
MLNLP
社区是国内外知名的机器学习与自然语言处理社区,受众覆盖国内外NLP硕博生、高校老师以及企业研究人员。
社区的愿景
是促进国内外自然语言处理,机器学习学术界、产业界和广大爱好者之间的交流和进步,特别是初学者同学们的进步。
越来越多人发现,完整 AGI 的构建之路有一个离不开的基石:文档处理
前段时间,DeepSeek-V3 的发布在国内外掀起一波盛赞,很多朋友都在讨论如何将其用于深度企业级搜索、Agent 开发和 RAG(Retrieval Augmented Generation)等场景。

笔者自然也想好好体验一把,但在实际测试中,我会发现,“文档处理” 是摆在我眼前的一道坎:
为什么文档处理如此重要?
在构建 Agent/RAG/LLM 应用的过程中,我们往往会面临以下痛点:
-
文档格式不统一
企业内部、外部知识库以及互联网公开资料中,可能同时存在 PDF、DOCX、PPTX、扫描图像等多种格式。LLM 需要的是可以被统一解析、结构化后的文本或特定语义切分,而原始文档格式差异过大,直接传给 LLM 识别往往得不到理想结果。
-
排版复杂 / 各种异常情况
可能遇到双栏、多栏排版;标题、页眉页脚穿插;大量表格、公式、图片;甚至整份文档都是扫描版图片……如果没有合适的文档解析工具,处理下来费时费力。
-
需求多样,输出格式不一
在 Agent 或 RAG 系统中,有时候需要 Markdown 用作呈现给用户;有时候需要 JSON 便于后端自动处理;或者还需要 CSV、XML 等。要想让文档处理结果“随取随用”,就需要一个能灵活导出多种结构化格式的解析工具。
-
对延迟和稳定性要求高
不论是做即时问答、Agent 聊天还是批量构建知识库,大家都很关心处理速度和稳定性。如果解析慢、或者报错崩溃,就无法在实际生产环境中稳定落地。
