导读:管理一个复杂的微服务系统离不开分布式跟踪技术,它对于了解系统运行状况及发现系统瓶颈非常有帮助,正如下图所说,分布式跟踪体系是微服务中最被忽视的一个组件,通过本文我们可以进一步了解其架构,本文由高可用架构翻译。文章最后还有若干精选岗位推荐。

Pinterest,是一个网络与手机的应用程序,可以让用户利用其平台作为个人创意及项目工作所需的视觉探索工具,同时也有人把它视为一个图片分享类的社交网站,用户可以按主题分类添加和管理自己的图片收藏,并与好友分享。其使用的网站布局为瀑布流布局(Pinterest-style layout)。(高可用架构小编:以上是根据维基百科的定义)
Pinterest 后端包括部署在数万台机器上的数百个微服务。一个普通的首页 feed请求,就需要执行数百个网络调用及访问数十个后端服务。虽然我们知道每个请求需要执行多长时间,但在以前,
我们不知道一些请求为什么缓慢
。为了收集这些数据,我们构建了 Pintrace(一个分布式跟踪服务)来跟踪请求,它支持我们所有的 Python 和 Java 后端服务。
我们还构建了 Pintrace Collector 来帮助我们分析性能问题。Pintrace Collector 是一个 Spark 任务,它从 Kafka 收集数据,将它们聚合成 Trace 信息并将它们存储在 Elasticsearch 后端。
今天,我们在 Github 上开源 Pintrace Collector [1],并将代码贡献给 OpenZipkin 社区。通过将其发布到社区,我们希望其他人能够像我们一样受益于项目。
背景
跟踪一个响应延迟的来源可能非常具有挑战性,因为缓慢可能是由我们的任何一个后端服务引起的。 我们的监控( OpenTSDB )和日志记录( ELK )等基础组件提供了后端处理请求的粗粒度视图,但在 Pintrace 使用之前,我们很难确定某个请求为什么缓慢。
为了解决这个挑战,我们转向分布式跟踪系统来分析延迟问题,它可以显示请求花费时间的地方。除了请求延迟信息之外,还通过捕获请求因果关系信息(即哪些下游请求作为请求的一部分执行)来提供对请求执行的细粒度可见性。 Pintrace 是我们内部的分布式跟踪管道服务,可以跟踪请求,包括请求如何在 Python 和 Java 后端服务中进行处理。
在我们研究细节之前,让我们定义一些术语。(高可用架构小编:由于这些术语的中文在国内并没有广泛使用,本文翻译将大部分直接使用术语的英文)
-
Annotation
:一个请求中发生的事件。 例如,向服务器发送请求是Annotation。
-
Span
:表示一个逻辑操作,并包含属于该操作的一组 Annotation。 例如,“客户端发送”和“客户端接收”这两个 annotation 一起组成的 RPC 调用就是一个 span。(高可用架构小编:在 ZipKin 中,Span 定义是一个请求的 trace 数据)
-
Trace
: Span 的图表。 一个请求的执行通常作为 trace 捕获。 一个 Trace中的所有 span 都具有相同的 trace ID。 有关 trace 结构的更多详细信息,请查看 OpenTracing [2] 的简介 。

Pintrace:分布式跟踪管道服务
(a tracing pipeline)
构建分布式跟踪基础架构涉及设置跟踪管道。 跟踪管道包括两个主要组件 -
源代码插桩和跟踪处理后端。
源代码插桩负责跟踪跨服务的请求,并在请求沿着各种服务处理时生成事件(span)。 跟踪处理后端负责聚合生成的 span,将它们处理为 trace 并进行存储,最后通过 UI 可视化和检索。
Pintrace 跟踪管道由下图所示的几个组件组成。 蓝色的组件是内部开发的。
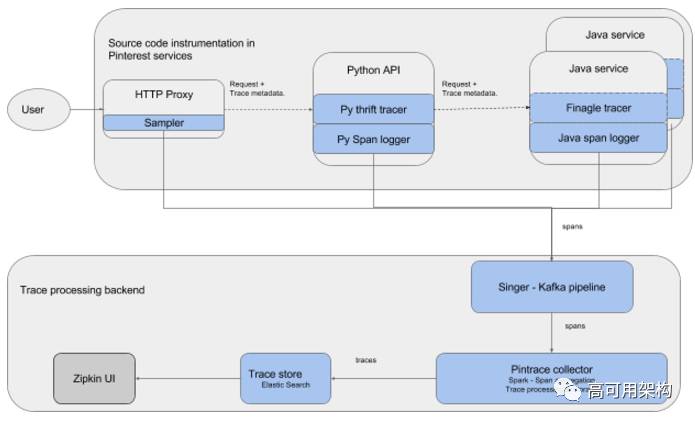
源代码插桩
源代码插桩是设置跟踪管道时的主要工作。 插桩负责向属于同一请求生成具有相同 trace ID 的 span。 为了实现这一点,插桩执行三个任务:
-
在每个请求传递 trace ID
-
为该组件执行的每个逻辑操作生成 一个 span,以及
-
将生成的 span 发送到后端。
前两个功能由跟踪器实现。 日志记录器负责第三个功能,在 Pinterest,我们使用一个名为 Singer 的分析工具将 span 记录到 Kafka。
