
最近,Google Brain员工,TensorFlow产品经理Zak Stone在硅谷创业者社群South Park Commons上做了个讲座,谈到了TensorFlow、XLA、Cloud TPU、TFX、TensorFlow Lite等各种新工具、新潮流如何塑造着机器学习的未来。同时,他还暗示了一些还未向公众披露的exciting的事儿。
讲座的题目叫“Tensor Flow, Cloud TPUs, and ML progress”,以下是整个讲座的概要,编译整理自South Park Commons官方博客。

作为一个平台来说,TensorFlow算是一场豪赌:它兼顾了快速,灵活,还可用于生产。实验和执行之间的转换要足够快,才能保证工程生产力,静态图像计算通过Python等高级灵活的语言来表示,同时图编译允许对特定目标进行准确度优化。

作为一个开源项目,TensorFlow极为成功,它从2015年11月发布至今在Github上已经获得了超过20,000个commit。Github版的TensorFlow每周与Google内部镜像文件之间至少会进行一次双向同步,同时TensorFlow也收获了来自Intel,Microsoft,IBM,Rstudio,Minds.ai以及其他公司研发团队的大大小小的贡献。

为了更好地触及用户,能够在移动端上提高运行TensorFlow模型效率的TensorFlow Lite将会在今年晚些时候内嵌到设备中,而像XLA这样的项目更具野心:XLA使用深度学习来支持线性代数元的先时和实时编译,从而为任意的目标后端系统生成加速过的代码。XLA的目标是在递阶优化上实现重大突破,不仅是在GPU架构上,更是要在任意能够平行放置线性代数元的架构上实现突破。

谷歌内部,在CEO Sundar Pichai要成为“AI-first”公司的号召下,TensorFlow被应用到非常多的项目当中。
而加速研发基于机器学习软件的趋势不仅在Google身上发生,亚马逊,苹果,百度,Facebook,微软,Salesforce,Uber,Lyft等几乎所有的主流科技企业也都雇佣了专业的研发团队来推动机器学习的工业化。而在这些公司中,深度学习的开发平台也是五花八门,其中包括来自Facebook的PyTorch和Caffe2,来自Microsoft的CNTK,来自Apple的Core ML以及来自Amazon的MXNet等。
未来十年,软件工程会变成什么样?
机器学习的崛起,意味着原来的clean abstraction和模块化设计正在被高维浮点张量和高效矩阵乘法所取代。
按这种趋势发展下去,软件工程行业将被改变。
Google软件工程师D. Sculley曾写过一篇题为“Machine Learning: The High-Interest Credit Card of Technical Debt”的文章,他在其中列举出了机器学习系统诱发低劣软件的设计的种种可能,甚至会使这些低劣的设计成为必须。他提到,“这些系统的基本代码跟正常代码拥有相同的复杂度,但在系统层面上拥有更大的复杂度,从而可能引发潜在的风
险。”
(https://research.google.com/pubs/pub43146.html)
机器学习系统通过将所有系统输入紧密耦合,模糊了模型边界和抽象:理想的行为不变性不是来自软件逻辑,而是来自于驱动它们的特定外部数据。尽管存在通过静态分析和图连接来辨别代码可靠性的工具,但总体上,这些工具并没有办法用来分析数据的相关性。
D Sculley等人在文章中讨论了几种系统设计中的劣势,很能与相关从业者产生共鸣:
1. Glue Code(粘滞的代码)系统设计样式,“在这其中需要写大量的支持代码负责把数据传入、传出各种用途的安装包”;
2. Pipeline jungles(乱七八糟的流水线),它会随时间有机地演变,数据准备系统“可能会变成由scape,join和sampling步骤组成的一团乱麻,通常还伴随着中间文件的输出”;
3. Configuration debt(庞大的编译代价),将会随着系统和生产线的研发而逐渐累积,集合了“各种编译选项,包括使用的特征有哪些,怎样筛选数据,特定学习算法的设置(范围很宽),潜在的预处理或者后处理,验证方法等等。”
即使在更小、更轻量化的项目中,工程师还会被以下这些问题困扰:
1. 在实验中模型架构和权重的版本——尤其是当模型从不同体系借来了部分训练模型,或者从其他模型借来了权重的时候。
2. 数据来源和特征的版本;
3. 在实验环境和实际生产环境之间的迁移(domain shift);
4. 监测生产中推断的质量。
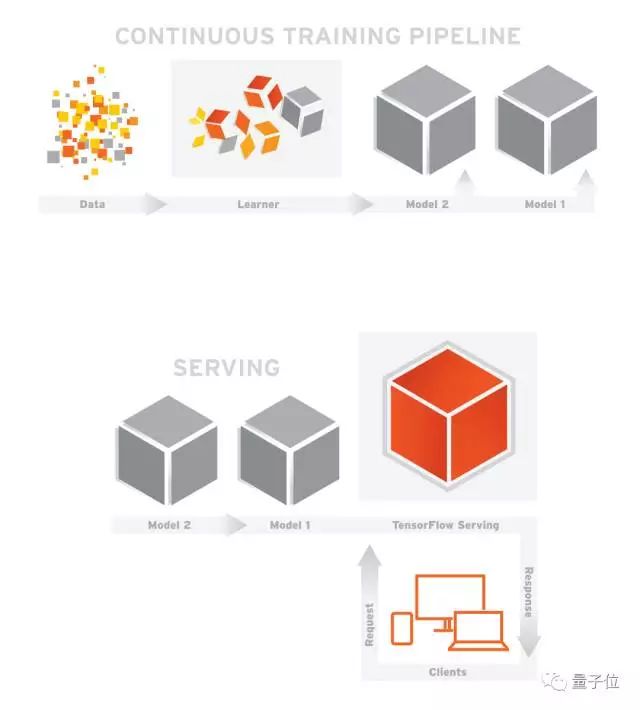
解决这些问题的一个可能方案是TFX,它是一个Google内部研发的平台,用来在生产中分布和供应机器学习模型:
创造和管理一个可用于可靠地生产和部署机器学习模型的平台,需要在很多部件之间进行细致编排——这些部件包括基于训练数据生成模型的学习器、用于分析和验证数据和模型的模块、以及最终在生产工程中用于部署模型的基础架构。当数据随着时间变化且模型在连续更新时,平台的管理就变得非常难。
不幸的是,这些编排通常是通过glue code和特定的脚本文件来有针对性的一一处理,导致了复制成本大、系统脆弱的同时伴随着大量的技术隐患。
TFX标准化了这些过程和部件,并把它们整合到单个平台上,从而简化了平台编译的过程,在确保平台可靠性、减少服务崩溃的基础上,将制作的时间从数月减少到了数周。
未来十年,硬件会变成什么样?
摩尔定律放缓,使得我们得以重新进入“架构的黄金年代”,见证各式各样芯片和指令集的飞速发展。
诸如英特尔旗下的Nervana、英伟达、Cerebras和Google等公司全都开始研发能够加速机器学习中线性代数运算的下一代硬件架构。且在默认情况下,每种架构都需要独特的、像cuDNN那样的底层、手动优化基元库。(cuDNN全称是CUDA Deep Neural Network library,是NVIDIA专门针对深度神经网络设计的一套GPU计算加速库。)