以上这几点组合在一起,就导致了一个尴尬的局面:如果文档的处理链路走不通,即便大模型本身能力再强,也难以在真实业务场景中充分发挥其价值。
就在这时,我发现 IBM 最新开源了一个文档解析神器——Docling,它仅需几行代码,就可以将各类文档都转换为 JSON/Markdown,发布至今已经狂揽 16.8k 星!
这意味着,我们可以在一个管道里搞定所有格式的文档处理,然后再将结果喂给大模型进行各种问答、聊天、Agent 流程、RAG 等应用。

论文地址:
https://arxiv.org/pdf/2408.09869
开源项目:
https://github.com/DS4SD/docling
Docling 的五大特点
-
多格式支持:
无需为 PDF、DOCX、PPTX、图片等多种格式分别找工具,一个 Docling 统统搞定。
-
OCR 能力:
针对扫描件也能精准提取文字,真正做到不遗漏任何重要信息。
-
页面布局/表格还原:
可保留原文的排版信息、阅读顺序、表格行列结构,减少后续人工清洗的负担。
-
可与 LLM 集成
:结合 LlamaIndex、LangChain 这类工具,能轻松实现自动问答、检索增强生成(RAG)等功能。
-
简单易用:
Python 代码或 CLI 命令行,批量处理、单文件处理都能一键完成。
其中,docling 针对 pdf 有专门的处理逻辑:
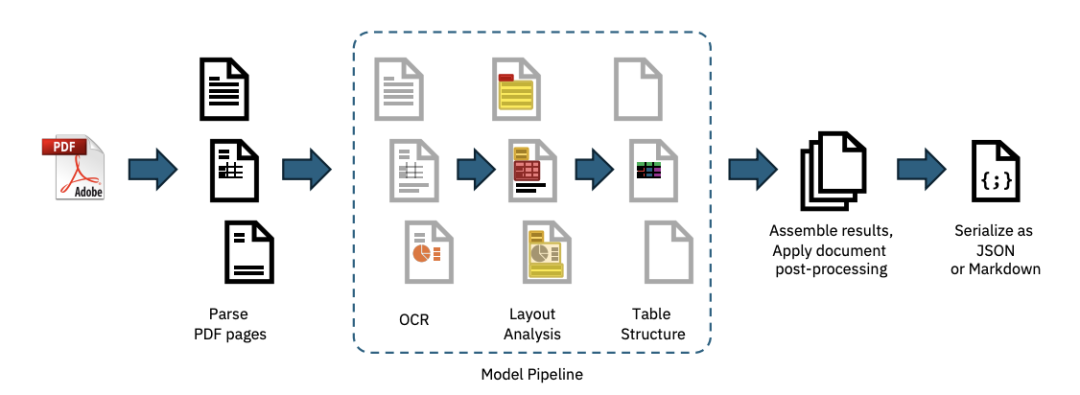
Docling 的管道原理与核心流程
官方技术报告中介绍,Docling 整个处理流程大致分为以下阶段:
-
简而言之,Docling 在“文档格式 → 可用数据结构”的过程中做了大量底层工作,把文本、图片、表格都重新“拆装”了一遍。
