在电商公司待过的技术同学都知道,在大促来临时,整个集群的最高峰压力将是正常时间的几十倍,最高峰持续的时间会特别短,然后回落到正常水平的几倍。所以,我们可能会自然而然地想到,把整个集群扩容几十倍的机器,在双十一当天应对几十倍的流量,然后第二天减至正常量,就可以完成大促的考验。事实情况是否真的这么简单?有赞在双十一之前完成了全链路压测方案,并把它用于大促的扩容和容量验证,取得了不错的成果。
用户购买商品的链路是一条很长很复杂的系统集群,中间会涉及到店铺、商品、会员、营销、交易、支付等 6 大核心模块,每个模块又会涉及到多个不同的服务化系统单元,我们把这一条骨干的链路就叫做核心链路。
大家都知道,双十一当天,真正爆增的其实是买家的购买量,像开店 / 商品上架等功能,其实并发量没什么变化。也就是说,真正的压力其实是在核心链路上面,如果把所有的系统都扩容几十倍,本身就是一个很大的浪费。正常来说,一个稍有规模的电商公司,日常有几千台机器维持正常的运转,本身就是一个较大的开销,如果突增几十倍的系统开销,对于公司的财务也是很大的压力。所以,一个较理想的方法,是只把核心链路的系统扩大几十倍的系统吞吐量,就可以达到目标。
大型的分布式系统其实错综复杂,公司需要维持成百上千的服务化系统。理论上来说, 只有少部分系统是核心链路的系统。但是在实际情况下,因为公司人员的关系,可能会把某些非核心系统,不知不觉加入到了核心链路中。所以,第一件要做的事情,就是把非核心系统从核心链路上剔除。
一般公司都会在线下搭建性能测试环境,在该环境下,我们的测试同学可 以借助一些测试工具,去压单机单接口的性能。假如,店铺的首页面,我们在性能测试环境下,得出单机单接口的 QPS 峰值是 500,这是否意味着, 要达到 10w 的 QPS,我只需要设置 200 台机器就可以了呢?答案当然是否定的。因为任何的页面接口都不是单独存在的,都会受到公共资源的制约,如:DB、Redis、MQ、网络带宽等。比如当店铺首页达到 10w QPS 的时候,商品详情页可能要达到 8w 的 QPS了,也会消耗公共资源。当公共资源的能力下降时,势必会影响所有的系统。所以,通过单机性能算出来的理论值,跟实际情况会相差很远。
正常来说,任何大促都会有业务目标,这个目标一般是拿 GMV 进行评估。但是我们在进行系统容量评估的时候,一般会想扩大多少台机器。那么 GMV 跟核心链路各个系统之间的机器数量的转化关系是什么样的?
做过大型分布式系统的同学,可能都知道一个事实,即整个集群的性能其实取决于接口的短板效应。而这个短板的接口,在正常的流量下,是不会显现出来的。只有集群的整体压力达到一定值的情况下,才会偶尔显现, 然后造成雪崩效应,拖累整个系统集群。所以,如何在大促之前找到这些短板,然后把它们一个一个优化,这件事情就显得非常重要。
应用系统的扩容相对而言是比较简单的,完成大促之后,可以很容易归还。但是 DB 等核心资源的扩容其实并不容易,而且资源不可能归还(数据不不可丢失)。
