orig->y4)*(orig->y3 - orig->y4);
理论上,单元测试应该能帮到我们。但仅仅是理论上。在实际中,检查所有可能的运行路径是不现实的。而且,测试本身也会有一些错误 :)
静态代码分析仅仅是个程序,而非人工智能。分析器可能会跳过一些错误,有时还会误报,就是其实代码是正确的,但它弹出了错误信息。尽管有这些缺点,它还是一个很有用的工具的。在编写代码的早期,它可以检测到很多错误。
静态代码分析器也可以用做便宜版本的代码审查。让代码分析器而不是程序员来检查代码,也可以让它更全面的检查某一代码片段。
当然,我会推荐使用 PVS-Studio 静态代码分析器,这是我们开发的。额,这世上并非只有这一款。还有很多免费或付费的工具可以使用。比如说,你可以看看免费开放的 Cppcheck 分析器。维基百科上也给出了一系列静态代码分析器的单子:List of tools for static code analysis。
注意:
如果不正确使用静态代码分析器,可能会让你有点头疼。最典型的错误之一就是“把检查模式选项设为最大值,然后就陷入大量的提示信息之中。”我能给出的众多建议中的一个就是,为获得更多选项 ,去看看A, B会有用的。
静态分析器的使用应该有个界限,不是一直使用,或者当遇到问题的时候使用。参看C, D 的解释。
真的,尝试着去使用静态代码分析器。你会喜欢它的。它是一个非常好的工具。
最后,我推荐阅读 John Carmack 的文章:静态代码分析。
41. 避免在项目中引入新的库
假设你要在你的项目中实现X功能。软件开发理论家会说,你要用已经存在的库Y来实现你需要的功能。事实上,这是软件开发中一个典型的方法——重用你自己或者其他人之前已经创建好的库(第三方库)。然后大多数程序员也用这个方法。
但是,在一些文章或书籍中那些理论家忘了说,用某些第三方库近10年会有多悲剧。
我非常建议避免在项目中增加新的库。但是也别误解我。我不是让你丝毫都不用库,自己去实现所有的功能。这当然很没必要啊。但有时有些程序员心血来潮,想要往项目里加点‘cool’的特性,然后就引入了新的库。难的不是往项目里加新的库,而是从此以后整个项目要不得不带上它。
追溯几个大项目的演化,我看到了很多有第三方库引起的问题。我可能只会列举其中的一些,但这个单子已经能够引发我们的思考了:
引入新的库会立即增加项目的大小。在我们这个有快速互联网和大型SSD驱动的时代,这当然不是什么大问题。但当从版本控制系统下载时间从1变成10的时候,这就令人有点不快了。
即使你只用到了库功能的1%,你还是得把它整个都导入到项目中。结果就是,如果这些库是用是在编译模块使用的(比如,DLL),分布大小会很快增长。如果你把库当作源代码使用,那编译时间会大大增长。
跟项目的编译(compilation)连接的设备也会变得更复杂。有些库需要额外的组件。一个简单的例子:我们需要用 Python 来编译链接成目标文件(building)。结果就是,有时你需要很多额外的程序才能创建这个项目。而且有些地方会出错的几率也会上升。这很难解释,你需要自己去经历。在大项目中,有的地方就是一直运行不起来,你就得花很大的精力去解决它,让所有的一切都能正常编译运行。
如果你有担心漏洞,你要时常更新第三方库。那些违反者(violator)应该对这个很有兴趣,研究代码库寻找漏洞。首先,很多库都是开源的,其次,如果发现了其中一个库的弱点,你可以写一个exploit去利用那些用到这个库的应用程序。
那些库有可能突然就改变了许可证类型。第一,你要将这件事时刻放在心上,还要保持跟进。第二,如果真的发生了,你要做什么其实也不太清楚。比如说,有一次,广泛使用的 softfloat 库从个人协议移到了BSD。
在升级编译器的版本的时候你会遇到困难。肯定会有一些库没有跟新的编译器兼容,那你只能等了,或者你自己连接那个库。
在移到不同的编译器上的时候,你也会遇到问题。比如说,你以前用的是 Visual C++,现在打算用 Intel C++。可定会有一些库出错。
在移到不同平台的时候,也会遇到问题。有的时候甚至不是一个完全不同的版本。比如说,你打算把一个 Win32 应用程序移到 Win64 上。你就会遇到同样的问题。最可能的是,有些库没准备好,你要想要怎么处理他们。最令人不悦的就是,有些库根本就不开发了,也没有更新它了。
或早或晚,如果你用了很多C 库,它们的类不是放在命名空间(namespace)的,你就会遇到命名冲突(name clash)。这就会引起编译错误,或者隐藏错误。比如说,某个它用的枚举常量和你打算用的冲突了。
如果你的项目已经用了很多库,再增加一个一个也不会造成多大危害。我们可以用破窗效应来比喻。但结果是,一直增长的项目会变成无法控制的混乱。
引入新的库还有很多我没注意到的缺点。但无论如何,额外的库会增加项目支撑的复杂性。有些问题就会出现在它们最意想不到的地方。