同时,docling 可以通过简单几行代码就完成整个文档的处理,有超高的易用性。
比如,假设我们需要处理一个 pdf,只需要下面几行代码:
from docling.document_converter import DocumentConverter
# PDF 文件可来自本地路径,也可直接是 URL
source = "https://arxiv.org/pdf/2408.09869"
converter = DocumentConverter()
result = converter.convert(source)
# 输出文档的 Markdown 格式
print(result.document.export_to_markdown())
# 也可以这样输出 JSON
import json
doc_json = json.dumps(result.document.export_to_dict(), indent=4)
print(doc_json)
那么,实际效果如何呢,让我来给它上上强度!
docling 解析效果实测
这里以更通用的 markdown 格式为例。
单列排版

解析结果:

去掉了页眉页脚,除了标题被拆分为两行以外,整体文字识别都正确,还不错!
单列排版 + 表格:
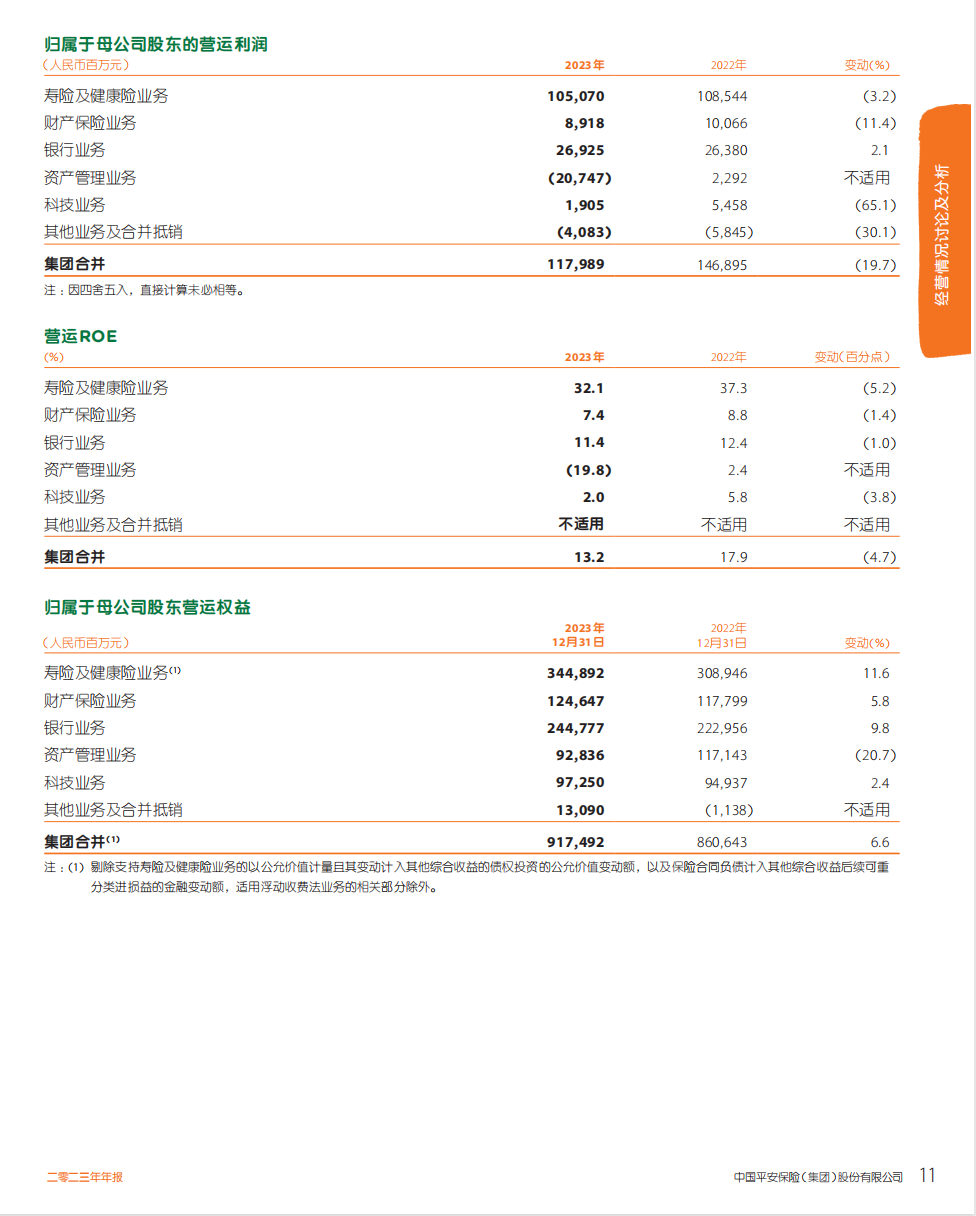
解析结果:
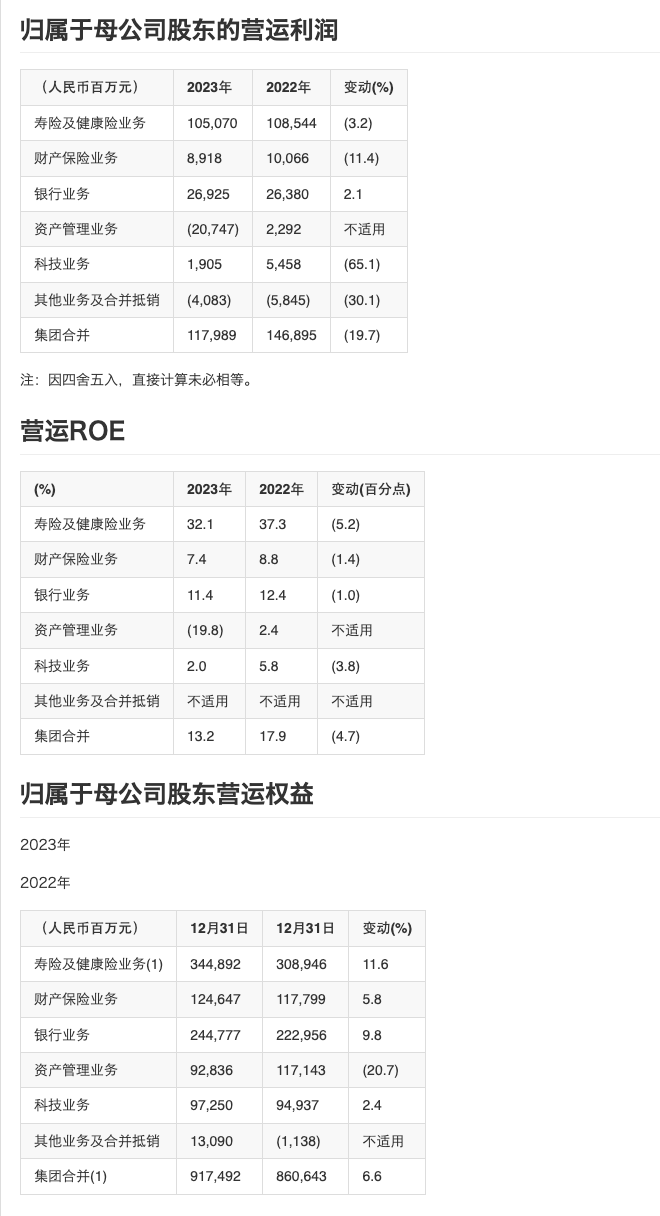
除了两个年份识别为文字,其他都没问题,有点小瑕疵,但是整体解析正确,这一关也算过 ~
双列排版 + 表格:

解析结果:

除了表格的位置有点问题,表格的格式还原的完全正确,整体文字顺序也是对的,还不赖!
