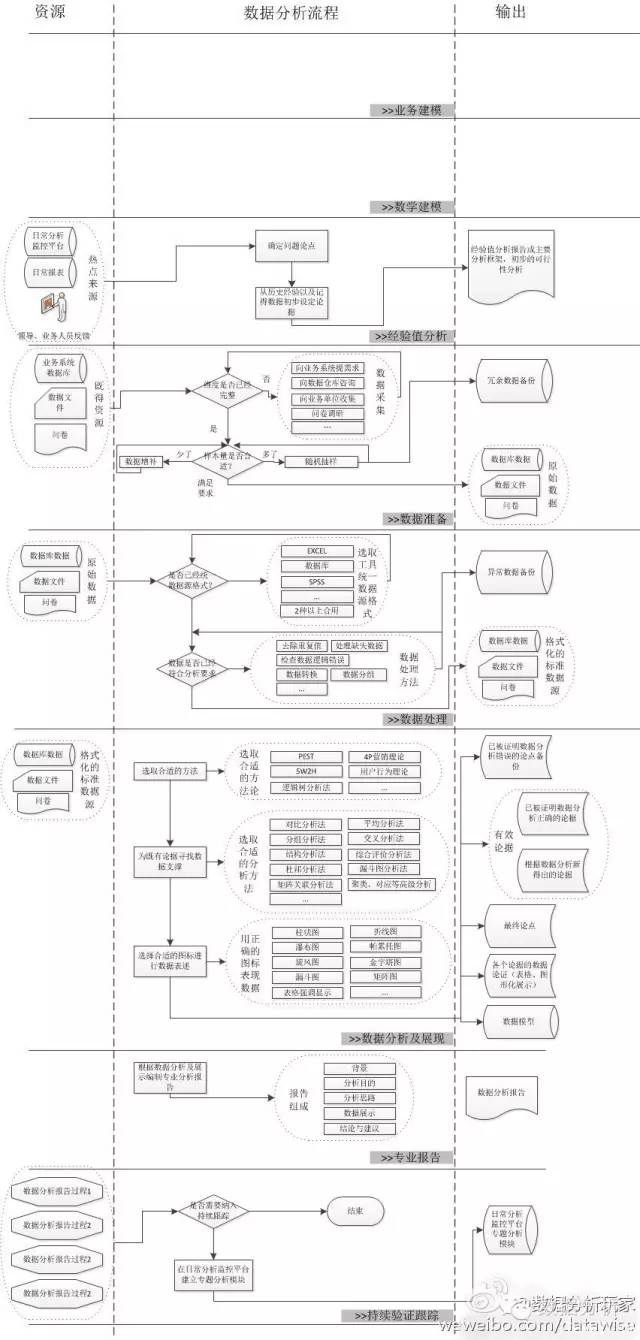
【编者注】此图整理自微博分享,作者不详。一个完整的数据分析流程,应该包括以下几个方面,建议收藏此图仔细阅读。
完整的数据分析流程:1、业务建模。2、经验分析。3、数据准备。4、数据处理。5、数据分析与展现。6、专业报告。7、持续验证与跟踪。
(注:图保存下来,查看更清晰)
作为数据分析师,无论最初的职业定位方向是技术还是业务,最终发到一定阶段后都会承担数据管理的角色。因此,一个具有较高层次的数据分析师需要具备完整的知识结构。
1. 数据采集
了解数据采集的意义在于真正了解数据的原始面貌,包括数据产生的时间、条件、格式、内容、长度、限制条件等。这会帮助数据分析师更有针对性的控制数据生产和采集过程,避免由于违反数据采集规则导致的数据问题;同时,对数据采集逻辑的认识增加了数据分析师对数据的理解程度,尤其是数据中的异常变化。
比如:
Omniture中的Prop变量长度只有100个字符,在数据采集部署过程中就不能把含有大量中文描述的文字赋值给Prop变量(超过的字符会被截断)。
在Webtrekk323之前的Pixel版本,单条信息默认最多只能发送不超过2K的数据。当页面含有过多变量或变量长度有超出限定的情况下,在保持数据收集的需求下,通常的解决方案是采用多个sendinfo方法分条发送;而在325之后的Pixel版本,单条信息默认最多可以发送7K数据量,非常方便的解决了代码部署中单条信息过载的问题。(Webtrekk基于请求量付费,请求量越少,费用越低)。
当用户在离线状态下使用APP时,数据由于无法联网而发出,导致正常时间内的数据统计分析延迟。直到该设备下次联网时,数据才能被发出并归入当时的时间。这就产生了不同时间看相同历史时间的数据时会发生数据有出入。
在数据采集阶段,数据分析师需要更多的了解数据生产和采集过程中的异常情况,如此才能更好的追本溯源。另外,这也能很大程度上避免“垃圾数据进导致垃圾数据出”的问题。
2.数据存储
无论数据存储于云端还是本地,数据的存储不只是我们看到的数据库那么简单。
比如:
数据存储系统是MySql、Oracle、SQL Server还是其他系统。
数据仓库结构及各库表如何关联,星型、雪花型还是其他。
生产数据库接收数据时是否有一定规则,比如只接收特定类型字段。
生产数据库面对异常值如何处理,强制转换、留空还是返回错误。
生产数据库及数据仓库系统如何存储数据,名称、含义、类型、长度、精度、是否可为空、是否唯一、字符编码、约束条件规则是什么。
接触到的数据是原始数据还是ETL后的数据,ETL规则是什么。
数据仓库数据的更新更新机制是什么,全量更新还是增量更新。
不同数据库和库表之间的同步规则是什么,哪些因素会造成数据差异,如何处理差异的。
在数据存储阶段,数据分析师需要了解数据存储内部的工作机制和流程,最核心的因素是在原始数据基础上经过哪些加工处理,最后得到了怎样的数据。由于数据在存储阶段是不断动态变化和迭代更新的,其及时性、完整性、有效性、一致性、准确性很多时候由于软硬件、内外部环境问题无法保证,这些都会导致后期数据应用问题。
3.数据提取
数据提取是将数据取出的过程,数据提取的核心环节是从哪取、何时取、如何取。
从哪取,数据来源——不同的数据源得到的数据结果未必一致。
何时取,提取时间——不同时间取出来的数据结果未必一致。
如何取,提取规则——不同提取规则下的数据结果很难一致。
在数据提取阶段,数据分析师首先需要具备数据提取能力。常用的Select From语句是SQL查询和提取的必备技能,但即使是简单的取数工作也有不同层次。第一层是从单张数据库中按条件提取数据的能力,where是基本的条件语句;第二层是掌握跨库表提取数据的能力,不同的join有不同的用法;第三层是优化SQL语句,通过优化嵌套、筛选的逻辑层次和遍历次数等,减少个人时间浪费和系统资源消耗。





