redis作为目前最流行的nosql缓存数据库,凭借其优异的性能、丰富的数据结构已成为大部分场景下首选的缓存工具。
由于redis是一个纯内存的数据库,在存放大量数据时,内存的占用将会非常可观。那么在一些场景下,通过选用合适的数据结构来存储,可以大幅减少内存的占用,甚至于可以减少80%-99%的内存占用。
先来看一下场景,在Dsp广告系统、海量用户系统经常会碰到这样的需求,要求根据用户的某个唯一标识迅速查到该用户的id。譬如根据mac地址或uuid或手机号的md5,去查询到该用户的id。
特点是数据量很大、千万或亿级别,key是比较长的字符串,如32位的md5或者uuid这种。
如果不加以处理,直接以key-value形式进行存储,我们可以简单测试一下,往redis里插入1千万条数据,1550000000 - 1559999999,形式就是key(md5(1550000000))→ value(1550000000)这种。
然后用info memory看一下内存占用。
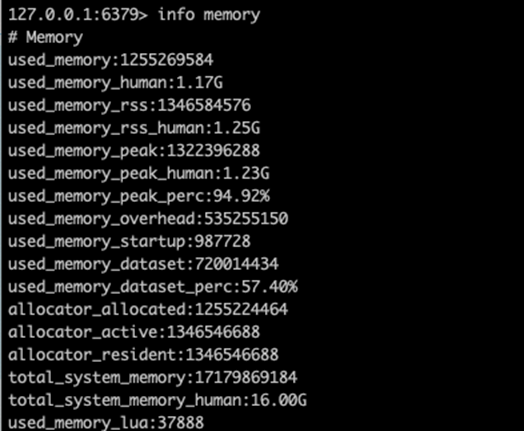
可以看到,这1千万条数据,占用了redis共计1.17G的内存。当数据量变成1个亿时,实测大约占用8个G。
同样的一批数据,我们换一种存储方式,先来看结果:

在我们利用zipList后,内存占用为123M,大约减少了85%的空间占用,这是怎么做到的呢?我们来从redis的底层存储来剖析一下。
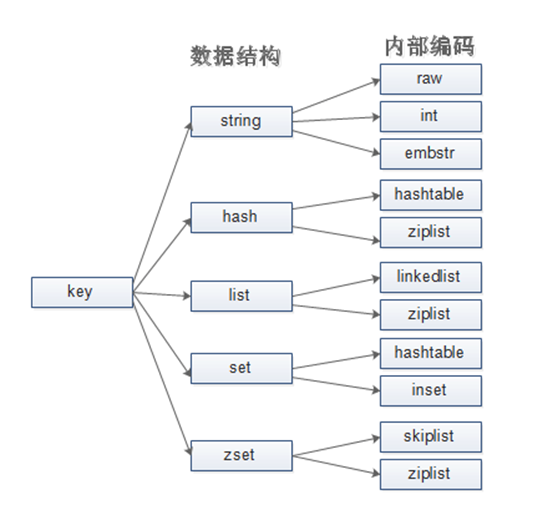
string是redis里最常用的数据结构,redis的默认字符串和C语言的字符串不同,它是自己构建了一种名为“简单动态字符串SDS”的抽象类型。