单双列混合排版 + 表格
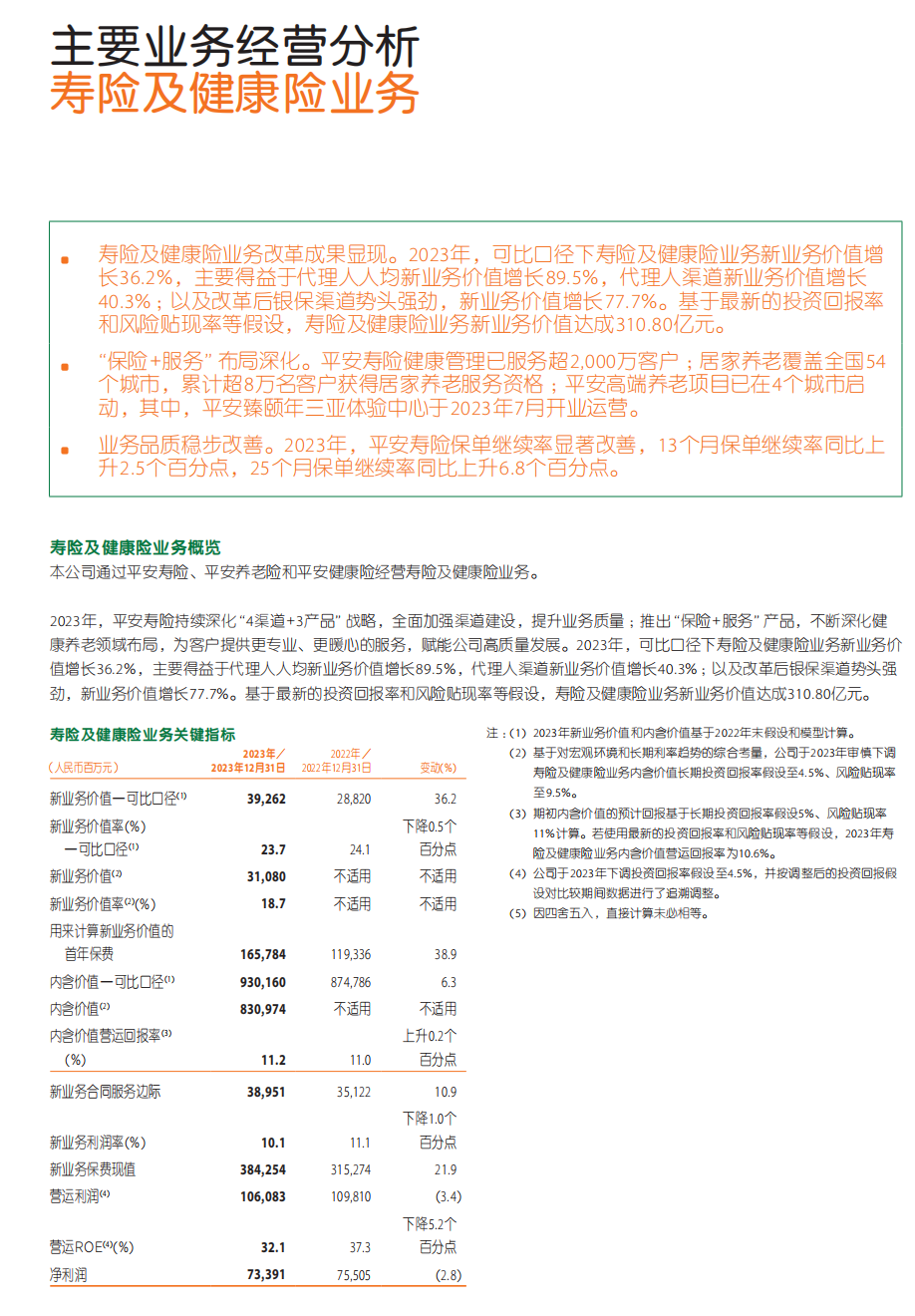
解析结果:
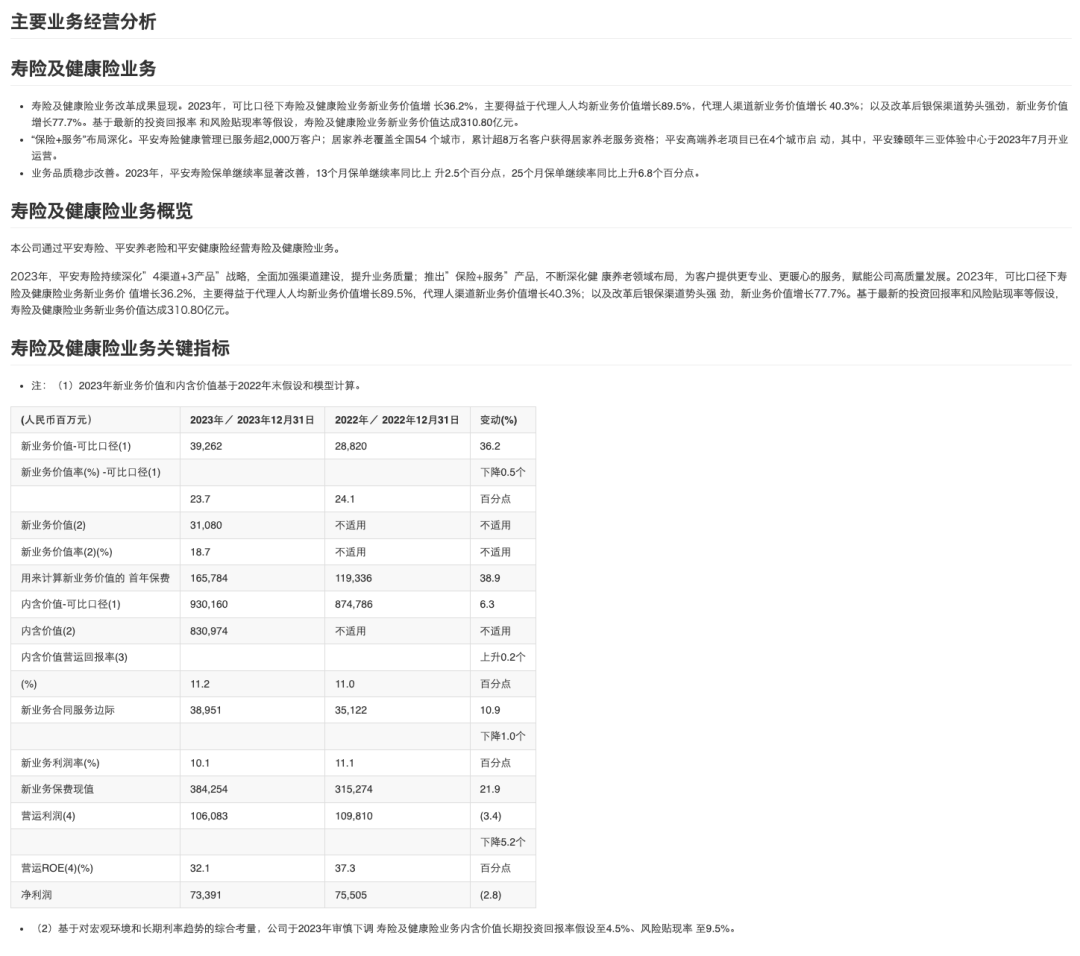
这里它就没有成功识别出下半部分是双列了,不过表格识别的还是非常准确
通过本文的简单测评来看,它虽然带有一些小瑕疵,在单双列复杂情况下没有成功还原阅读顺序,但是表格还原度非常高,可以适用于绝大部分场景了!
