AI 科技评论按
:本文作者徐阿衡,原文载于其个人
主页
,AI 科技评论获其授权发布。
8月16日,在北京中科院软件研究所举办的“自然语言处理前沿技术研讨会暨EMNLP2017论文报告会”上,邀请了国内部分被 EMNLP 2017录用论文的作者来报告研究成果。整场报告会分为文本摘要及情感分析、机器翻译、信息抽取及自动问答、文本分析及表示学习四个部分。感觉上次的
CCF-GAIR 参会笔记
写的像流水账,这次换一种方式做笔记。
本文分为四个部分,并没有包含分享的所有论文。第一部分写我最喜欢的论文,第二部分总结一些以模型融合为主要方法的论文,第三部分总结一些对模型组件进行微调的论文,第四部分是类似旧瓶装新酒的 idea。
I like
Multimodal Summarization for Asynchronous Collection of Text, Image, Audio and Video
异步的文本、图像、音视频多模态摘要,一般的文本摘要关注的是 salience, non-redundancy,这里关注的是 readability, visual information,visual information 这里说的就是图片信息,暗示事件的 highlights。考虑一个视频新闻,本身有视觉模态和音频模态,通过 ASR,还可以产生文本模态,问题是如何将这些模态连接起来,产生一个附带精彩图片的文本摘要呢? 这篇论文就在讨论这个问题,整个模型输入是一个主题的文本以及视频,输出是一段附图片的文本摘要。
1、预处理:
视频产生图片:CV 基本思路,把 Video 切成一个个的 shots(镜头/段落),每个镜头可以 group(组合) 成一个 story(scene),每一个镜头还可以细分成 sub-shots,每个 sub-shot 可以用 key-frame 来表示,选择关键帧作为视觉信息,同时认为长镜头的图片相对于短镜头更重要,基于此对图片重要性进行打分。
音频产生文字:ASR。一方面语音识别结果并不十分准确,另一方面音频模态会有一些音频信号可以暗示我们哪些内容是重要的,基于这两点会产生两个指导策略,稍后提到。
2、文本重要性打分:
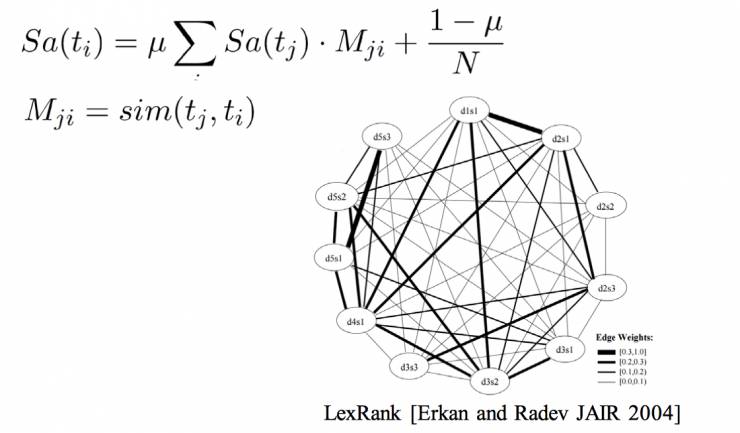
用
LexRank
,句子是点,连线是重要性,进行随机游走,针对音频产生文字的两个特性使用两个指导策略:
这两条指导策略会提升文本可读性。

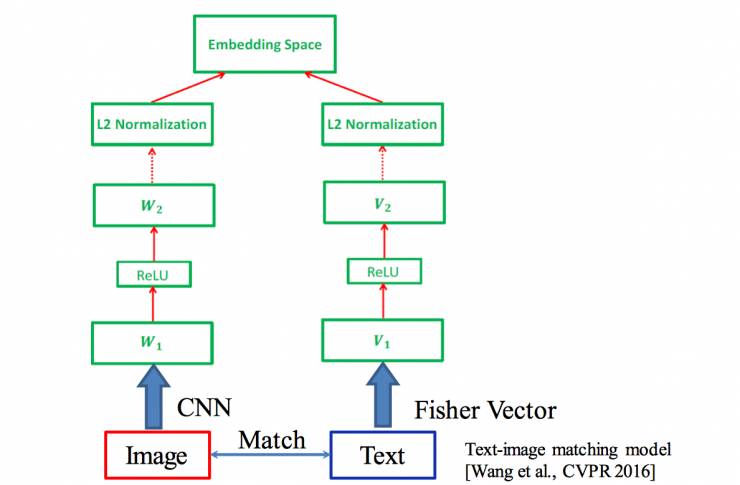
3、图文匹配问题:
希望摘要能覆盖视觉信息,能解释图片,所以需要做一个文本图片分类器。图像 vcr 解码接两层前向网络,文本做一个高斯分布再求 fisher rank,也是接两层前向网络,最终将两个文本映射到同一个语义空间,计算匹配度。
一个问题是如何在复杂的句子里提出子句,作者提出了基于传统语义角色标注的方法,利用中心谓词提取匹配的 frame 信息(predicate, argument1, argument2),好处是可以抽取语义相对独立的部分,还可以通过 frame 的设定(只取施、受、谓词)过滤如时间等图片很难反映的信息。
4、目标函数:
提到了三个目标函数:

