
哈喽宝子们,馆长又上线啦!
内卷新实力,双非院校0实验发表14分+的NC期刊,你见过嘛?
此前馆长也解读过很多的热点高分文章,也见过很多大佬团队的创新思路展示,但今天解读的这篇文章属实是震撼到馆长啦!
不仅紧跟诺奖热点,还提出了更加新颖的思路设计,完美贴合科研,为临床宝子打开了“新世界”的大门,接下来就让我们一起来品读一下吧~
实际上蹭热点无可厚非,但是如果将热点与现实科研问题紧密结合,开拓新颖的实验思路,并转化为高分文章,才是“难”点!
今天馆长分享的这篇来自于上海科技大学团队发表的研究论文就是完美诠释,
该研究系统地对12种用于癌症合成致死性(SL)预测的机器学习方法进行了基准测试,
评估了它们在不同数据拆分场景、负样本比率和负采样技术在分类和排名任务中的表现,为选择合适的方法和开发更强大的SL虚拟筛查技术提供了指导。整体上算是机器学习的扩展研究啦!(
PS:现阶段实验条件有限的宝子建议考虑一下生信分析思路啦!成本低时间短,绝对香!如需协助选题,可联系馆长哦~)
最重要的是,
该研究不仅选题新颖,研究思路清晰,它代码还公开,这真是为临床宝子的复现铺好了道路,
就这你难道还不心动嘛?那么接下来就让我们来看看这篇文章是如何实现14分+的NC期刊的~
PS:蹭热点容易想,但做起来却不容易!不仅需要给审稿人留下刻意蹭流量的感受,还需要贴合现实科研问题!对于想短期发表高分文章的临床宝子来讲,这篇文章绝对是可借鉴的“高分模板”!如果你也对复现此类文章感兴趣,但苦于缺乏实验思路与选题,那么快来联系馆长吧,把握风口快速发文~
定制生信分析
云服务器租赁
加好友
备注“99”
领取试用

题目:对癌症合成致死率预测的机器学习方法进行基准测试
杂志:Nat Commun