稳定性与延迟
在构建 Agent/RAG 系统时,处理速度与稳定性是大家非常关心的指标。特别是有些文档动辄上百页,或者需要大量同时处理。Docling 官方报告给出了在 225 页测试集上的性能数据(包括多线程与不同 PDF 解析后端):
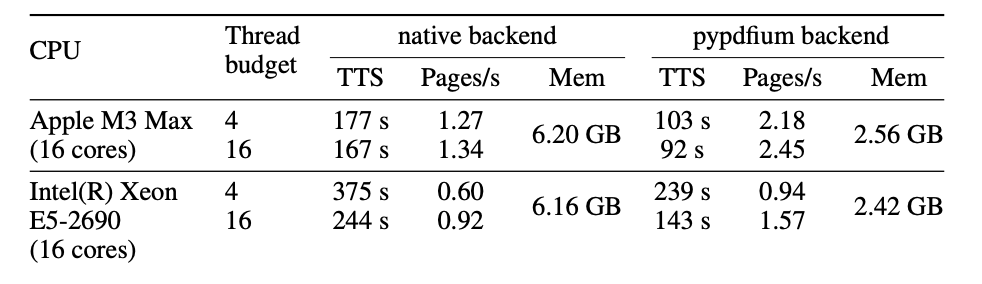
其中:
-
TTS 是总处理时长(Time to Solution),涵盖解析、模型推理、组装等所有流程;
-
单线程速度更慢,多线程能显著提升吞吐量;
-
pypdfium 作为备用后端速度更快,内存更低,但在表格处理方面精度可能略逊;
-
OCR 功能 默认关闭,若开启,每页会根据 OCR 模型和硬件性能提升处理时间。
稳定性与延迟实测
这里选了一长一短两个 pdf 简单测试一下它的提取速度。
测试环境:1xL20
测试条件:单线程
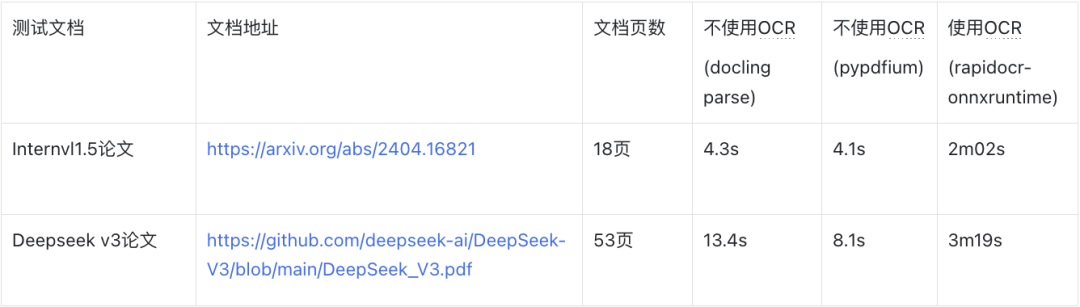
可以发现,如果 pdf 是非扫描件,不开启 OCR 会极大的提升解析速度,而如果这里使用了 OCR 模型,整体速度都会出现严重的下降。
具体如何选择,需要结合 pdf 的复杂程度和解析效果来判断。
结语
不知不觉间,markdown/json 格式似乎已经成为了 AGI 时代的“新基建”。
各种各样的文档经过解析工具快速提取并结构化输出为这两种格式后,给各类 Agent/RAG 框架提供稳定的原始文本输入。
Docling 不仅具备多格式解析能力,且对版面和表格都有较高还原度,还能通过多线程或 GPU 加速来应对大批量处理场景,加上 MIT 许可开源,不失为大家解析文档的一个好选择。