下面一篇 Affinity-Preserving Random Walk for Multi-Document Summarization 多文档摘要也用到了图排序模型,这里略过。
Reasoning with Heterogeneous Knowledge for Commonsense Machine Comprehension
聚焦两个问题:如何去获取并且表示常识知识?并且如何应用获取到的常识知识进行推理? 论文尝试从多个不同来源的异构知识库当中获取了相关的信息,并将这些知识统一表示成了带有推理代价的推理规则的形式,采用一个基于注意力机制的多知识推理模型,综合考虑上述所有的知识完成推理任务。
任务类型: 在 RocStories 数据集上,在给定一个故事的前 4 句话的情况下,要求系统从两个候选句子当中选出一个作为故事的结尾。
推理规则:统一将知识表示成如下的推理规则的形式,在关系 f 下,元素 Y 可以由元素 X 推出,其推理代价是 s。

知识获取
主要从不同来源获取三类知识,包括:
-
事件序列知识(Event Narrative Knowledge)
捕捉事件之间的时间、因果关系(去了餐馆 -> 要点餐)
采用两个模型来捕捉这个信息,一种是基于有序的 PMI 模型,另外一个基于Skip-Gram的向量化表示模型,本质都是基于事件对在文本当中的有序共现的频繁程度来计算推理规则的代价的。
-
实体的语义知识(Entity semantic knowledge)
捕捉实体之间的语义关系。
以星巴克为例,捕捉的第一种关系是实体间的共指关系(coreference),比如说用“咖啡屋”来指代星巴克。从 Wordnet 来获取实体间上下位关系的知识。cost 是 1 当且仅当 X 和 Y 是同义词或者有上下位关系
第二种关系是相关关系(associative),比如说出现星巴克时可能会出现“拿铁咖啡”这一类与之相关的实体。通过 Wikipedia 中实体页面的链接关系来得到实体间的相关关系知识,Cost 是两个实体间的距离(Milne and Witten(2008).)
-
情感的一致性知识(Sentiment coherent knowledge)
捕捉元素间的情感关系
故事的结尾和故事的整体的情感应该基本上保持一致,否则结尾就会显得太突兀,那么这样的结尾就不是一个好的结尾。从 SentiWordnet 上来获得这种不同元素之间的情感一致性的知识。cost 为 1 if both subjective and have opposite sentimental polarity; 为 -1 if both subjective and have same sentimental polarity; 否则为 0
上述推理规则代价的计算方式不同,论文使用了一种类似于 Metric Learning的方式,通过在每个类别的推理规则上增加了一个非线性层来自动学习对不同类别的推理规则代价的校准。
另外,由于否定的存在会反转事件关系以及情感关系的推理结果,论文对否定进行了特殊处理。
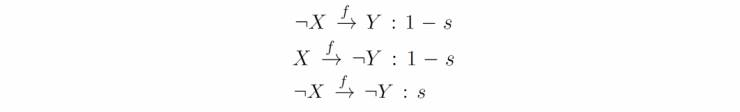
知识推理
如何将规则用到阅读理解之中?换句话说,就是在给定一个文档和候选答案的基础上,如何衡量候选答案是否正确?首先将文档以及候选答案都划分为元素,整个推理的过程就被转化成了一个推理规则选择以及对这个推理的合理性进行评估的过程。
重要假设:一组有效的推理应当要能够覆盖住结尾当中的所有元素。换言之,结尾当中出现的每一个元素,都应当能够在原文当中找到它出现的依据。
对于同样的一个文档和候选答案,我们可以有多种多样不同的推理。