Pintrace 后端有 Python,Java,Go,Node 和 C++ 编写的 Thrift 服务,每种语言都使用不同的框架。 要跨这些服务来跟踪请求,就需要给每个语言框架实现一个跟踪器。 在 Pinterest,每种语言都有一个公共的框架,由于我们大多数服务都是用 Python 和 Java 编写的,所以我们只需要支持 Python 和 Java 框架。当我们开始构建 Pintrace 时,最初的目标是跟踪网络请求的延迟,所以我们只专注于捕获请求的网络活动来作为 Python 和 Java 应用程序的 span。
Python 插桩
我们 Java 服务之上有一个叫做 ngapi 的单一 Python 服务作为前端,它是一个 HTTP 服务,用于处理到后端的所有传入请求。 为了提供请求,ngapi 通过 Thrift 与 Java 服务进行通信,并基于 Python gevent 库自行开发了 Web 框架。 由于它是一个自己开发的框架,我们在它之上增加了 tracer 来跟踪通过它的请求。
我们使用 open tracing API [3] 为我们的 Web 框架实现了一个跟踪器。跟踪器使用 Finagle 提供的自定义 Thrift 包装器,将 trace ID 从 HTTP 接口传播到 Java Thrift 服务。此外跟踪器会给所有 Thrift,Memcache 和 HTTP 请求生成 span。 为了记录这些 span,我们的 Logger 将生成的 span 转换为 Zipkin 格式 ,并使用 Singer 将它们记录到 Kafka。
由于 ngapi 是一个单服务应用,因此只需要一次修改就可以在所有的前端服务启用跟踪。
Java 跟踪器和 Logger
我们的 Java 服务使用一个称为“service framework”的内部框架,是 Twitter 的 Finagle 库的封装。 由于 Finagle 带有 Zipkin 跟踪器,因此就不需要给 Java 服务开发一个新的跟踪器。 默认情况下,Finagle 跟踪器将收集的 span 写入 scribe 或日志文件,但是由于我们想使用 Singer 将我们的 span 写入 Kafka,所以我们写了一个 span logger,将 span 记录到 Singer。
一旦跟踪器和 Logger 就位,我们在我们的 service framework 中启用它们。 但是,我们的 service framework 缺少一种方法来同时启用所有服务。 为了避免在超过 100 个应用程序中复制此逻辑,我们修改了 service framework 让它支持通过全局配置服务来启用跟踪。
采样器 Sampler
即使我们的客户端插桩只有非常小的延迟开销,但是捕获 span 并通过日志记录将会增加两位数的计算开销。 为了减少这种开销以及存储全量 trace 的成本,我们只跟踪一小组整体请求。
采样器组件决定应跟踪哪些请求,并在所有后端请求的0%到1%(通常为0.3%)之间随机选择。 这个速率可以使用决策者框架动态调整。 我们还对开发机器上的所有请求进行抽样,以便开发人员可以使用跟踪作为日常活动的一部分。
Trace 处理后端
如上图所示,跟踪处理后端负责聚合来自集群中数千台机器的 span,将它们处理为 trace 信息并存储和可视化它们。
Singer-Kafka 流水线
Singer-Kafka 流水线负责聚合由数千台机器产生的 span,并将它们写入 Kafka 主题。 我们使用 Singer 作为我们的 span 聚合管道。 Python 和 Java 日志记录器将 span 记录到本地文件。 每个主机上安装的 Singer 守护程序会监测这些文件的变化,并将新的 span 写入 Kafka 主题。
Pintrace Collector
我们后端使用 OpenZipkin 来接收 span,但是捕获的 trace 显示了一些问题。 例如一些插桩可能有错误,因此我们想修复故障的 span 或去掉这些span,直到插桩的问题恢复。 即使仔细抽样,在我们的规模,还会存在很多类似的问题。因此与其保存所有的 trace 信息,不如只存储有价值的信息,这样将更具成本效益。
这些功能对我们的后端增加了挑战,所以我们开发了 Pintrace collector,它通过一个 Spark 任务从 Kafka 读取 span,将它们聚合成 trace 并将它们存储在 Elasticsearch 中。 我们选择 Spark 来实现流水线,因为它具有足够的灵活性和可扩展性,足以实现所需的过滤,通过 trace ID 分组 span,并通过时间窗口聚合 span 用于分析目的。 作为一个额外的好处,Spark 任务允许我们实时分析 span,而不必存储它们。
