
爱撒谎的男孩,Python中文社区专栏作者
博客:https://chenjiabing666.github.io
准备工作
首先在淘宝女郎的首页这里查看,当然想要爬取更多的话,当然这里要查看翻页的url,不过这操蛋的地方就是这里的翻页是使用javascript加载的,这个就有点尴尬了,找了好久没有找到,这里如果有朋友知道怎样翻页的话,麻烦告诉我一声,谢谢了…,不过就这样坐以待毙了吗,所以就在chrome上搜,结果看到有人直接使用的这个网页,我当时一看感觉神奇的样子,这就是简化版的首页啊,只需要改变page的数字就可以实现遍历了,不过还是有点小失落,为什么人家就能找到呢,这个我还是希望知道的朋友能够分享一下,我也会查看相关的资料,把这个空缺不上的,好了,现在开我们的工作了
我们的目的是抓取册以及相关的信息,所以我们需要随便打开一个淘女郎的相册页面,然后随便进入一个相册即可,很显然这里的相册是异步加载的,因此我们需要抓包,这里我抓到了含有相册的url以及相关信息的json数据,如下图:
然后我们查看它的url为

通过我尝试之后这条url可以简化为:

其中user_id是每一个女郎对的id,ablum_id时每一个相册的id,这里一个女郎有多个相册,因此这个id是不同的,但是page就是要翻页的作用了,可以看到我去掉了callback=json155这一项,因为如果加上这一项,返回的数据就不是json类型的数据,其中page是在抓包的时候点击翻页才会在下面出现的,可以看到同一个相册返回的除了page不同之外,其他的都是相同的,因此这里通过page来实现翻页的数据
上面分析了每一个相册的url数据的由来,可以看到我们下面需要找到user_id,ablum_id这两个数据.
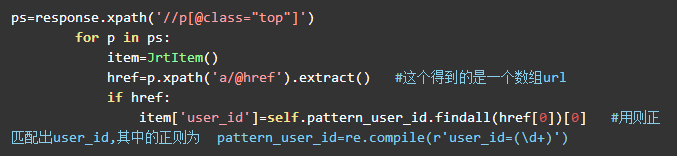
user_id的获取:我们打开首页,然后打开chrome的调试工具,可以看到每一个 女郎的url中都包含user_id这一项,因此我们只需要通过这个实现翻页然后获取每一个女郎的url,之后用正则将user_id匹配出来即可,代码如下
ablum_id的获取:想要获取ablum_id当然要在相册的页面查找,于是我们在相册页面抓包获得了如下图的页面
通过上图我们清晰的知道每一个相册的里面包含多少相册,但最令人开心的是在这个页面中不是动态加载,因此我们可以查看它的源码,当我们查看源码的时候,我们可以看到和user_id一样,这里的ablum_id包含在了href中,因此我们只需要找到每一张相册的url,然后用正则匹配处来即可,其中这个页面的url简化为:

所以我们可以通过上面得到的user_id构成请求即可,代码如下:

上面已经获得了user_id和ablum_id,那么现在就可以请求每一个相册的json数据了,这个就不用多说了,详情请看源代码
MongoDB存储
安装方式
Windows下安装请看我的MogoDB干货篇
ubuntu直接用sudo apt-get install安装即可
安装对应python的包:pip install pymongo
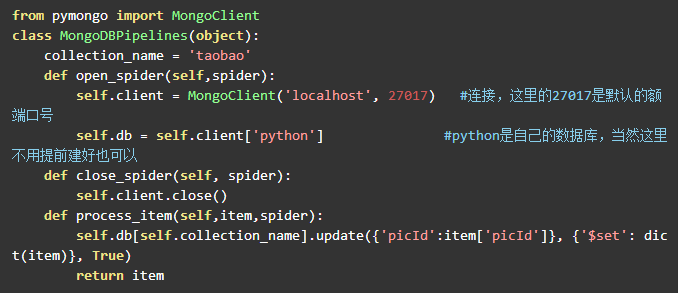
安装完成以后就可以连接了,下面贴出我的连接代码
现在这就算好了,当然这里还有很多东西需要优化的,像代理池。。。最后本人想在暑期找一个地方实习,但是一直没有好的地方,希望有实习的地方推荐的可以联系我,在这里先谢谢了
推荐
最后推荐博主的一些项目源代码,请长按下方二维码关注“未来Store”,回复关键词“源码”获取下载链接及密码
1、源码:scrapy爬取妹子网站实现图片的存储
2、源码:scrapy爬取知乎用户的详细信息

Python 中 文 社 区
Python中文开发者的精神家园
合作、投稿请联系微信:
pythonpost
— 人生苦短,我用Python —
1MEwnaxmMz7BPTYzBdj751DPyHWikNoeFS
本文为作者原创作品,未经作者授权同意禁止转载









