选自Google Blog
作者:James Wexler等
机器之心编译
参与:黄小天、李泽南
近日,出于支持 PAIR initiative的目的,谷歌发布了 Facets,一款开源的可视化工具。它可以帮助你理解、分析和调试 ML 数据集。Facets 包含两个部分——Facets Overview 和 Facets Dive——允许用户从不同的粒度观看数据的全景图,还可以轻易地被用在 Jupyter notebooks 之内,或者嵌入网页之中。除了开放 Facets 源代码,谷歌还创建了演示网站,Github 和网站地址见文中。
从机器学习(ML)模型中取得最佳结果需要你对有数据有真正的理解。然而,ML 数据集的数据点一般有数百万种,每种包含数百个(甚至数千个)特征,致使不可能直观地理解整个数据集。可视化有助于解决大型数据集的这一难题。一图胜千言,而一个交互式可视化不止胜千言。
出于支持 PAIR initiative,我们发布了 Facets,一款开源的可视化工具,帮助你理解和分析 ML 数据集。Facets 包含两个部分——Facets Overview 和 Facets Dive——允许用户从不同的粒度观看其数据的全景图。你可以使用 Facets Overview 可视化数据每一个特征,或者使用 Facets Dive 探索个别的数据观察集。这些可视化允许你调试数据,这在机器学习中和调试模型一样重要;还可以轻易地被用在 Jupyter notebooks 之内,或者嵌入网页之中。我们除了开放 Facets 源代码,还创建了演示网站,允许任何人在浏览器中直接可视化数据集而无需安装任何软件或设置,也无需数据离开你的计算机。
Facets Overview
Facets Overview 自动地帮助用户快速理解数据集中所有特征的值分布。多个数据集(比如训练集和测试集)可在同一个可视化中进行比较。束缚机器学习的一般性数据难题被推向最前端,比如出乎意料的特征值、具有高比例遗失值的特征、带有不平衡分布的特征,数据集之间的特征分布偏态(distribution skew)。
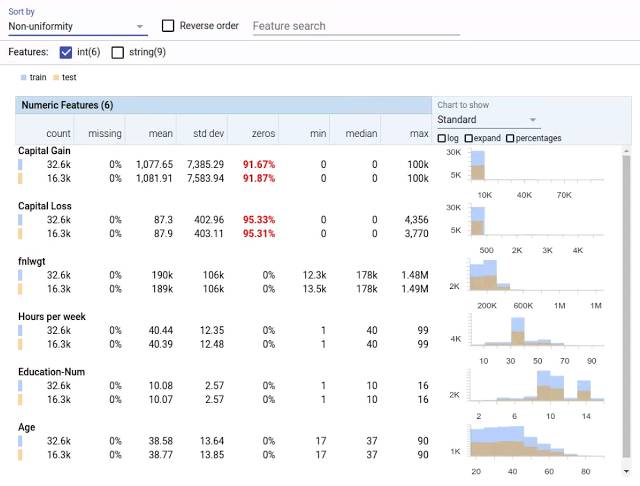
