随着大数据处理技术的逐步成熟和广泛应用,金融机构根据业务发展需要,开始尝试采用大数据和复杂网络技术来建立便捷性、直观性和快速反应的企业关联查询生产系统的研究。

本篇案例为数据猿推出的大型“金融大数据主题策划”活动(查看详情)第一部分的系列案例/征文;感谢 天云大数据 的投递
作为整体活动的第二部分,2017年6月29日,由数据猿主办,上海金融行业信息协会、互联网普惠金融研究院联合主办,中国信息通信研究院、大数据发展促进委员会、上海大数据联盟、首席数据官联盟、中国大数据技术与应用联盟协办的《「数据猿·超声波」之金融科技·商业价值探索高峰论坛》还将在上海隆重举办【论坛详情】【上届回顾(点击阅读原文查看)】
在论坛现场,也将颁发“技术创新奖”、“应用创新奖”、“最佳实践奖”、“优秀案例奖”四大类案例奖

来源:数据猿丨投递:天云大数据
本文长度为5500字,建议阅读11分钟
由于传统的分析技术瓶颈问题凸显,已无法满足当今日益复杂且变化迅速的社会环境,随着大数据处理技术的逐步成熟和广泛应用,金融机构根据业务发展需要,开始尝试采用大数据和复杂网络技术来建立便捷性、直观性和快速反应的企业关联查询生产系统的研究。
系统以机构内部数据为数据源,计算出企业与企业之间、个人与企业之间、个人与个人之间的投资、担保、实际控制人、高管、家族的复杂关联关系,以直观的关系图谱形式展示,并实现关联群的授信机构信息的加工整理以及查询结果下载等服务。
如下是天云大数据使用公司产品BDCN(BeagleData Complex Platform)复杂网络技术为人民银行征信中心提供企业关联关系计算及图谱展示的成功案例。
周期
2015年10月—2016年3月
客户
中国人民银行征信中心
任务/目标
大数据与复杂网络技术应用于关联关系计算的可行性研究
综合考察业务应用的实际需求,模拟关联关系计算情景,通过实验和分析评选出一种最优的大数据处理技术,拟定关联关系计算的过程,实现企业和个人的投资、担保、实际控制人、高管、家族信息的关联关系的计算,从而评价关联关系计算方法的建设性、合理性、可操作性。
网络关系图谱展示技术与方法的可行性研究
采用国内外在网络关系图谱的结构、要素、关系及生成过程等主流的实现方法建立系统原型,通过实验和分析综合比较不同图谱展示方法的效率,评选出一种最优的展示方法,根据业务实际需求,实现在线并发关联关系查询任务和批量关联关系查询。
图谱展示效果的可行性研究
通过先进的展示技术手段,实现全面且有效的展示应用场景,包括展示标出关系方向,能够反映出企业与企业之间、企业与个人之间、个人与个人之间的关系形成路径;灵活设置筛选条件,对图谱进行切割,包括以图谱中任一节点,展示下一层关联企业;以图谱中任一关联企业为发起节点,再生成新的图谱;当鼠标移动到节点上时,可显示出企业或个人的基本信息和信贷信息,并能够以表格形式提供下载。
挑战
1)基础数据处理难点