影响因子:IF =14.7
发表时间:2024年8月
后台回复“
666
”获取原文献,编号241030
研究背景
合成致死性(SL)是抗癌药物靶点的重要研究,揭示了细胞存活的癌症特异性依赖性。且最近出现了许多用于SL预测的机器学习方法,然而却缺乏全面的基准测试。因此本研究旨在进行基准测试,评估了机器学习在不同数据拆分场景、负样本比率和负采样技术在分类和排名任务中的表现。
研究思路与数据来源
本研究编制了一份最近发布的用于预测SL交互的传统机器学习和深度学习方法的列表,从中选择3种矩阵分解方法和9种深度学习方法进行基准测试。此外利用三种负采样方法(NSM)研究了负样本质量对模型性能的影响。最后还执行了两项预测任务(即分类和排序)来识别最可能的SL基因对,为不同AI方法的SL预测性能提供了有价值的见解。
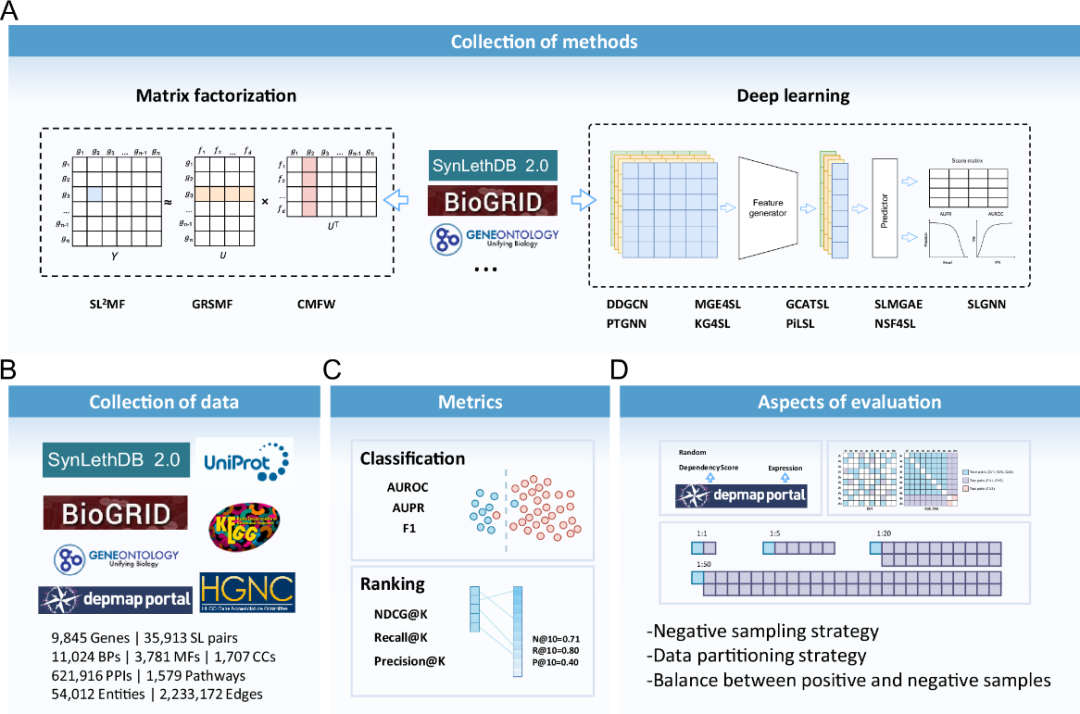
图1. 基准测试研究的工作流程
研究结果
1. 基准测试管道
本研究设计了36个实验场景,考虑了3种不同的数据拆分方法(DSM)、4种正负采样率(PNR)和3种负采样方法(NSM),结果如图2所示。在获得各种实验场景中所有方法的结果后,评估了它们在分类和排序任务中的性能,并设计了一个总分(参见方法)以更好地量化它们在图1中的性能。

图2. 模型的性能
2. 对未看见的基因的泛化性
在本研究中使用了三种不同的数据拆分方法(DSM)进行交叉验证,结果显示CV1是最常用的交叉验证方法。此外,图3A-B分别显示了SLMGAE和GCATSL模型的训练集和测试集中基因对的预测分数分布。值得注意的是,当DSM为CV1时两个模型都可以有效地区分正样本和负样本。
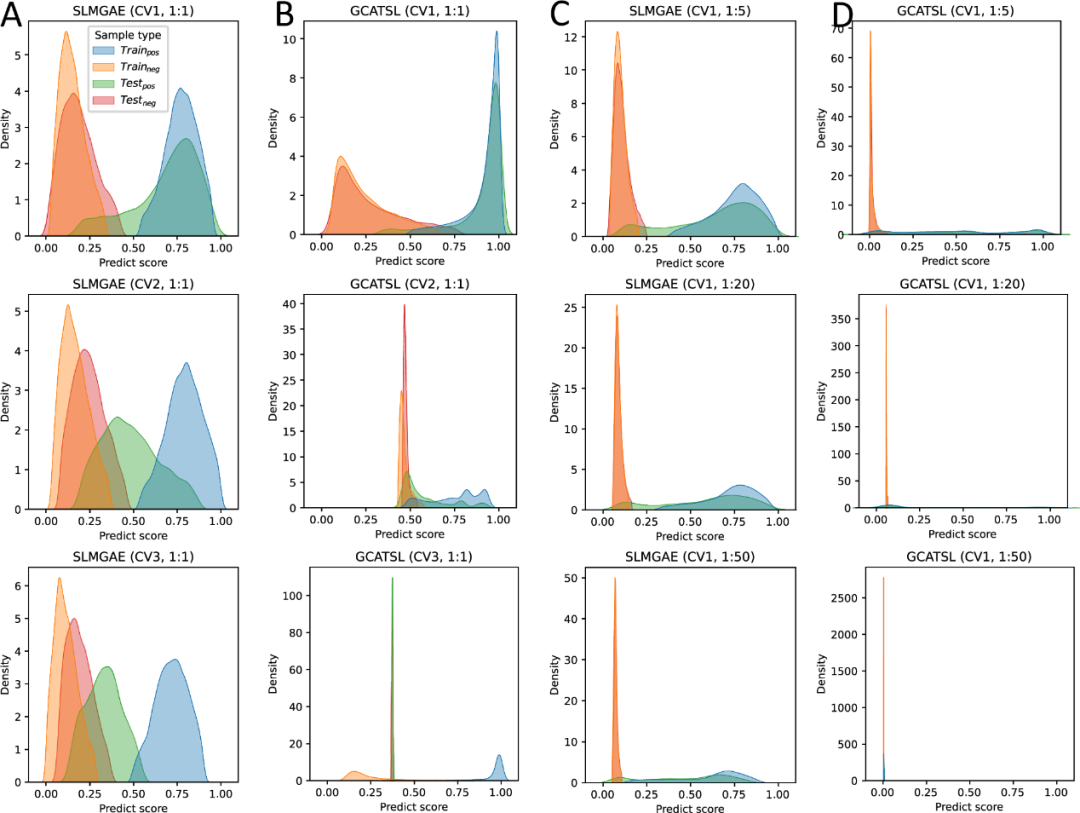