事实是检验真理理的唯⼀一标准,上面提到的五个困难,其实都可以用线上真实压测的办法去检验。业内大型电商公司,会用全链路压测的方案去指导扩容的进程,有赞也不例外。今年双十一,有赞用该方案完成了对核心链路20 倍的扩容,但是整个集群的规模只是扩大了了一倍多一点。
全链路压测的目标是让双十一要发生的事情提前发生,并验证在该情况下系统表现良好。做线上压测,有一个很重要的原则:线上系统是不允许有脏数据的。
有赞的压测设计方案,可以用几句简单的话做概括:
有图有真相,我们先上图。
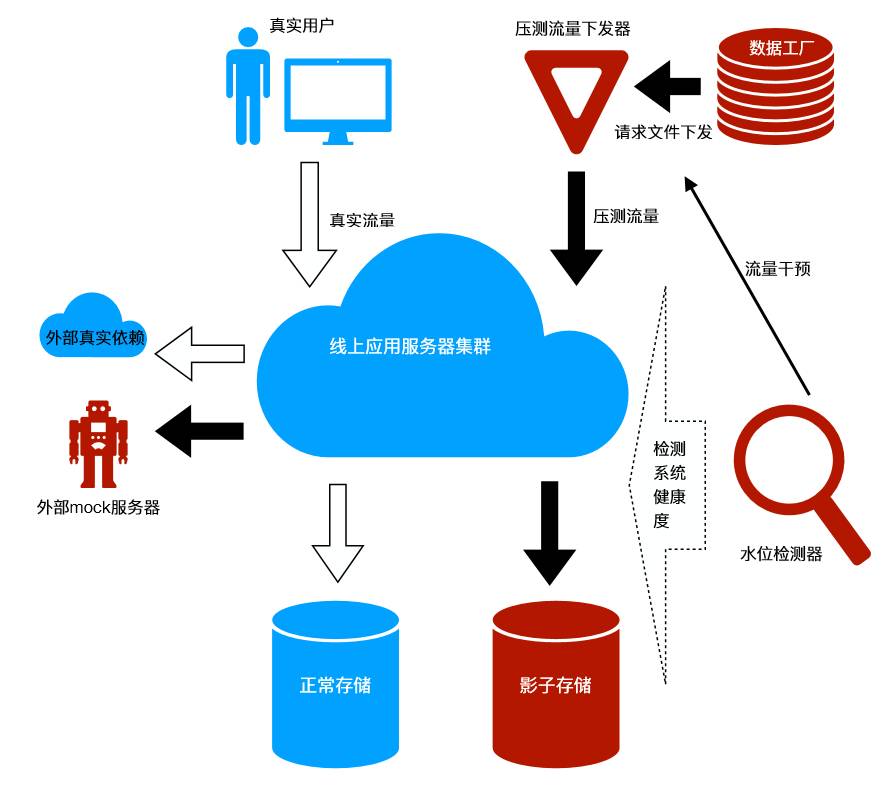
在上述图中,我们明显可以看到,全链路压测有几个关键部分:
-
数据工厂,负责造请求数据。
-
大流量下发器,产生很大的压力去压系统。
-
线上服务集群同时处理压测请求 + 正常请求。
-
压测流量落影子存储,正常流量落正常存储。
-
压测流量对于外部的依赖走 mock 服务器,正常流量走正常外部集群。
-
水位检测,需要检测存储 + 线上应用服务器的健康度,并且能够干预流量下发。
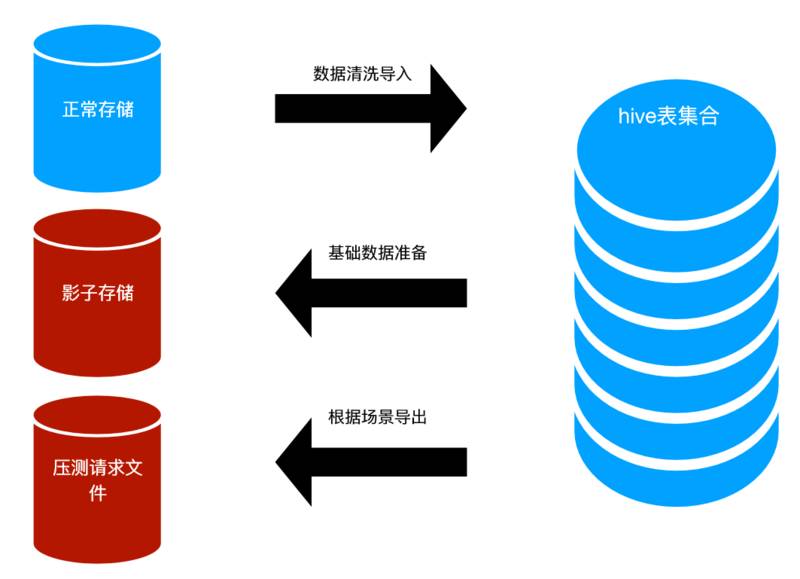
数据工厂是压测的一个核心部件,主要由 Hive 表的集合 + 各种导入、导出脚本组成。
数据工厂的目的是保存压测需要准备的所有数据,数据需要做清洗,比如:
-
商品未下架
-
商品的库存无限
-
营销活动的信息有效,未过期
-
店铺未关闭等等
场景的定义:
场景的定义关系到数据的准备,正常来说,压测只会压随着买家人数暴增、系统的压力立即增加的场景,我们把这个场景涉及到的系统叫做“核心链路”。
-
DB、路由方式由 RDS 提供,存储可以有两种方式:
-
Redis:通过 key 值来区分。压测流量的 key 值加统一前缀,通过 Redis-Client 做路由。
-
HBase:通过命名空间做隔离。影子空间加前缀,提供统一的 HBase Client 做数据访问,由该 Client 做路由。
-
ES:通过 index 名字来区分。影子的索引统一加前缀,提供统一的 ES Client 做数据访问,由该 Client 做路由。
-
统一线上应用对于数据的访问(DB+ES+HBase+Redis),提供统一的 Client。
-
由于线上的应用都是服务化工程,远程调用时,必须具备压测流量的标记透传能力。
-
线上的少部分应用,需要访问第三方服务,比如:物流、支付。这些应用需要改造为压测的流量直接访问 mock 服务器。
我们选用 gatling 作为我们的流量下发器实现。
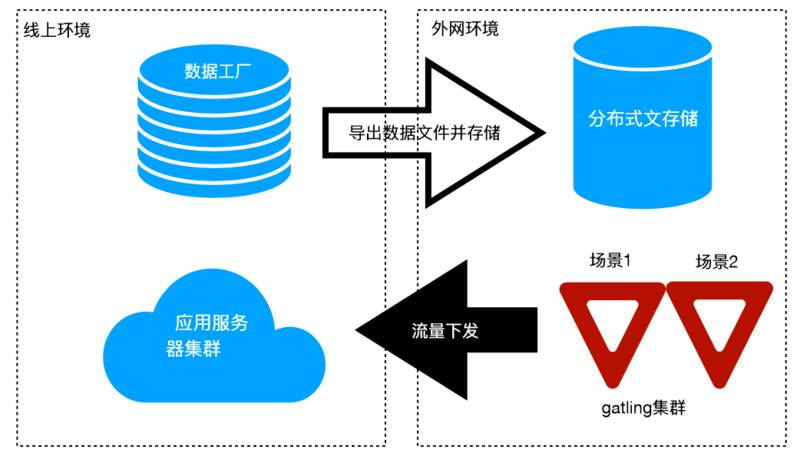
