选自Github
作者:
Max Brggen
机器之心编译
参与:蒋思源
近来,部分机器学习从业者对深度学习不能训练小数据集这一观点表示怀疑,他们普遍认为如果深度学习经过优良的调参,那么就不会出现过拟合和过训练情况,也就能较好地从小数据集学习不错的模型。在本文中,Max Brggen 在多个小数据集对神经网络和 XGBoost 进行了对比,并表明 ANN 在小数据集可以得到和 XGBoost 相媲美的结果。
模型源代码:https://gist.github.com/maxberggren/b3ae92b26fd7039ccf22d937d49b1dfd
Andrew Beam 曾展示目前的神经网络方法如果有很好的调参是能够在小数据集上取得好结果的。如果你目前正在使用正则化方法,那么人工神经网络完全有可能在小数据集上取代传统的统计机器学习方法。下面让我们在基准数据集上比较这些算法。
先从从 iris 数据集开始,因为我们可以很容易地使用 pandas read_csv 函数从网上读取数据集。
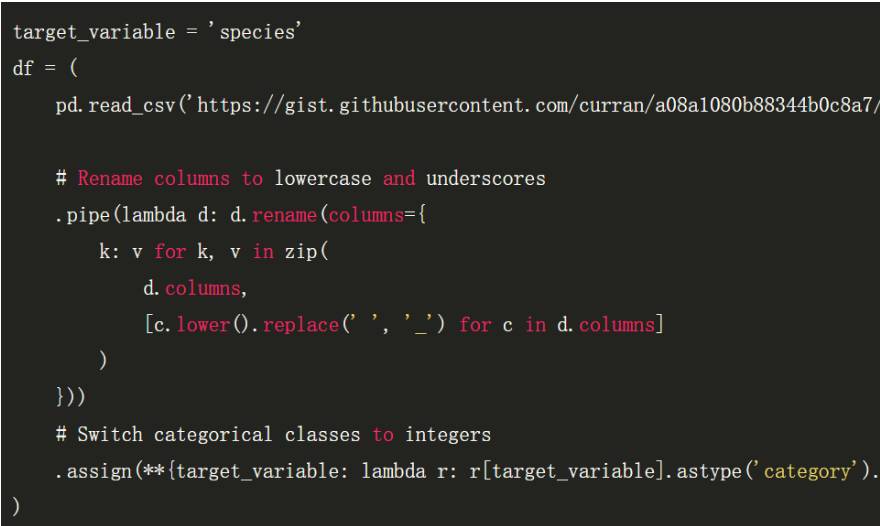
注意,上述代码块的数据集读取地址(显示不全)为:
「https://gist.githubusercontent.com/curran/a08a1080b88344b0c8a7/raw/d546eaee765268bf2f487608c537c05e22e4b221/iris.csv」
