哈哈哈哈哈哈,说好的更新到现在才出现!
首先要恭喜主页菌顺利毕业!
以为毕业了主页菌就会好好写公众号
简直太天真了
但是既然说要更新这篇
「用地适宜性」
那么我也要说话算话
﹀
﹀
﹀
主页菌这次的研究范围确定在了
吉林省吉林市
,因为blablabla之类的原因,什么有代表性啊山水城市啊资源丰富啊之类的,主要是,我开心。
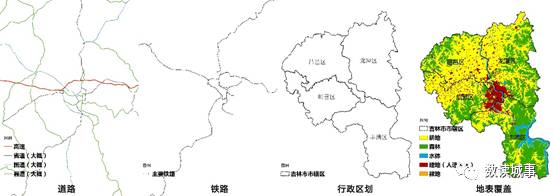
具体来说,也不是整个吉林市,而是吉林市的市辖区,
包括船营区、昌邑区、丰满区、龙潭区。
因此,需要的数据有:
行政区划、区域内道路数据、区域内铁路数据、地表覆盖数据、高程数据等
(也不是仅仅需要这些,理论上用的数据要素越多,最后的用地适宜性就越精确,怎么说呢,就是gis的一个思想,我给你一张纸,一直减去不需要的,最后就是想要的部分~)。
有的同学就想问了,数据怎么来,主页菌要说,这些数据网上基本都能找到,百度一下,你就知道,关于地表覆盖数据,也在之前的公众号文章里有说哦。
分析逻辑
为什么我要单独写这么一个章节呢,因为主页菌觉得,这个东西触类旁通,gis中很多东西都是这个原理,这样我以后就可以不用一直强调了(主要是懒)。
我们试想一下,什么样的土地适合建设?试想一下,
城市边缘比起森林边缘是不是更适合建设?过于靠近河流是不是会产生生态环境问题,而离得太远有很不宜居?
譬如此类的问题,其实是用地适宜性分析的核心,至于技术上的事情,真的就是个简单的操作的问题而已。
那要怎么确定距离河流水系多远的
区间范围
是适合建设呢?距离已有的建设用地多远又不适合建设了呢?这个问
题,就是研究重点,我不能告诉你,因为
每个城市都有自己的特点
,需要深入研究,当然也可以参考前人相类似城市的研究。
在确定了每个要素对
「适宜性」
的影响后,根据每个要素的评价进行叠加就可以得到
「用地适宜性」
分析图了。当然,这个叠加不是所有要素的评价一股脑扔进gis里叠加,叠加也是有基本法的。因为每个要素对适宜性的影响程度是不同的,很常用的确定不同要素的影响程度的方法是层次分析法,这个我们以后再讲~
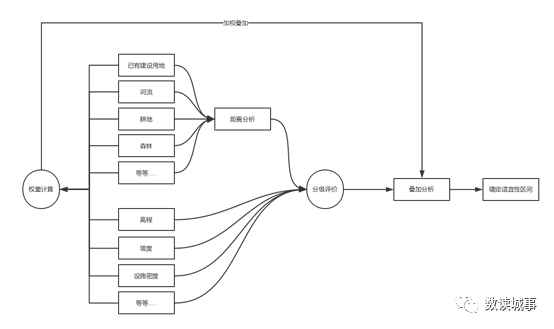
▲
适宜性分析的技术路线
讲到这里,有没有小伙伴会提出一个问题:看似很科学的用地适宜性分析,在分级评价这一块是有很强的人为主观性的。对于这个问题,主页菌也是思考过的,如果感兴趣的小伙伴可以去参考知网的一篇文章
《基于量化模型的聚落空间分布适宜性研究——以吉林省蛟河市为例》
。
在这篇文章里,主页君尝试用
二元Logistic模型
依据现状判断用地适宜性,当然只是个尝试,因此问题很多,小伙伴们可以在后台和我讨论~
数据处理
数据处理这块主页菌就简单讲一下,因为我很懒(说的这么理直气壮),所以道路、铁路之类的也没有分等级进行评价,还有很多细节是不够的,再次理直气壮的说,主页菌只是提供个大概方法,别在意细节~
那么,要开始处理数据了,铁路、公路、还有各种设施点的数据,要用
「裁剪」
工具裁剪出适合的大小,但是要注意最好不要用行政区划边界裁剪,最好略大于区划边界。
然后坡度数据根据地形高程数据很简单就可以计算出来;重点
是如何得到已有的建设用地、森林、耕地、河流水系数据呢?这里主页菌用的是2010
用地覆盖类型数据提取出的。
具体方法
1、使用
「按掩膜提取」
工具,得到研究区域内的地表覆盖数据;
2、使用
「重分类」
工具,使原有的建设用地(人造地表面)数据的值为1,其余值设置为
「Nodata」
,得到单独的“建设用地”图层;
3、同2方法,得到单独的
「
森林
」
、
「
耕地
」
、
「
河流水域
」
、
「
裸地
」
数据图层。
好,大功第一步告成。完美,撒花!