机构提供的企业和个人基本信息、担保信息、信贷信息,这些源数据量非常庞大,但在做关联关系计算前需要对这些基础信息做有效数据处理,数据处理过程包括清洗、转换以及整理,这些工作必须要在进行关联关系计算前完成,从而为关联关系计算的数据建模做好数据准备。
但该项工作需要在耗费一段时间完成,如果实际给出数据处理的时间窗口较短,又或者处理的数据量大并且处理逻辑复杂,那么就会无法在指定的时间窗口内完成处理任务,则就会对后续的工作产生延迟影响。
因此,如何利用灵活的数据处理技术,并保证在指定的时间窗口内完成数据处理任务是一关联关系计算的一项技术难点。
2)数据建模难点
当对源数据完成处理后,就需要针对适合关联关系计算的应用场景进行数据建模,目前常见的数据模型种类较多,但每种模型都适用于不同的数据应用场景,如果选用恰当的数据模型则会使关联关系的计算的性能效率提高很多,否则会产生不利的负面效果,因此,在数据模型选用上也是关联关系计算的一项技术难点。
3)关系计算难点
如果把企业和个人描绘成节点,而企业与企业、个人与企业、个人与个人之间的关系描绘成节点之间连成的边,按全连通关系网的方式进行计算,两个节点之间可以构成1个1层关系,三个节点之间可以构成3个1层关系,四个节点可以构成6个1层关系,五个节点可以构成10个1层关系,1000个节点最多可以构成(1000(10001))/2共计499500个1层关系,依次类推随着节点数的增加,其关系产生的数量会随节点数量呈指数级增长。
即使不按全量通的关系网络方式来计算,节点与节点之间的关系数也会随节点数的增多呈更大规模的增长,如果对于大规模节点所组成的关系网络来说,其关系的规模可想而知,那么采用什么样的技术和什么样的计算能够快速的计算出节点与节点之间的1层或多层级关系是一个项主要的技术难点。
解决方案
1)分布式存储技术
庞大的关系网络数据存储可以采用分布式存储技术,根据关系网络数据的分布式特点,将网络数据进行切分,不但可以满足当前大体量数据的存放以及支撑未来数据快速膨胀,还可以支撑大批量离线数据处理的需求,以下是对关系网络进行切分方法及特点的阐述。
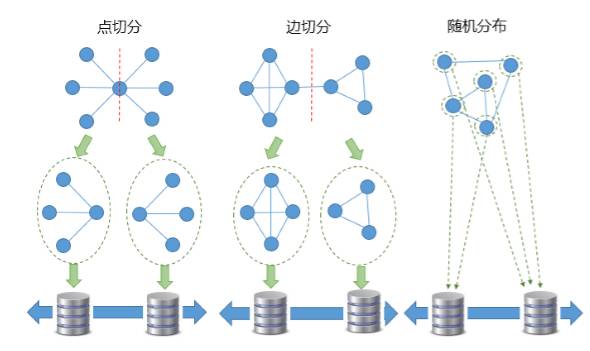
为了提升数据访问的性能,网络数据会被按策略切分并分布存储在集群中不同的存储实例上,提供分布策略包括“随机分布“、”边切分分布“、”节点切分分布“,可根据不同场景的数据特征,采用不同的分布方式,在具体使用上用户可以通过配置参数加以实现。
随机分布,是将网络数据中的节点随机存放在集群的不同服务器节点上,主要适用于数据规模不大或数据分布特征不明显的复杂网络场景。
边切分,是将网络结构数据的部分边进行切分,从而将一个大网络转变成多个关系稠密的聚集子网络,分别存储在不同服务器节点上,主要适用于称社区化分布的复杂网络场景。
点切分,是将网络结构数据的一些特定的点进行切分,并分布存储在不同的服务器节点上,主要适用于存在一定数量边数较高节点的网络中,避免在数据访问中产生热点。