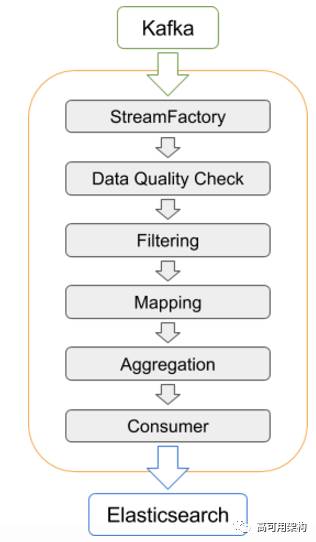
下图显示了 Pintrace collector 的内部架构。
-
StreamFactory 从 Kafka 或任何其他传输接口读取数据。
-
然后处理读取的 span 以确保它们能通过 data quality check 的检查。
-
可选地,过滤步骤 Filtering 可以对 span 作 name 或 annotation 的过滤。
-
聚合阶段可以按时间或 trace ID 对 span 进行分组。
-
最终消费者阶段将数据保存到存储系统,如 ElasticSearch 服务。
Zipkin UI
如架构图所示,我们使用 Zipkin UI 搜索和查看存储在 ElasticSearch 集群中的 trace 信息。 我们还为 Zipkin UI 贡献了几个 bug fix。
Pintrace collector 的开源
在过去一年中,我们注意到 OpenZipkin 社区中的其他人正在寻找我们在 Pintrace 中实施的相同解决方案,例如更高级的采样和流处理以支持 Vizceral 可视化。 我们希望与社区分享我们的工作,同时利用其集体专长。
为了尽可能开放,我们直接在 zipkin-sparkstreaming 代码库下将我们的代码贡献给 OpenZipkin。 我们鼓励您关注或与我们合作建设 Zipkin-spark。 我们希望你能和我们一样利用到 Pintrace collector。 我们非常渴望看到社区的新想法。
致谢:此项目的贡献者是 Naoman Abbas , Phoebe Tse , Ashley Huynh , Alejandro Garcia Salas , Emmanuel Udotong , Brian Overstreet , Xiaoqiao Meng和Suman Karumuri 。 我们还要感谢 Adrian Cole在项目期间的反馈和建议。
高端研发
岗位
推荐
新年开始,很多高可用架构读者也在关注求职信息,因此高可用架构近期会精选一些岗位推荐给大家,这些岗位及团队负责人都经过高可用架构验证,
年薪50万以上
。
小米 通用架构与工具团队 高级研发工程师/架构师 北京
负责微服务相关工作。作为小米的基础架构团队,我们支撑了小米30多条业务线的400多个核心服务。高薪诚聘:
1.服务端架构师:
研发支撑千亿级调用的服务化中间件,比如RPC框架、分布式安全系统、分布式追踪系统等。要求:掌握Java或C++;有分布式系统设计开发经验。
2.容器云专家:
研发容器云平台,支撑Deep Learning与生态云等核心业务。要求:掌握Docker和Kubernetes 简历联系:[email protected]
OPPO手机 OS产品中心 资深架构师 深圳
亿级活跃用户平台、业务规模飞速发展,急需资深架构师加入OPPO共创新篇章。以下三个Java技术栈核心岗位高薪诚聘中:一、丰富的中间件或通用技术组件的规划及设计经验,带头搞
缓存、消息队列等中间件的技术架构
工作;二、5年以上高并发、分布式通信领域经验,一起搭建
大用户量高吞吐的Push平台
;三、精通高可用大流量API系统架构设计工作,负责
应用商店及游戏中心业务&技术架构
工作。以上均Base深圳后海CBD,简历请发:[email protected]。
阿里云 表格存储 研发 杭州、上海、北京
随着业务深度和广度的快速发展,阿里云自研PB级NOSQL数据库诚招
SQL计算/KV存储引擎研发
,级别不限。要求熟悉C/C++,Linux开发平台,2年以上数据库研发经验,阅读过开源代码(关系数据库|KV数据库|SparkSQL等计算引擎均可)更好。Base杭州、上海、北京。简历:[email protected],微信 teaworldvc20。https://www.aliyun.com/ 产品->数据库->表格存储
(高端招聘岗位发布欢迎与小编联系,仅供高可用架构后花园会员)
参考资源
-
https://github.com/openzipkin/zipkin-sparkstreaming
-
http://opentracing.io/documentation/
-
http://opentracing.io/
-
本文英文原文:https://engineering.pinterest.com/blog/distributed-tracing-pinterest-new-open-source-tools