具体到string的底层存储,redis共用了三种方式,分别是int、embstr和raw。
譬如set k1 abc和set k2 123就会分别用embstr、int。当value的长度大于44(或39,不同版本不一样)个字节时,会采用raw。
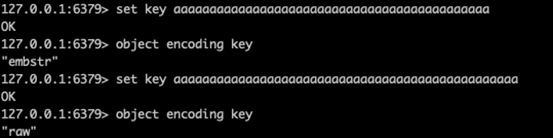
int是一种定长的结构,占8个字节(注意,相当于java里的long),只能用来存储长整形。
embstr是动态扩容的,每次扩容1倍,超过1M时,每次只扩容1M。
raw用来存储大于44个字节的字符串。
具体到我们的案例中,key是32个字节的字符串(embstr),value是一个长整形(int),所以如果能将32位的md5变成int,那么在key的存储上就可以直接减少3/4的内存占用。
这是第一个优化点。
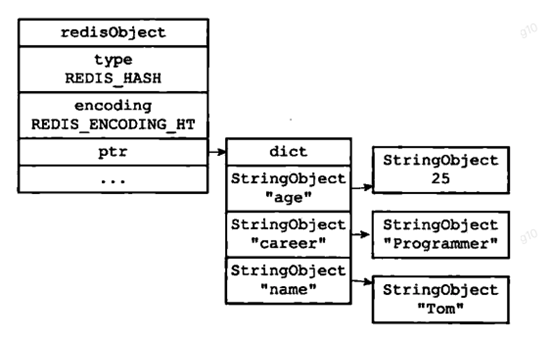
从1.1的图上我们可以看到Hash数据结构,在编码方式上有两种,1是hashTable,2是zipList。
hashTable大家很熟悉,和java里的hashMap很像,都是数组+链表的方式。java里hashmap为了减少hash冲突,设置了负载因子为0.75。同样,redis的hash也有类似的扩容负载因子。细节不提,只需要留个印象,用hashTable编码的话,则会花费至少大于存储的数据25%的空间才能存下这些数据。它大概长这样:
zipList,压缩链表,它大概长这样:

可以看到,zipList最大的特点就是,它根本不是hash结构,而是一个比较长的字符串,将key-value都按顺序依次摆放到一个长长的字符串里来存储。如果要找某个key的话,就直接遍历整个长字符串就好了。
所以很明显,zipList要比hashTable占用少的多的空间。但是会耗费更多的cpu来进行查询。
那么何时用hashTable、zipList呢?在redis.conf文件中可以找到:
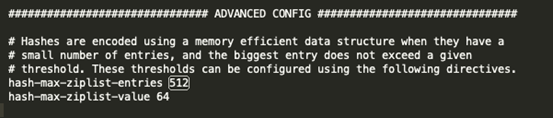
就是当这个hash结构的内层field-value数量不超过512,并且value的字节数不超过64时,就使用zipList。
通过实测,value数量在512时,性能和单纯的hashTable几乎无差别,在value数量不超过1024时,性能仅有极小的降低,很多时候可以忽略掉。
而内存占用,zipList可比hashTable降低了极多。
这是第二个优化点。
通过上面的知识,我们得出了两个结论。用int作为key,会比string省很多空间。用hash中的zipList,会比key-value省巨大的空间。
那么我们就来改造一下当初的1千万个key-value。
第一步:
我们要将1千万个键值对,放到N个bucket中,每个bucket是一个redis的hash数据结构,并且要让每个bucket内不超过默认的512个元素(如果改了配置文件,如1024,则不能超过修改后的值),以避免hash将编码方式从zipList变成hashTable。
1千万 / 512 = 19531。由于将来要将所有的key进行哈希算法,来尽量均摊到所有bucket里,但由于哈希函数的不确定性,未必能完全平均分配。所以我们要预留一些空间,譬如我分配25000个bucket,或30000个bucket。
第二步:
选用哈希算法,决定将key放到哪个bucket。这里我们采用高效而且均衡的知名算法crc32,该哈希算法可以将一个字符串变成一个long型的数字,通过获取这个md5型的key的crc32后,再对bucket的数量进行取余,就可以确定该key要被放到哪个bucket中。
第三步:
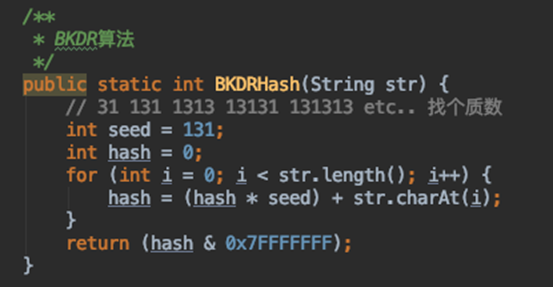
通过第二步,我们确定了key即将存放在的redis里hash结构的外层key,对于内层field,我们就选用另一个hash算法,以避免两个完全不同的值,通过crc32(key) % COUNT后,发生field再次相同,产生hash冲突导致值被覆盖的情况。内层field我们选用bkdr哈希算法(或直接选用Java的hashCode),该算法也会得到一个long整形的数字。value的存储保持不变。