图3. 预测分数的分布
3. 负采样的影响
本研究中评估了三种负采样方法,还评估了负抽样对模型泛化和稳健性的影响,则通过NSM
Exp
对基于矩阵分解的方法的性能影响较小,但CMFW模型除外,与NSM相比,CMFW模型在分类任务中的性能显著降低。相反对于基于深度学习的方法,通过NSM
Exp
提高模型在各种场景下的分类任务性能,尤其是CV1和CV2的场景。
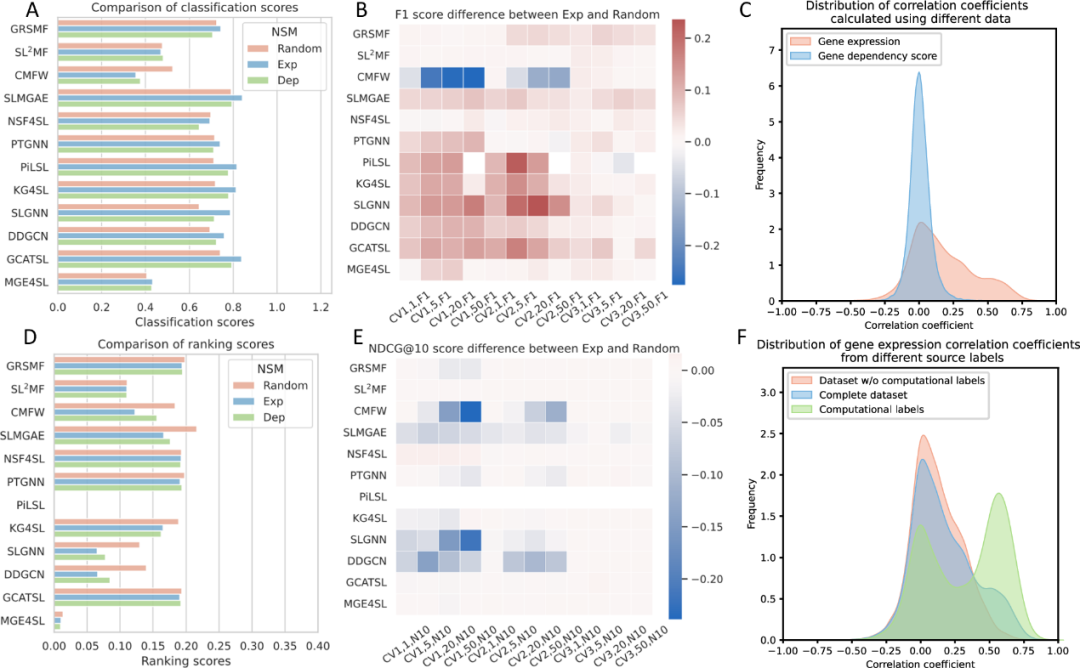
图4. 各种负采样方法下的模型性能和已知样本相关性分析
4. 计算派生的标签对性能的影响
结果显示在从数据集中排除计算方法预测的SL标签后,各种DSM中所有模型的性能通常都得到了显著提高,值得注意的是,NSF4SL在分类任务中被提升到第二好(即亚军),在 CV1和CV2场景中,F1分数分别提高了0.108和0.135。尽管如此,SLMGAE仍然是总体上表现最好的模型。
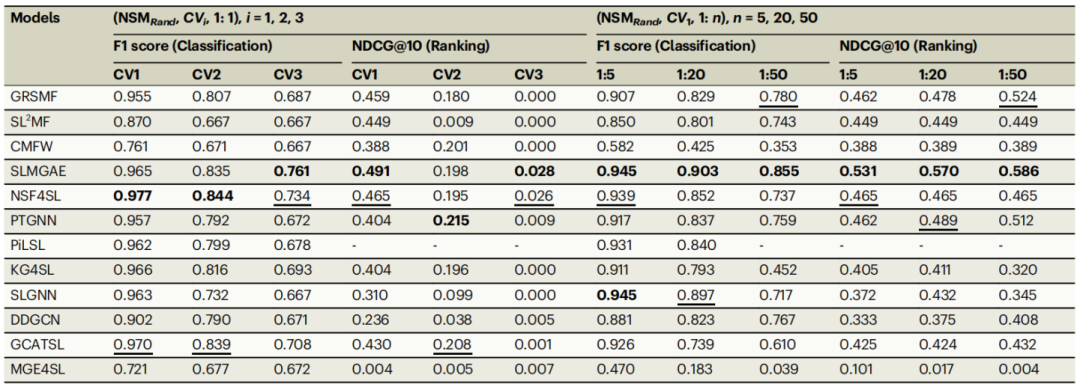
图5. 不同DSM和PNR下模型的性能
文章总结
本研究对SL预测的机器学习方法进行了全面的基准测试,结果证实SLMGAE表现最好,这为生物学家提供了模型利用的指南。该实验选题新颖,代码公开,助力解决临床问题,是篇难得的佳作!
各位宝子可以看出“蹭”热点的魅力所在了吧,所以你也想复现此类思路,可以联系馆长来助力!只要你有想法,我们就定能助您早日圆满SCI,就等你来啦~
馆长会持续为大家带来最新生信思路,也可以提供特色数据库构建、免费思路评估、付费生信分析和方案设计以及实验项目实施等服务,对数据库构建和生信分析感兴趣的朋友可以咨询馆长哦!