﹀
﹀
﹀
接着就是重点之一的,
利用各要素(这里的要素不是侠义的指gis里的要素数据)进行量化的过程
。
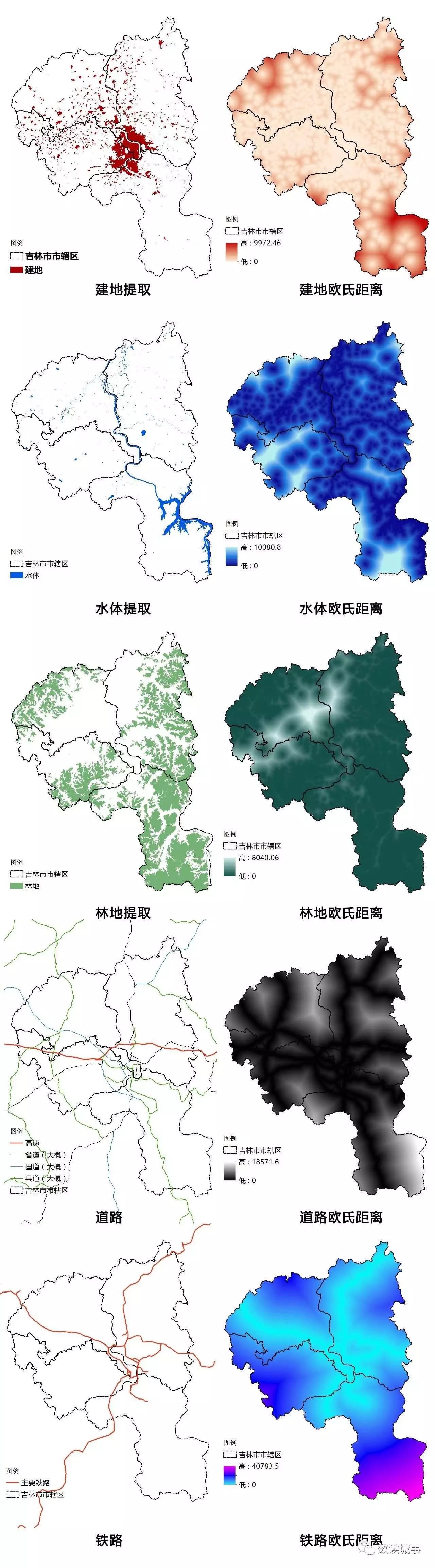
所谓量化过程,其实就是指把单独存在的要素变成可以用数字判断其适宜程度的过程,高程和坡度本来就是用数字表示所以不用管,那其实就剩下那些「建地、森林、水体、公路、铁路」之类的。
这里主页菌用的方法是
「欧式距离」
,这个工具其实就是计算每个像元到最近源的欧氏距离。
分级评价
所谓的分级评价,在软件操作层面其实就是一个工具
「重分类」
,所以重点不是操作,而是如何确定分级的区间,主页菌也说了,这需要大家自己靠研究、经验之类的,或者就是参考大牛~我这里就不那么严谨,直接上我的分级标准了(依据就是我内心斗争)。
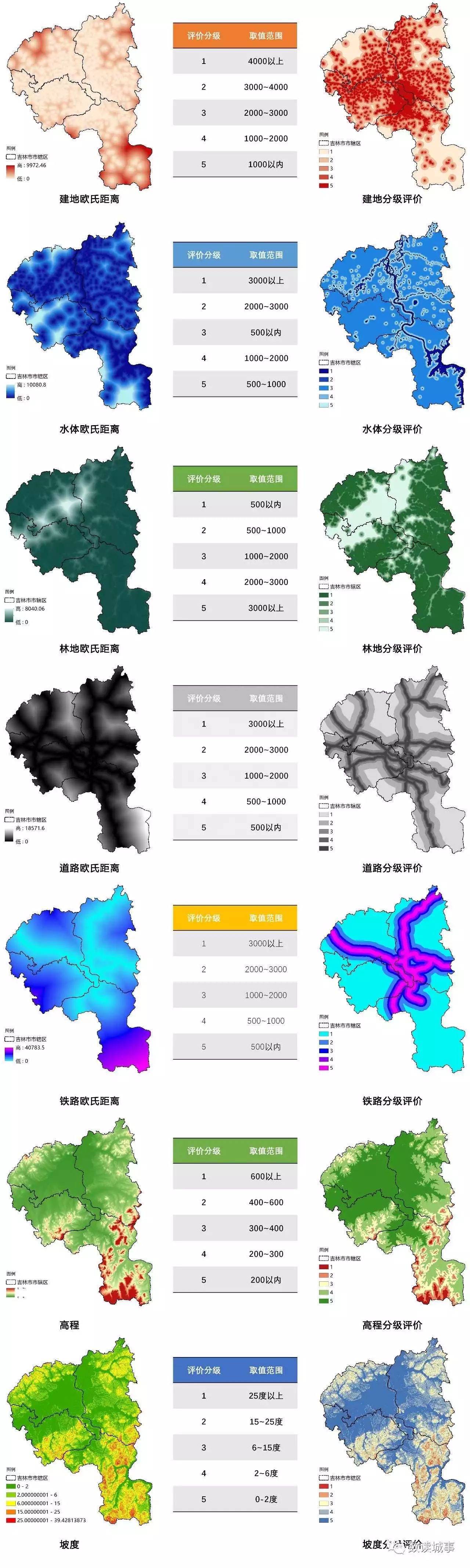
好,完事。其实主页君做的很不注意细节,所以效果么有点不尽人意。
比如「建地」
对于未开发用地的影响,理论上是根据其本身规模大小产生作用的,这个意义上,
越大的建地斑块产生的影响越大
,而小斑块(比如村庄)影响就大打折扣;
对于这种情况,可以设定一个规模大小的
阈值
,把面积小于这个值的斑块删除后再进行距离分析;诸如此类,大家自行研究吧。
叠加分析
主页君是不是在上文说过,最后的分析步骤是