上面一个推理就是一组有效的推理,这组推理是很符合人的认知的。因为我们通常会通过 Mary 和 She 之间的实体共指关系、Restaurant 和 order 之间的序列关系以及 restaurant 和 food 之间的相关关系来判断这个结果是不是成立的。
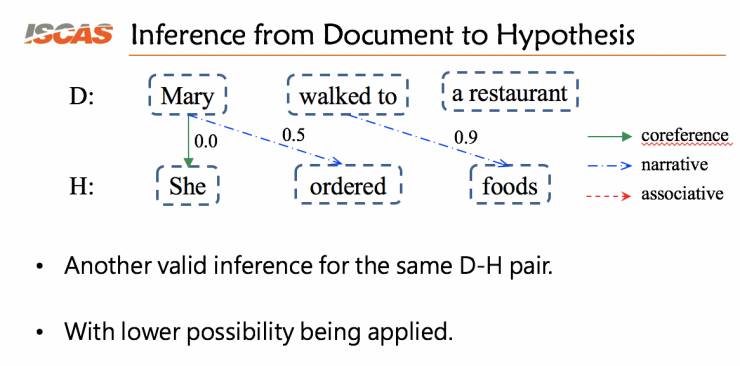
这个就不怎么合理,因为我们不太会去考虑一个人和一个事件之间是不是有时序关系,以及考虑 walk to 这样一个动作和 food 之间的联系。
采用每一种推理的可能性是不同的,用 P(R|D,H)P(R|D,H) 来对这种推理的选择建模,基于元素独立性假设,得到下面的式子

是否选择一条推理规则参与推理一个假设元素 hihi,取决于对于原文当中推理得到 hihi 的元素 djdj 的选择,以及对于 djdj 到 hihi 之间推理关系的选择。然后将这个概率分布重新定义了一个重要性函数,与三个因子相关:
-
s(h,d)
文档中的元素与候选答案中元素的语义匹配程度
-
a(h,f) 以及 a(d,f)
一个元素与这条推理规则的关系的一个关联程度,使用一个注意力函数来建模这种关联程度

将原文到候选的推理代价定义成其所有有效的推理的期望代价
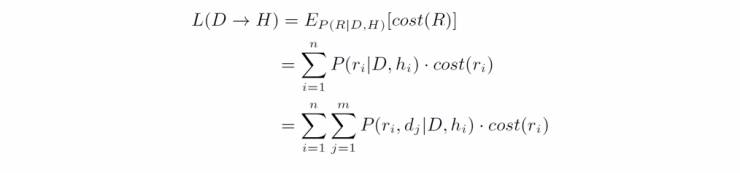
使用一个 softmax 函数来归一化所有候选的代价值,并且使用最大后验概率估计来估计模型当中的参数。
实验
三个 Baseline 进行了比较:
-
Narrative Event Chain (Chambers and Jurafsky, 2008)
仅仅考虑是事件与事件之间的关联信息
-
DSSM (Huang et al., 2013)
将文档和候选答案各自表示成了一个语义向量,并且计算它们之间的语义距离
-
LSTM 模型 (Pichotta and Mooney, 2015)
通过对先前的事件进行序列建模来预测后面发生事件的概率。