每一种场景都有不同的数据文件,数据文件由场景相对应的多种 url 组合而成。比如:我们本次压测会压“无优惠的场景、秒杀场景、满减场景、拼团场景” 等等。无优惠的场景分为“店铺首页、商品详情页、加购物车页、下单页、支付页、支付成功页”等等。这个文件不涉及漏斗转化率。一般来说,一个数据文件很大(至少是 G 级别的)。所以我们的数据文件内容格式为:

流量下发脚本的核心是控制漏斗转化率:
-
不同场景的流量配比。
-
每个场景下面,url 从上往下的漏斗转化率。
gatling 提供天然的转化率配置脚本,用起来非常方便。有兴趣的同学可以自行Google。
这个是一个很重要的模块,在项目启动之初,我们希望以实时计算的方式,一边采集各个应用系统的资源使用情况 + 接口耗时 + 业务正确率,一边向 gatling 发送流量干预信号,以做到自动保护系统的目的。由于时间关系,我们并未实现这一方案。取而代之的是人肉查看实时监控界面的方式,人为去干预 gatling 的流量下发情况。
如果实施过全链路压测的项目,大家都会有一个共同的感受:做基础的组件容易,让核心业务去完成相关的升级与验证工作很难。原因只有一个:需要用全链路压测的公司,业务规模都很大,涉及的团队会特别多。梳理理清楚庞大的业务,让所有的业务团队一起发力,本身就是一件很难的事情。
我们把链路压测的实施分为以下几个阶段:
-
基础中间件开发,各种框架升级开发,压测器研究与脚本开发。
-
业务升级与线下验证(人工点击,数据落影子库)
-
业务升级与线上验证(人工点击,数据落影子库)
-
数据工厂数据准备。
-
小流量下发验证(用 gatling 下发,数据落影子库)
-
大流量量压测与系统扩容
第 2、3、5 阶段,需要借助业务测试同学的力量;第 4 阶段,需要借助业务开发同学的力量;第 6 阶段,则需要借助业务团队 + 运维同学的力量。
由于每个阶段人员都不太一样,所以需要每一个阶段都组织不同成员的虚 拟小组,借助各个团队的力量完成相应的工作。
正常来说,在大促之前做压测,目的一般是给扩容 / 优化做方向性的指导。
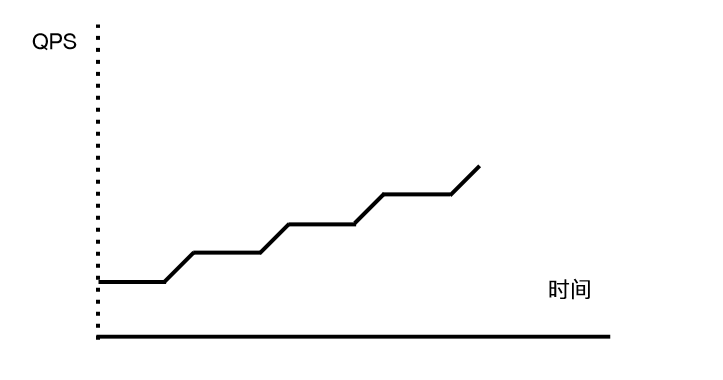
假设我们双十一需要扩大 20 倍的容量以应对高峰,那我一定不会一开始 就拿 20 倍的流量去压我们的系统,因为这样做的话,所有的系统都会在一瞬间就挂掉,这样没有任何意义。我们的做法是,阶段性的爬坡打流量,然后把系统的能力一段一段提升上去。
例如:
-
第一天,我们会以日常流量的最高峰为起始流量,然后爬坡到一个流量高峰 A,记为第一天的目标。在压测之前先做一次扩容。在压测中,碰到了某个瓶颈了,通过增加该系统的机器来提升能力。
-
第二天,我们以 A 为起始流量,然后再次爬坡到 B。同样压测前做扩容 + 压测中碰到瓶颈加机器。
-
以此类推,一直到最终流量达到目标流量为止。
-
每一天的压测,也需要以慢慢爬坡的方式提升流量。在爬坡的某个高度稳定 5 分钟,然后再次爬坡。稳定时间 5 分钟,爬坡时间 30 秒。
发现并解决这个问题,本身就是压测的目的之一。