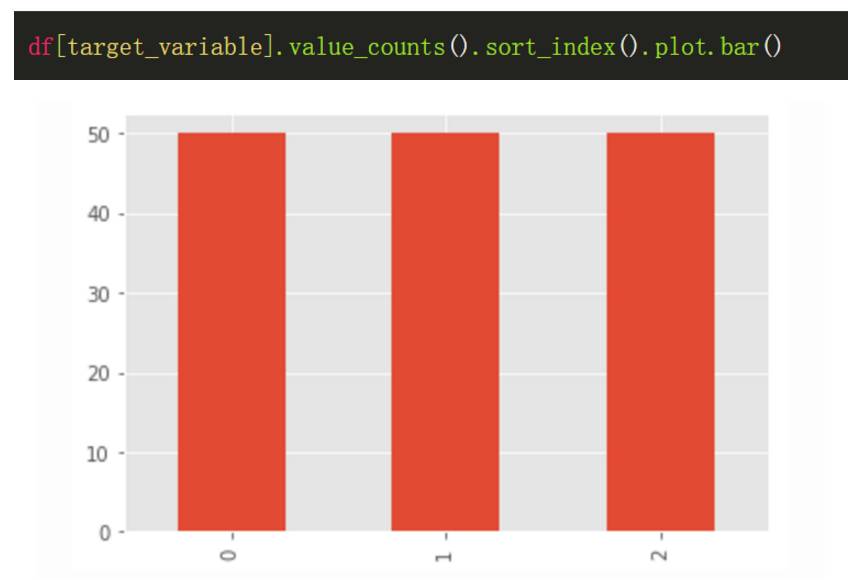
该数据集只有三个类别共计 150 个数据点,它是一个很小的数据集。
我们可以从 Pandas 数据框架中创建特征矩阵 X 和目标向量 y。因为 ANN 的特征矩阵需要归一化,所以先要进行最小最大缩放。

我们将数据集分割为训练集和测试集。

导入一些 keras 库的函数(如果没有安装 keras,可以键入 pip install keras)。

设置神经网络的深度为 3 层,每一层的宽度为 128 个神经元。这并没有什么特别的,甚至都不一定能算做深度学习,但该网络在每层之间使用了一些 dropout 帮助减少过拟合现象。
Adam 优化方法的学习率可能在其他数据集还需要微调,但是在该数据集保留 0.001 效果就已经十分不错了。
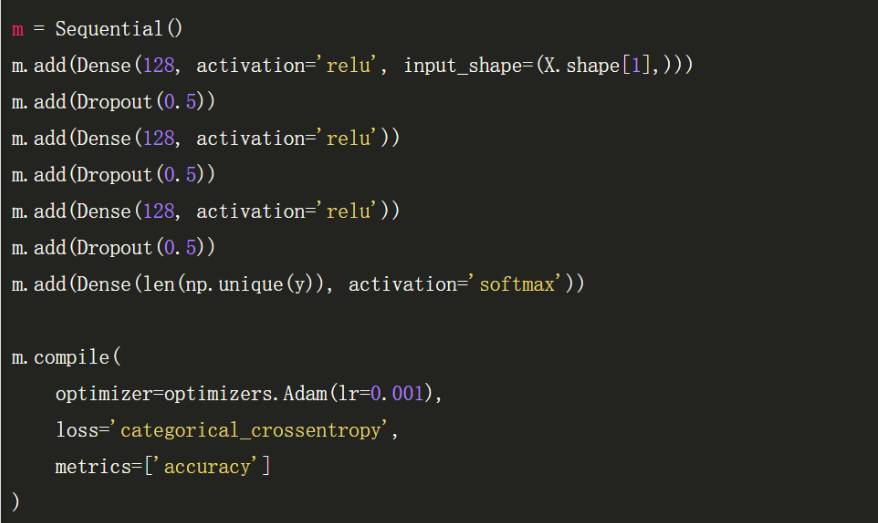
EarlyStopping 函数在验证集精度不再提高的时候可以帮助我们终止训练,同样这也会帮助我们避免过拟合。同时我们还需要在出现过拟合之前保存模型,ModelCheckpoints 函数可以让我们在验证集精度出现下降前保存最优模型。
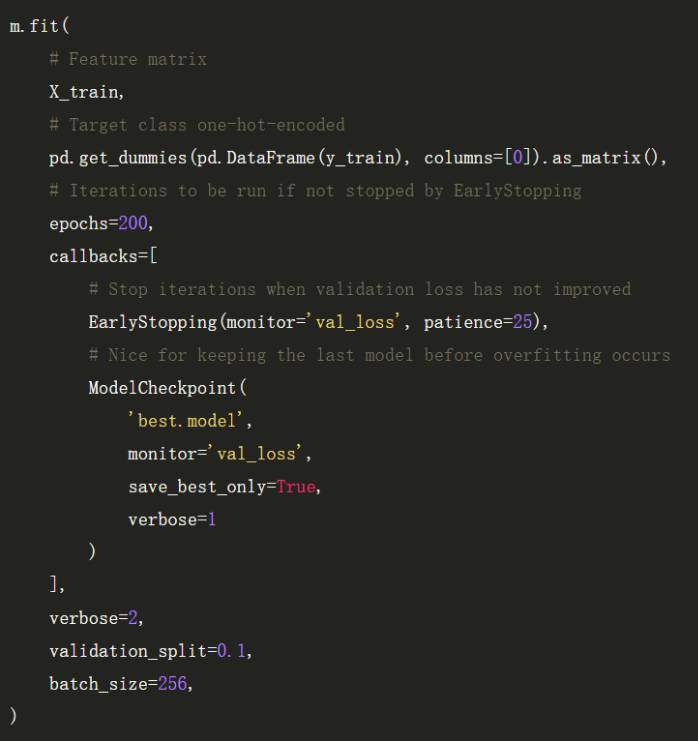
