(和上面一段合并)回报函数能够辅助学习如何在环境中行动。
通过理解算法的优点与不足,以期实现开发更高效的算法这一目标。强化学习拥有着广泛的应用前景,包括人工智能、控制工程,或者运筹学,等等。而上述这些也都与开发自动驾驶汽车息息相关。

在自动驾驶技术中,机器学习算法主要任务即不间断监控周围环境,并预测将会发生的变化。这类任务又能进一步划分为:
于此相对应的机器学习算法大致又会分为四类:
决策矩阵算法
,
聚类算法
,
模式识别算法
和
回归算法
。每一类算法都可被用于完成两个或多个任务。例如,回归算法可以用于物体定位以及物体检测和行动预测上。
决策矩阵算法能够系统分析、确定并评估信息集和价值集之间的关联表现。这类算法主要用于决策。车辆在行驶中是否需要刹车或是向左转,就是基于算法对于识别、分类和物体行动预测的置信水平下所做的决策。决策矩阵算法模型由许多独立训练的决策模型所组成,最终预测结果也由这些模型的预测结汇总组成,这会大大降低决策出错率。AdaBoosting就是该类型中最常用到的算法。
适应性增强,或者说AdaBoost,是由不同的可用于回归和分类的学习算法所组成。相较于其他机器学习算法,它能克服对于异常值和噪声敏感的过拟合问题。为了创造一个复合的强力学习器,AdaBoost利用了多次迭代,具有更强的适应性。通过迭代式地加入弱学习器,AdaBoost创造了一个强学习器。一个新的弱学习器会被附于整体,然后通过调整各学习器的权重向量来让算法更多关注上一轮迭代时错误分类的数据。最终我们会获得一个比弱学习器精准得多的分类器。
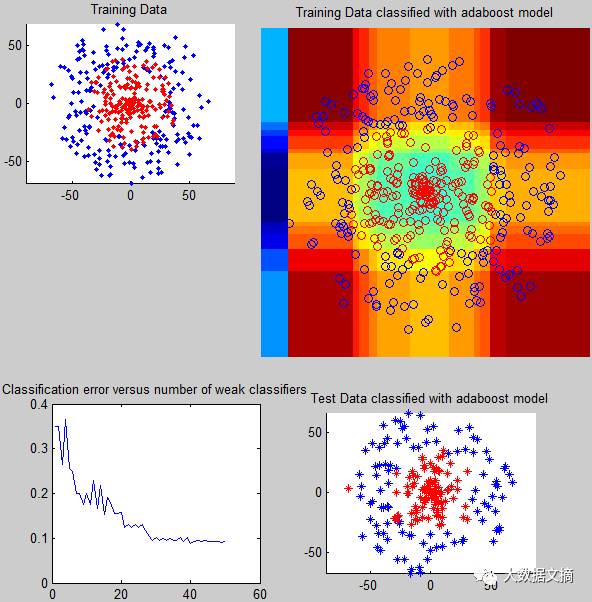
AdaBoost可以增强一个弱的阀值分类器到一个强的分类器。上面的这张图描述了这一实现过程。函数由弱学习器和增强组分构成。弱学习器尝试在某单一维度确定理想分类阀值来分开两类数据。而在增强阶段,该基础分类器被不断迭代式地调用,每一步分类之后,算法改变错误分类数据的权值。由于此,一串弱分类器能表现得像一个强分类器。
有时,会出现系统获得的图像不清晰,难以定位、检测物体。还会有些情况,分类算法没检测到物体,系统分类汇报失效。引起上述问题的原因可能是不连续的数据,不足量的数据点或是低分辨率的图片。
聚类算法就专门用于发掘数据中的结构。它描述了像回归一样一类的算法。它由层级结构和中心结构所组织起来。所有的方法利用了数据的内生结构使得同组数据有最大的共通之处。K-均值,层次聚类是最常用的算法。
K-均值是著名的聚类算法。K-均值算法储存了定义相应簇的k个中心点。如果某一个点离某个中心点最近,那么就被分到那一簇中去。算法在当前数据集各簇分布来选择新的簇中心和根据簇中心重新分配数据点之间交替迭代。
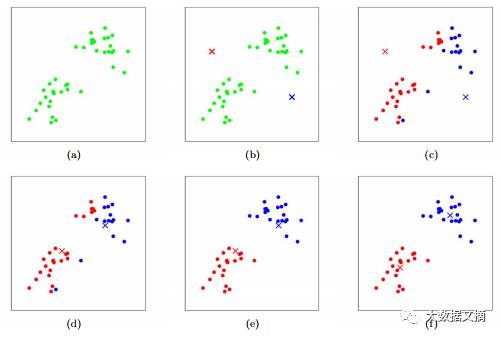