加州大学尔湾分校(UCI)人口普查数据集 [1] 的 6 个数字特征的 Facets Overview。
特征按照不均匀性排序,带有最大不均匀性分布的特征排在顶部。标红的数字表示可能的问题点,在这种情况下,带有高比例值的数字特征设置为 0。右边的柱状图允许你比较训练集(蓝色)和测试集(橙色)之间的分布。
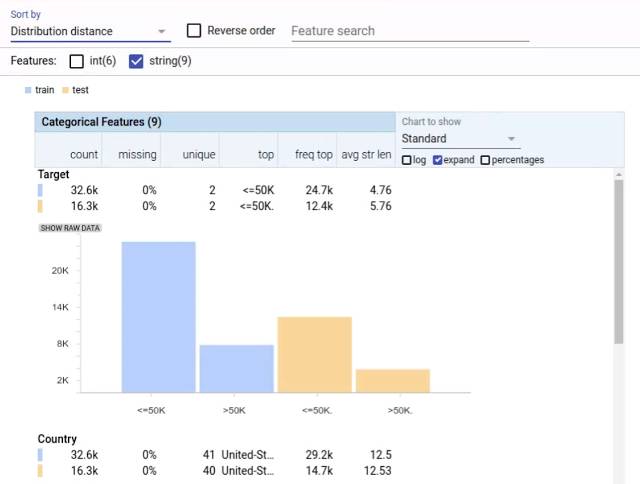
Facets Overview 展示了加州大学尔湾分校人口普查数据集 9 个分类特征中的 2 个。
这些特征通过分布间距被排序,把训练集(蓝色)和测试集(橙色)之间带有最大偏态的特征排在顶部。由于测试集中的尾随时段(「<=50K」vs「<=50K.」),「目标」特征中标签值在训练和测试集中有所不同。这可在特征的图表中查看,也可在表中「顶部」列的条目中看到。该标签不匹配将导致对该数据进行训练和测试的模型不能被正确评估。
Facets Dive
Facets Dive 提供了一个易于定制的直观界面,用于探索数据集中不同特征数据点之间的关系。通过 Facets Dive,你可以控制位置、颜色和视觉表现。如果数据点有与其相关的图像,则图像可以用作视觉表示。
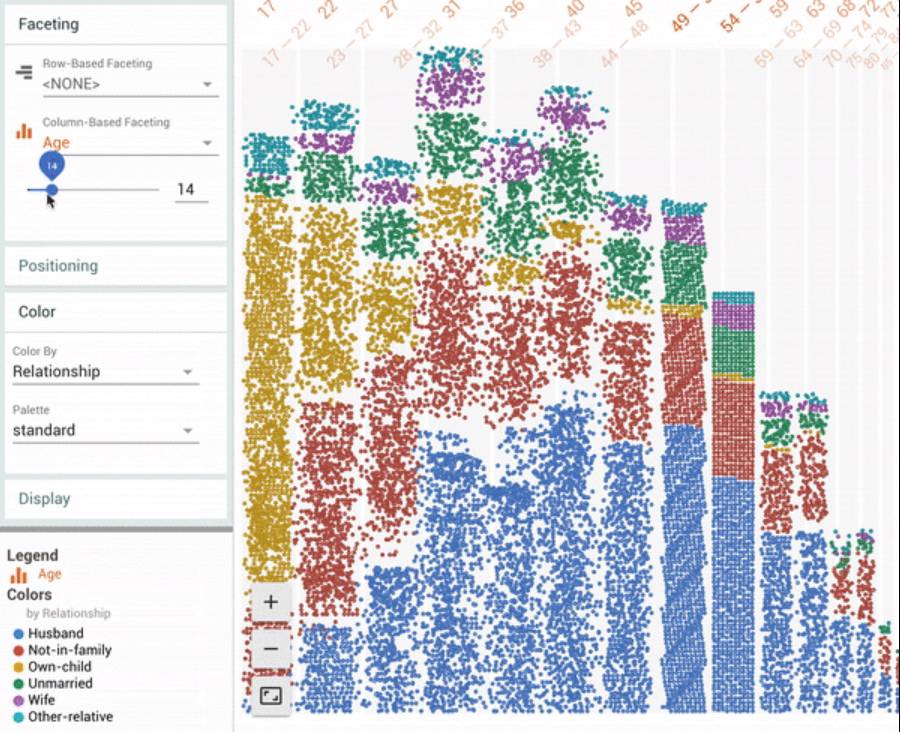
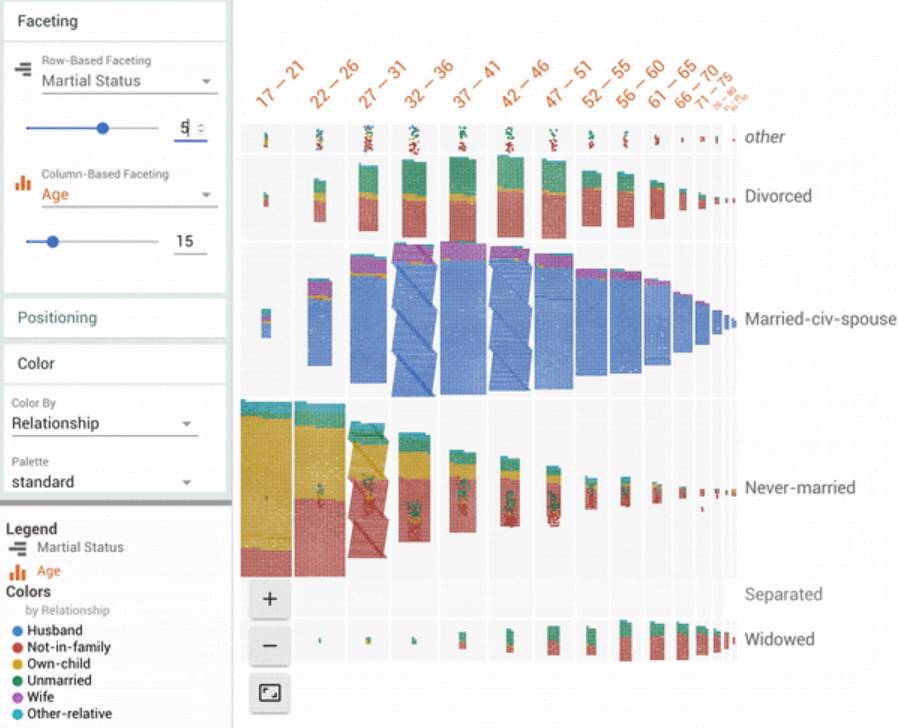
Facets Dive 可视化显示了加州大学尔湾分校人口普查测试数据集中的 16281 个数据点。
动图展示了通过对数据点颜色不同特征「关系」进行分别着色,连续特征「年龄」为一个维度,离散特征「婚姻状况」为另一个维度进行排列。
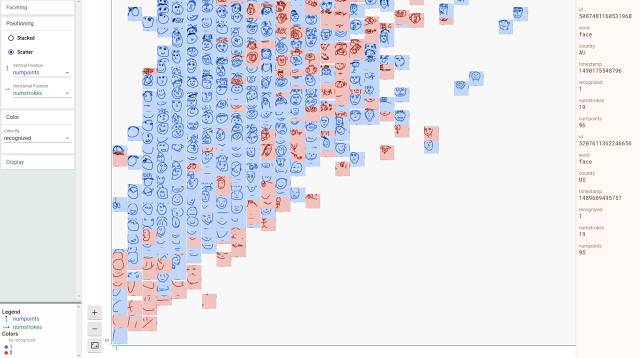
Facets Dive 从「Quick Draw」数据集中生成的可视化效果,它显示了「Quick Draw」图片中笔画和点被正确地分类为人脸。
Quick Draw 数据集:https://github.com/googlecreativelab/quickdraw-dataset