2)分布式处理技术
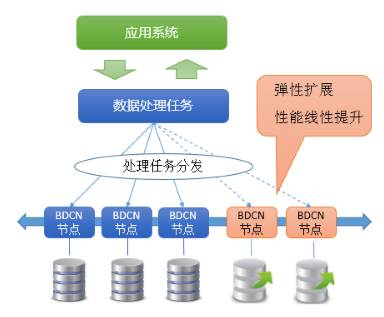
该部分主要是对源数据的处理,包括数据的清洗、转换以及整理任务,由于源数据的数据格式可能会是多样且规模比较庞大,采用一台主机可能无法在指定的时间窗口内完成数据处理任务的要求,而采用分布式批量处理技术则会满足要求,因为分布式批处理技术可以将处理任务分成多个子批处理任务并分配到多台主机上并行进行处理,从而充分利用多台主机的资源。
同时,分布式批处理技术具备伸缩性,因此可以保证根据不同的处理规模以及不同的时间窗口要求来灵活调整并行处理线程以保证按时完成大规模数据处理任务,目前国内外主流、技术成熟且使用非常广泛的分布式批处理计算框架则是Hadoop的MapReduce,其与HDFS分布式文件系统结合使用完全可以满足任意大规模的数据批处理的处理需求。
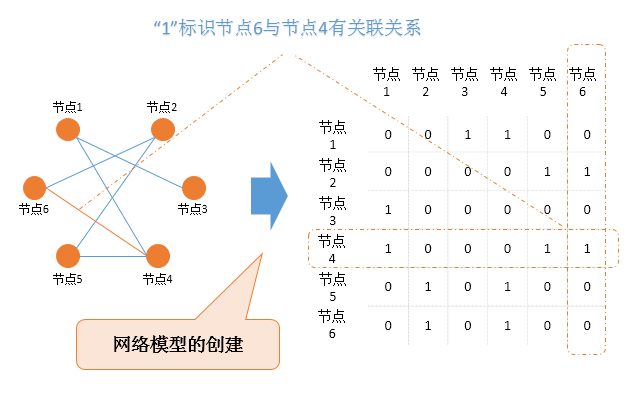
3)关系建模技术
将关系网络中所有的节点设计成矩阵的行和列,从而形成一张方形矩阵,方形矩阵中的“0”和“1”分别标识对应的节点之间是否存在关系,通过矩阵可以迅速检索到某节点与网络中的其它节点有无关系。
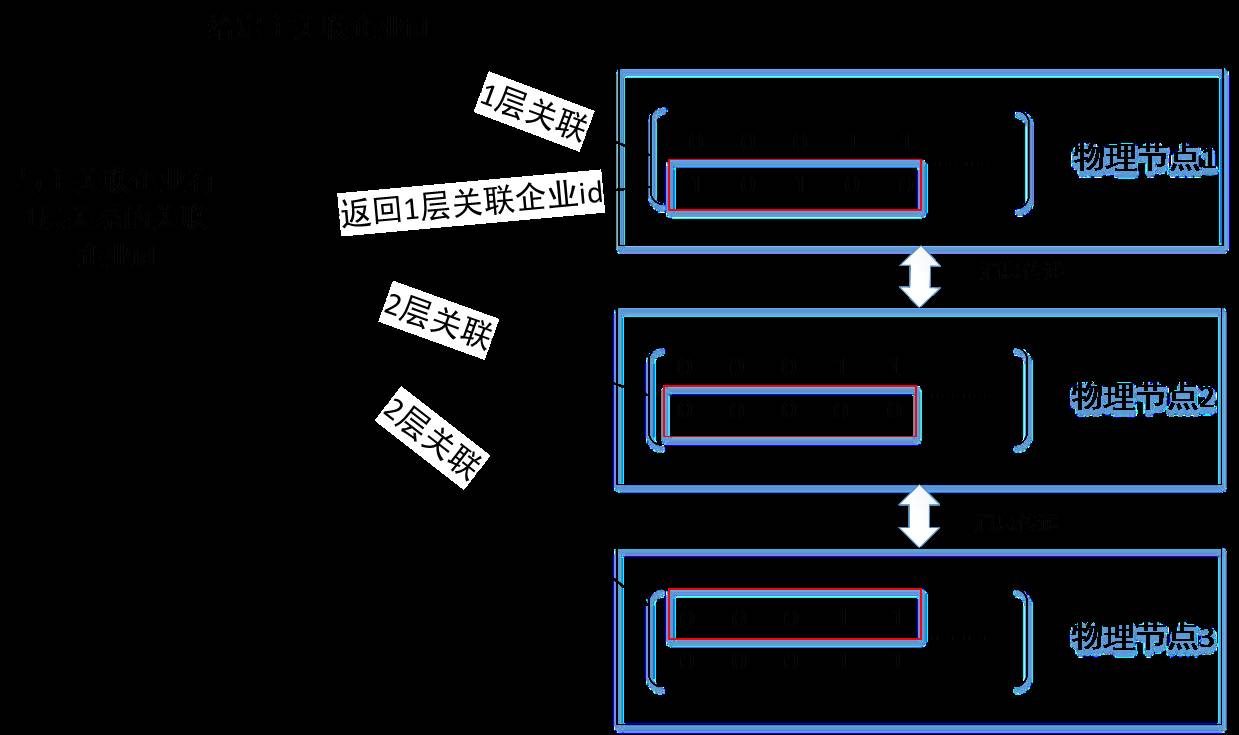
4)关系网络计算技术
基于创建好的关联关系复杂网络拓扑模型已经完全能够表达出节点之间的一层关系,因此不需要计算。第二层关联关系计算就要基于已知的关联个体第一层的关系数据,从存储中读取一层的关系数据,然后按照计算算法去计算第二层关联关系数据,完成后再写入存储。
在对第三层关系进行计算时就需要基于第二层算好的数据,所以再每次往上层级进行关系计算时都得需要之前层级的关系的结果数据,然后依次类推。
5)关联关系图谱展示
和弦图展示方法

和弦图(又称Chord Diagram)是国内外常用的研究展示元素之间关联关系的主流展示方法,它的结构为一个环状图形,所有的展示元素均为环形图的不同部分的弧状边,边与边之间采用空白或者间隔类图形来加以区分元素。
弧状边上或以外有对应文字标题表示该展现元素的名称、代码等简要信息,详细信息可通过查看弧状边的注释信息获取,通过使用不同的颜色以及颜色的深浅等方式绘制弧状边来表达元素的不同类别。
通过弧状边之间的带状连线表达元素与元素之间的1层关系,带状线的宽度大小可以表达出关系的权重值,不同的连线颜色或颜色的深浅表示关系的不同类别,通过查看带状连线的注释信息可以查看元素与元素之间的详细关系信息。使用者可以任意选中其中一个展示元素查看到该元素与其它展示元素之间的关联关系。
网络图谱展示方法
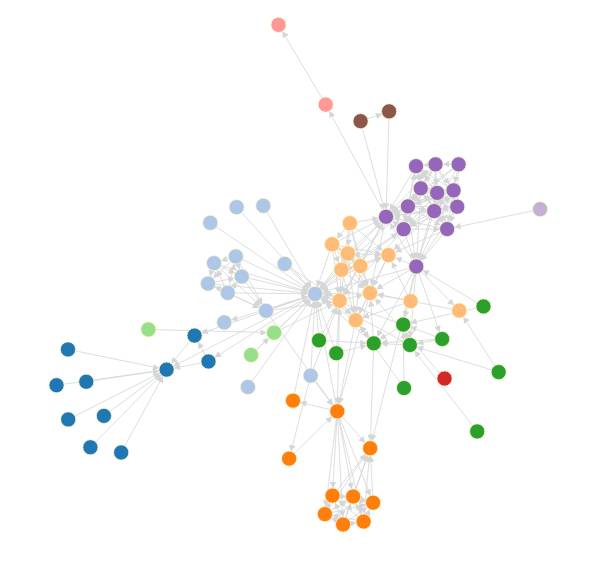