K-均值算法图示-叉表示簇中心,点表示数据点。(a)原始数据集;(b)随机初始簇中心;(c-f)K-均值算法两次迭代的演示。每次迭代中,每个训练点被归为离对应簇中心最近的簇中,之后簇中心被更新为该簇所有点的均值。
先进驾驶辅助系统(ADAS)中传感器获得的图片由各种环境数据所组成。为了确定图像中物体的类别,需要通过去除无关数据点进行图像滤波。在分类物体之前,数据集中模式的识别是至关重要的一步。这类算法被定义为数据降维算法。数据降维算法通常可以用于减少数据集中物体的边和多段折线(拟合线段),以及圆弧 。到一个角之前,线段按边来排列,一个新的线段在这之后开始。圆弧按线段序列排列,类似一条弧。图像的特征(圆弧和线段)以许多方式组合在一起,并被加以利用决定了一个物体。
伴随主成分分析和方向梯度直方图,支持向量机是ADAS中最常运用的识别算法。K近邻和贝叶斯决策规则也会被使用到。
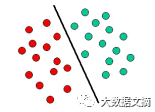
支持向量机是基于定义决策边界的超平面概念。超平面划分了数据集中不同类别的数据点。下图是一个例子。其中,一类物体被标记为绿色,另一类为红。一条边界区分了红色和绿色的物体。任一个落入左边的物体将会被标记为红色,右边的则是绿色。
这类算法可应用于预测。回归分析会寻求两个或更多变量之间的关联,收集并结合不同尺度间变量影响。这个过程通常由以下三种度量驱动:
相机和雷达图像在ADAS系统中驱动和定位方面扮演着重要的角色。无论何种算法,面对的最大挑战都是开发一个可实现基于图像选择特征和预测的模型。
回归算法利用环境的可重复性,创建出可描述图像中物体位置和物体关联的统计模型。再通过图像采样,可实现快速在线检测和离线学习;这些也可以被扩展到不需要大量人力建模的情形中。作为一个在线阶段的输出,算法给出一个物体的位置和一个物体出现的置信水平。
回归算法也可被用于短期预测,长期学习。决策树回归,神经网络回归,贝叶斯回归等回归算法则可被用于自动驾驶汽车中。
神经网络被用于回归,分类和无监督学习中。它将未标记的数据分组,监督学习之后分类数据,预测连续的数据值。神经网络最后一层通常使用逻辑回归将连续的数据值转变为0或1的变量。
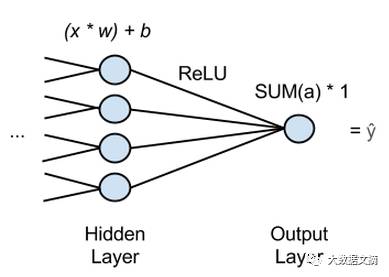
上图中,‘x’ 是输入,上一层传来的特征。许多x会被传入到最后一个隐层的节点上,并且每一个x会乘上对应的权值w。加上一个常数项后,这些乘积的和会进入一个激活函数。激活函数之一是ReLU(线性整流函数),由于不会像Sigmoid激活函数那样在前几层神经网络使得梯度饱和,而被广泛使用。ReLU对每一个隐层节点提供了输出激活函数,所有激活函数相加后进入输出节点。这意味着,一个神经网络进行回归时包含了单一输出节点,该节点的值则是上一层的激活函数输出值之和乘以1。结果是网络的估计
。
是所有输入x映射到的相关变量。以这种方式使用神经网络,你可以获得你试图预测的从x(一些不相关的变量)到y(相关变量)的函数。