我应该在一次强调,我不是说应该停止使用第三方库。如果我们要处理PNG格式的 图像,我们就应该用 LibPNG 库,而不是再重新写一个。
但即使我们要处理 PNG,我们也应该停下来想想。我们真的需要引入一个库吗?我们要用这张图片来做什么?如果任务只是要把一张图片存为*.png 文件,我们可以使用系统函数。比如说,如果你是在写一个Windows应用程序,你可以用WIC。而且如果你已经用了MFC 库,你就没有必要让代码变得更复杂了,因为MFC 里面有CImage 类。(参看 StackOverflow 里的讨论)。少用了一个库——真棒!
让我跟你讲一个我实际遇到的例子。在开发 PVS-Studio 分析器的过程中,我们需要在几个诊断中用一些简单的正则表达式。一般来说,我觉得静态分析器不是用正则表达式的好地方。这是一个非常低效的方法。我甚至写了一篇关于这个话题的文章。但有时你就得用正则表达式来在一个字符串了找些东西。
是可以加一个库啦,但很明显,它们都很冗余。同时,我们还是得用到正则表达式,所以我们要想办法。
非常偶然的,我那个时候在读《代码之美》(ISBN 9780596510046)。这本书是关于简单漂亮的解决方法的。然后我就看到了一种很简单的实现正则表达式的方法。就只用简单的十几行。这就是我所寻找的!
我决定在 PVS-Studio 中用这个实现方法。你知道吗?这个实现方法对我们来说够用了,复杂的正则表达式对我们来说不是必需的。
结论:我们没有引入新的库而是花了半个小时来写需要的功能。我们克制住了再用一个库的欲望。而且事实证明,这是一个很正确的决定。时间证明了我们真的不用那个库。我说的不是几个月,我们用那个功能用了超过五年呢。
这个例子让我坚信,越简单的解决方案越好。通过避免引入新的库(若可以),你的项目会更简单的。
读者可能会对查找正则表达式的代码感兴趣。我会把它摘抄出来。看,多漂亮。这段代码在整合进 PVS-Studio 的时候做了些许的改变,但主要思想还在。那么,这就是书上的代码啦:
// regular expression format
// c Matches any "c" letter
//.(dot) Matches any (singular) symbol
//^ Matches the beginning of the input string
//$ Matches the end of the input string
# Match the appearance of the preceding character zero or
// several times
int matchhere(char *regexp, char *text);
int matchstar(int c, char *regexp, char *text);
// match: search for regular expression anywhere in text
int match(char *regexp, char *text)
{
if (regexp[0] == '^')
return matchhere(regexp+1, text);
do { /* must look even if string is empty */
if (matchhere(regexp, text))
return 1;
} while (*text++ != '\0');
return 0;
}
// matchhere: search for regexp at beginning of text
int matchhere(char *regexp, char *text)
{
if (regexp[0] == '\0')
return 1;
if (regexp[1] == '*')
return matchstar(regexp[0], regexp+2, text);
if (regexp[0] == '$' && regexp[1] == '\0')
return *text == '\0';
if (*text!='\0' && (regexp[0]=='.' || regexp[0]==*text))
return matchhere(regexp+1, text+1);
return 0;
}
// matchstar: search for c*regexp at beginning of text
int matchstar(int c, char *regexp, char *text)
{
do { /* * a * matches zero or more instances */
more instances */
if (matchhere(regexp, text))
return 1;
} while (*text != '\0' && (*text++ == c || c == '.'));