复杂网络图(又称Force Directed Graph)是国内外常用的主流的研究展示元素之间关联关系的网络展示方法,它的结构为一个网络图形。
所有的展示元素均为网络中不同的圆点,所有的圆点在展示空间的位置上独立,不会出现圆点重叠的情况,每个展现元素的标题或简要信息可以在圆点旁点或再圆点之上显示,详细信息可通过查看圆点的注释信息获取,通过使用不同的颜色以及颜色的深浅等方式绘制圆点来表达元素的不同类别。
通过圆点之间的直线或弧线表达元素与元素之间的1层或多层关系。可以通过增加连线的宽度表达出元素之间关系的权重值,不同的连线颜色或颜色的深浅表示关系的不同类别或不同的权重值,通过查看圆点之间连线的注释信息可以查看元素与元素之间的详细关系信息,圆点与圆点之间的连线可以是一条连线也可以是多条联系,连线可以有箭头表示关系的方向,也可以没有箭头表示无向关系。
树状关系网络图展示方法
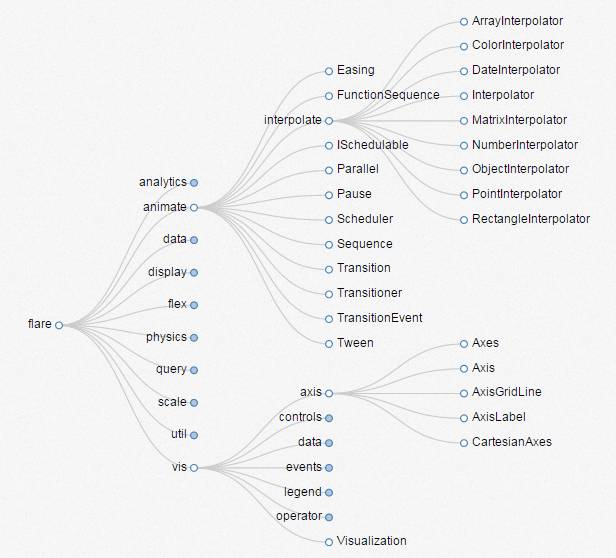
树状关系网络图(又称Tree Layout Graph)是国内外主流的研究展示元素之间关联关系的网络展示方法,它的结构为一个树形目录图形。
所有的展示元素均为图中不同的节点,所有的节点在展示空间的呈现一种层次结构,不会出现节点重叠的情况,每个展现元素的标题或简要信息可以在节点的旁点或直接作为节点,详细信息可通过查看节点的注释信息获取也可直接显示在节点上,通过使用不同的颜色以及颜色的深浅等方式绘制节点来表达元素的不同类别。
通过节点之间的直线或弧线表达元素与元素之间上下级一层或多层关系。可以通过增加连线的宽度表达出元素之间关系的权重值,不同的连线颜色或颜色的深浅表示关系的不同类别或不同的权重值,通过查看节点之间连线的注释信息可以查看元素与元素之间的详细关系信息也可直接显示在节点上,节点与节点之间的连线可以是一条连线也可以是多条连线,连线可以有箭头表示关系的方向,通常都是从上一层级指向下一层级,不然展示的图谱将会很难用于分析。
结果/效果总结
1)实现的成果
利用Hadoop大数据技术,能够将多台服务器组成一个大的数据处理集群来共同支撑大规模的数据处理任务和服务,从而可以有效的满足项目的庞大的数据处理量和服务需求。
企业关联关系数据组合在一起会构成一张复杂的网络结构数据,对于该场景的分析与处理应用,在科学研究领域采用的是图计算理论,而表达图的最佳计算模型为矩阵,因此,只有采用图处理技术才可以有效的处理和解决企业关联关系的查询和计算问题。
企业关联关系查询是查询企业之间一层或多层的关联关系,而每多加一层的关联关系的查询就会增加一次的迭代计算,会涉及到对数据的频繁读写,使用磁盘作为数据性能会非常低下,因此需采用内存处理技术可以有效的满足计算的性能要求。
如果要对企业历史关联关系查询,就得将历史的关系数据进行归档保存,然后根据归档数据对企业关系的历史有效性进行判断,会涉及到大量的归档数据遍历检索,因此这部分会成为性能关键点,Hadoop技术能够提供具备分布式集群处理能力HBase,数据遍历查询可达毫秒级响应,完全满足性能要求。