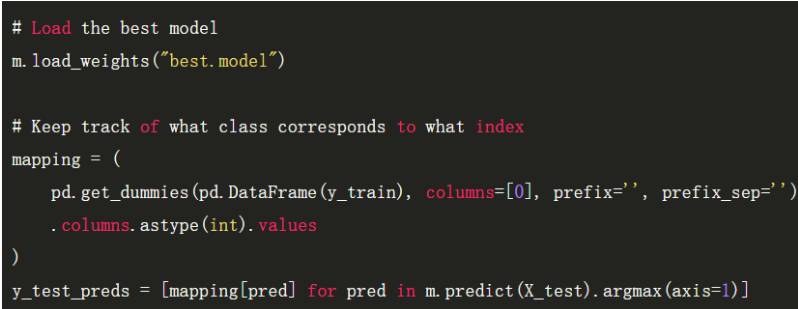
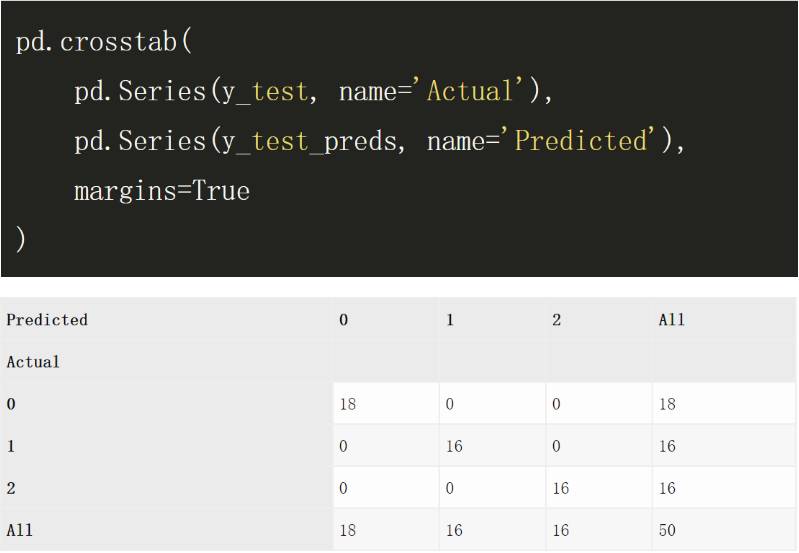
现在我们可以在测试集上评估性能,下面的混淆矩阵展示了测试集所有预测值和真实值的分布。
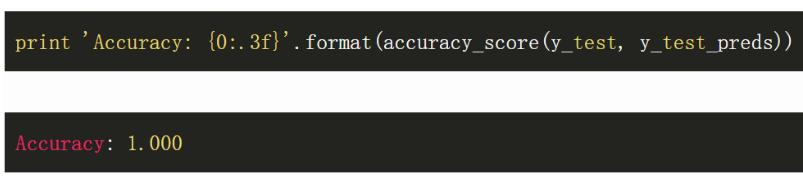
实际上该结果极其优秀。接下来我们通过 sklearn API 构建
xgboost(conda install xgboost)
模型。
寻找优良的超参数对贝叶斯方法来说是很好的任务,它能在没有任何梯度的情况下以有效的方式评估替代方案。而像 GridSearch 那样的方法需要大量的时间,因此我们反而给它一个参数空间和「预算」。所以该方法会在这些条件约束下最有效地评估 XGBoost 超参数。
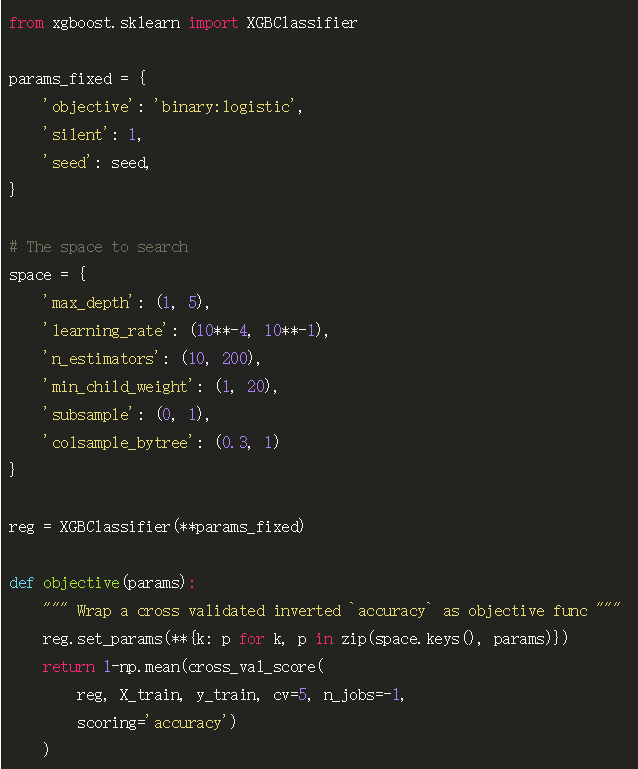
因此我们使用的是 skopt (pip install scikit-optimize)。我们给定 50 次迭代来挖掘超参数空间。

Best accuracy score = 0.96
Best parameters = {'colsample_bytree': 1.0,
'learning_rate': 0.10000000000000001, 'min_child_weight': 5,