return 0;
}
是的,这个版本非常简单,但要不是它这几年来我们就得用更复杂的方法啦。这段代码的功能是有限的,但也不需要加其他更复杂的代码了,我也不觉得会有这样的代码。这是一个非常好的例子,说明一个简单的方案可以比复杂的方案做得更好。
建议
不要急于往项目中引入新的库,只有在非它不可的时候才引入。
这里有一些变通的方法:
看看你们系统的API或者已经用的库是否也有需要的功能。研究这个问题真的是一个好主意。
如果你只是用库里面很少的一部分功能,自己去实现会比较好。引入一个库来“以防万一”实在没有必要。几乎可以肯定的是,这个库再将来也不会用到太多。程序员有的时候就是想要一个并不需要的普遍性。
如果还有其他法子来解决你的问题,选能够满足你要求的并且最简单的那一个。就像我先前说的,摒弃那种想法“这个库好酷哦,我们引入它来以防万一吧。”
在引入新的库之前,坐下来想想。甚至可以休息一会儿,喝杯咖啡,和你的同事讨论一下。可能你就会意识到你可以用一种完全不同的方法来解决这个问题,而不需要使用第三方库。
P.S. 我这里讲的这一个观点可能并不能被每一个人所接受。比如说,实际上我会推荐用WinAPI,而不是一个通用的可移植库。可能会有人反对,因为这么做就把这个项目和一个操作系统‘绑’在一起了。这样要移植项目就会很困难。我不同意这种观点。很多时候,“稍后我们会把它移植到其他操作系统上”这种观点只是存在于程序员的脑海里而已。对于管理者而言,这个任务并不是必须的。另一种观点——程序可能会因为其复杂性和一般性在它受到欢迎以及有必要移植之前就翘辫子了。还有,不要忘了上面列出的第八个问题。
42. 不要用以“empty”命名的函数
代码选自 WinMerge 项目。代码中包含的错误被 PVS-Studio 诊断为:V530 要用到函数‘empty’的返回值。
void CDirView::GetItemFileNames(
int sel, String& strLeft, String& strRight) const
{
UINT_PTR diffpos = GetItemKey(sel);
if (diffpos == (UINT_PTR)SPECIAL_ITEM_POS)
{
strLeft.empty();
strRight.empty();
}
....
}
解释
这个程序员是打算清空 strLeft 和 strRight 这两个字符串。它们都是 String 类型,String 类型跟 std::wstring 非常像。
出于这个这个目的,他调用了empty() 函数。但这样是不对的。empty() 不会改变该对象,只是返回该字符串是否为空。
正确代码
要修正这个代码,你应该用 clear() 或者 erase() 取代 empty()。WinMerge 开发者更喜欢 erase(),所以现在代码是这样的:
if (diffpos == (UINT_PTR)SPECIAL_ITEM_POS)
{
strLeft.erase();
strRight.erase();
}
建议
在这个例子中"empty()" 真的不合适。因为在不同的库中,这个函数代表着两种不同的操作。
在一些库中,"empty()" 函数是清除对象。在其他库中,它返回对象是否为空的信息。
我想说的是‘empty’这个词本身就很有歧义,每个人对它的理解都不同。有人会认为这是一个“动作”,也有人会认为这是一个“信息查询”。这就是原因。
只有一个解决方法。不要在类名中用‘empty’。
如果你认为这不是什么大问题,那么请看这里。这是影响力比较广的错误。当然,要改变类似std::string这样的类有点迟了,但最少我们可以不让错误继续流传下去。
结论
希望你喜欢这个小贴士集。当然,不可能把所有关于没写好代码的东西都写下来,而且也没意义。我的目的是想提醒程序员,让他们有一种忧患意识。可能,下一次当某个程序员遇到某些奇怪的事,他能想起我的这些小贴士,然后就不慌张了。有时,花几分钟去研究文档或者写简单/干净的代码就能够避免隐藏的错误,不让这个错误在之后的几年内造成你的同事或用户的痛苦。
原文链接:https://software.intel.com/en-us/articles/the-ultimate-question-of-programming-refactoring-and-everything
本文由 看雪翻译小组 lumou 编辑
往 期 阅 读:
C++编程的 42 条建议(五)
C++编程的 42 条建议(四)
C++编程的 42 条建议(三)
C++编程的 42 条建议(二)
.......
更多优秀文章点击左下角“关注原文”查看!

看雪论坛:http://bbs.pediy.com/
微信公众号 ID:ikanxue
微博:看雪安全
投稿、合作:www.kanxue.com