Fun Fact:在大数据集中(如 CIFAR-10 数据集),一个小小的标签错误是很容易被忽视的。我们利用 Dive 检查了 CIFAR-10 数据集,并发现了一只青蛙猫——一只被标记为猫的青蛙。

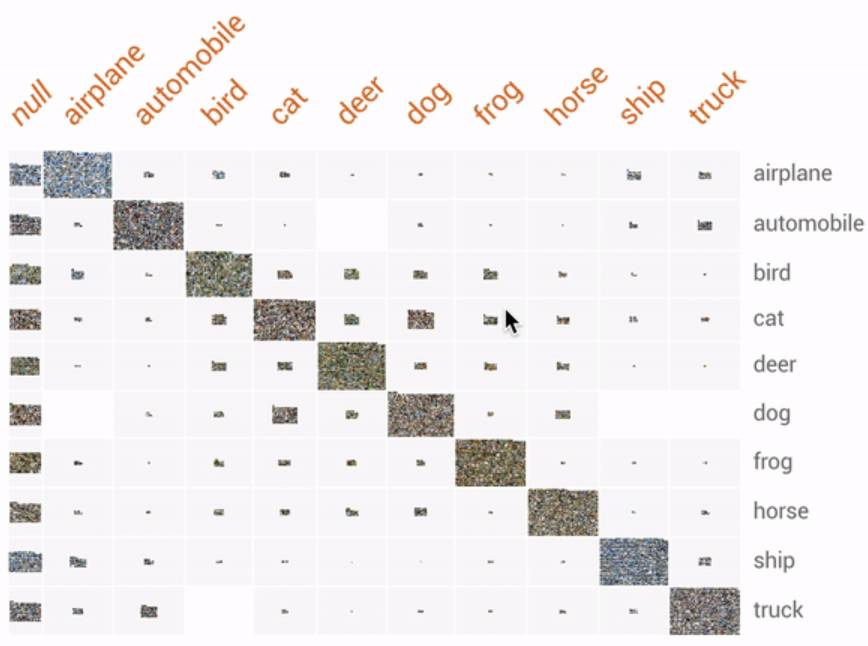
使用 Facets Dive 探索 CIFAR-10 数据集。在这里,基本分类标签为行,预测分类标签为列。
这种组合就产生了混淆矩阵视图,我们可以在其中找到特定类型的错误分类。在上面的例子中,我们可以看到机器学习模型错误地将一些猫的图片分类为青蛙。把真实图形放在混淆矩阵中让我们发现的一个有趣现象是:这些「真猫」中的一只被模型预测为青蛙是因为它在视觉检查中被定义为青蛙,这是由于模型训练的数据集中它被人为地错误分类了。

你能区分出猫和青蛙吗?
在谷歌内部,Facets 已经展现出了巨大价值。现在,谷歌希望将这份便利分享到全世界,通过发现数据中更有趣的新特征来创造更加强大和准确的机器学习模型。因为 Facets 已经开源,你可以根据自己的需求自定义可视化内容,或为项目作出贡献。
参考文献
[1] Lichman, M. (2013). UCI Machine Learning Repository
[http://archive.ics.uci.edu/ml/datasets/Census+Income]. Irvine, CA: University of California, School of Information and Computer Science
[2] Learning Multiple Layers of Features from Tiny Images , Alex Krizhevsky, 2009:https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
原文链接:https://research.googleblog.com/2017/07/facets-open-source-visualization-tool.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]
点击阅读原文,查看机器之心官网↓↓↓