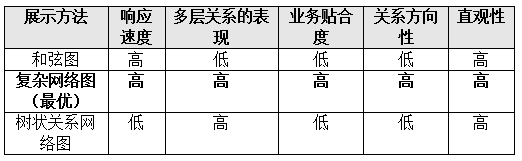
综合的分析了表达关联关系图谱的主流展示技术,分别为和弦图谱、树形图谱以及复杂网络图谱,然后从直观性、响应速度、多层关系表达、业务贴合度、关系的方向性五个方面进行的评估和展示实验,最后得出复杂网络图谱在五个评估角度表现最优。
2)所解决的问题
解决了传统技术查询响应时间长以及无法响应的问题,通过Hadoop的技术实现方案可以将查询性能提升到秒级甚至毫秒级的响应级别,更好满足了用户对响应等待时间的要求。

解决了传统技术关联查询系统展现不友好的问题,通过复杂网络图谱技术能够方便用户直观的查看企业与企业、企业与自然人之间的各种关联关系并更好的进行分析。
解决了传统技术未能实现的历史关联关系查询以及担保圈闭环的计算和查询的功能需求。

3)技术提升
传统技术采用的是关系表模型,在关联关系查询方面会产生大量的计算负荷,严重影响性能,而Hadoop大数据技术可支撑网络结构模型,大幅降低了计算量,从而高效的提升了处理性能。
传统技术采用的是单台服务器的计算方案,由于无法进行扩展,导致计算能力不足,无法支撑大规模数据处理和大规模的计算任务,而Hadoop大数据技术采用分布式处理技术,一台服务器无法满足的工作,可并行使用多台服务器,扩展能力强,完全能够支撑大规模数据处理和大规模的计算任务。
传统技术采用的数据处理技术单一,无法有效满足应用场景的各个环节的对处理技术的要求,因此,在整体处理性能表现并不理想,而Hadoop富含有多样的处理技术,因此,针对应用场景,采用多种处理技术的组合,从而发挥每种技术的优势,达到最佳的效果体验。
企业简介:
天云大数据早期由国际一线科技教父杨致远田溯宁孵化,国内唯一能够同时提供分布式计算平台产品和AI平台基础设施的科技厂商,拥有博士后工作站和国家级高新企业称号,并于2016首批进入中关村前沿科技企业重点计划。
公司在分布式计算领域有自主产品,填补了联机事务等领域空白,并在多个大型银行核心交易系统部署验证同时获得千万级以上软件收入。在人工智能方向领先于BAT发布了分布式AI平台,于2016年在大型股份制银行落地,并获得过百万美金的AI平台收入。该平台与科大讯飞一起获得了北美ZDnet评选的十大AI赋能平台奖项。
凭借分布式AI能力,天云自2016开始为金融机构提供数据模型深入信用风险欺诈等金融业务领域,为人行光大兴业银联等提供信用业务相关计算与数据科学模型,由此获得国际一线机构KPMG评定的中国Fintech50强,亚太Asset财经评选的TrippleA金融科技领先奖,财视的Fintech30强金融科技介莆奖,与蚂蚁金服京东金融等同列的先进金融科技企业。

数据猿超声波
「2017金融科技商业价值探索高峰论坛」
(点击图片,了解详情)