不同知识的影响

每一种知识都能够起到作用,移除任何一种知识都会导致系统的performance显著地降低。
推理规则选择方式加入 attention 机制的影响

其他
一是推理规则怎样产生更多更复杂的推理?二是训练数据,一方面,常识阅读理解数据还是很缺乏,可能需要半监督或远程监督的方法来拓展训练数据;另一方面,可能需要扩展更多的数据源。
Neural Response Generation via GAN with an Approximate Embedding Layer
生成式聊天系统可以看作是一个特殊的翻译过程,一个 question-answer pair 等价于 SMT 需要处理的一条平行语料,而 SMT 的训练过程实际上也就等价于构建问题和答案当中词语的语义关联过程。NMT 作为 SMT 高级版可以用来实现聊天回复的自动生成。这种新的自动聊天模型架构命名为 Neural Response Generation(NRG)。
而现在 NRG 存在问题是生成的答案严重趋同,不具有实际价值,如对于任何的用户 query,生成的结果都有可能是“我也觉得”或“我也是这么认为的”,这种生成结果被称为 safe response。safe response 产生原因如下:
聊天数据中词语在句子不同位置的概率分布具有非常明显的长尾特性,尤其在句子开头,相当大比例的聊天回复是以“我”“也”作为开头的句子,词语概率分布上的模式会优先被 decoder 的语言模型学到,并在生成过程中严重抑制 query 与 response 之间词语关联模式的作用,也就是说,即便有了 query 的语义向量作为条件,decoder 仍然会挑选概率最大的“我”作为 response 的第一个词语,又由于语言模型的特性,接下来的词语将极有可能是“也”……以此类推,一个 safe response 由此产生。
常见的解决方案包括:通过引入 attention mechanism 强化 query 中重点的语义信息;削弱 decoder 中语言模型的影响;引入 user modeling 或者外部知识等信息也能够增强生成回复的多样性。这些其实是对于模型或者数据的局部感知,如果从更加全局的角度考虑 safe response 的问题,就会发现产生 safe response 的 S2S 模型实际上是陷入了一个局部的最优解,而我们需要的是给模型施加一个干扰,使其跳出局部解,进入更加优化的状态,那么最简单的正向干扰是,告知模型它生成的 safe response 是很差的结果,尽管生成这样的结果的 loss 是较小的。这样就开启了生成式对抗网络(Generative Adversarial Networks, GAN)在生成式聊天问题中的曲折探索。
将 GAN 引入聊天回复生成的思路:使用 encoder-decoder 架构搭建一个回复生成器G,负责生成指定 query 的一个 response,同时搭建一个判别器 D 负责判断生成的结果与真正的 response 尚存多大的差距,并根据判别器的输出调整生成器 G,使其跳出产生 safe response 的局部最优局面。
一个重要的问题是如何实现判别器 D 训练误差向生成器 G 的反向传播(Backpropagation)。对于文本的生成来说,一个文本样本的生成必然伴随 G 在输出层对词语的采样过程,无论这种采样所遵循的原则是选取最大概率的 greedy思想还是 beam searching,它实际上都引入了离散的操作,这种不可导的过程就像道路上突然出现的断崖,阻挡了反向传播的脚步,使对于 G 的对抗训练无法进行下去。这篇论文就针对文本生成过程中的采样操作带来的误差无法传导的实际问题提出了解决方案。
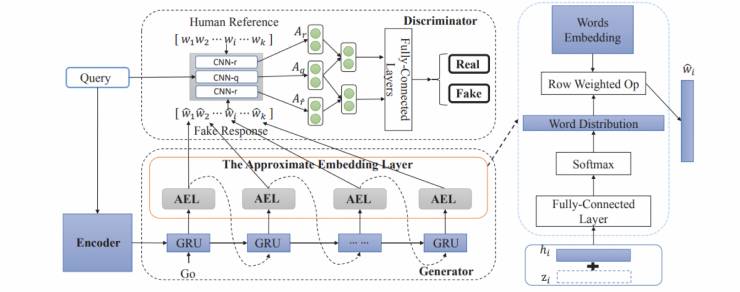
论文为生成器 G 构建了一个 Approximate Embedding Layer(AEL 如图中红色矩形框中所示,其细节在图右侧部分给出),这一层的作用是近似的表达每次采样过程,在每一个 generation step 中不再试图得到具体的词,而是基于词语的概率分布算出一个采样向量。这个操作的具体过程是,在每一个 generation step 里,GRU 输出的隐状态 hihi 在加入一个随机扰动 zizi 之后,经过全连接层和 softmax 之后得到整个词表中每个词语的概率分布,我们将这个概率分布作为权重对词表中所有词语的 embedding 进行加权求和,从而得到一个当前采样的词语的近似向量表示(如图中右侧绿框所示),并令其作为下一个 generation step 的输入。同时,此近似向量同样可以用来拼接组成 fake response 的表示用于 D 的训练。不难看出,这种对于采样结果的近似表示操作是连续可导的,并且引入这种近似表示并不改变模型 G 的训练目标。
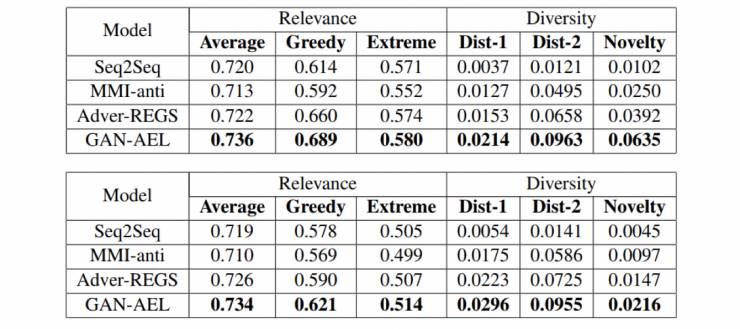
取得了不错的效果。
详细戳
首发!三角兽被 EMNLP 录取论文精华导读:基于对抗学习的生成式对话模型浅说
模型融合
把传统模型和神经网络相结合。