'n_estimators': 45, 'subsample': 1, 'max_depth': 5}

下面我们需要固定这些超参数并在测试集上评估模型,该测试集和 Keras 使用的测试集是一样的。
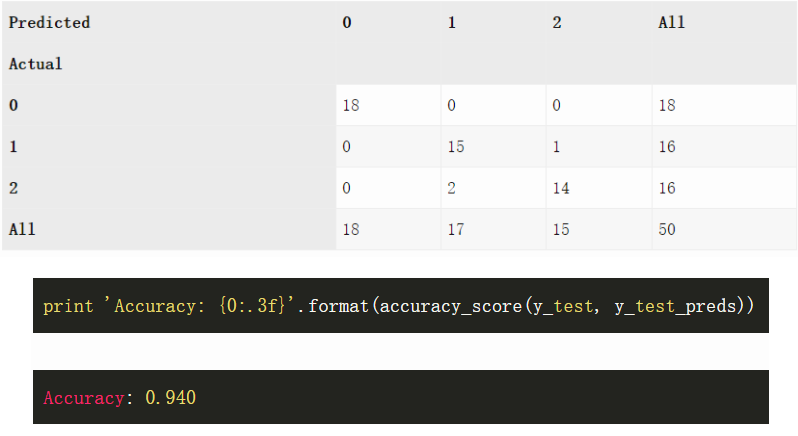
在这个基准数据集中,并不太深的神经网络全部预测正确,而 XGBoost 预测错了三个。当然如果我们改变种子并且再运行一次,XGBoost 算法也可能会完全正确,所以这一结果并不能说明神经网络就要比提升方法好,我们也不需要进一步解读。
下面我们将以上的代码进一步推广到一般情况,因此我们能嵌入任何选定的数据集,并对比两种方法的测试集精度和可能存在困难的任务。当我们在处理代码时,我们可以在精度统计值上添加一个 boostrap 以了解不确定性大小。
完整的代码可以在 Github 查看:https://gist.github.com/maxberggren/b3ae92b26fd7039ccf22d937d49b1dfd
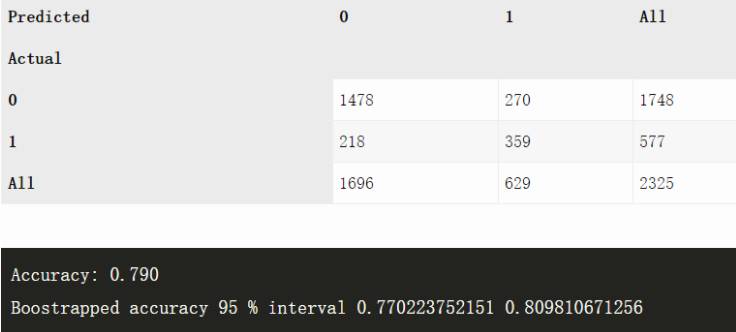
Telecom churn 数据集(n=2325)
数据集:https://community.watsonanalytics.com/wp-content/uploads/2015/03/WA_Fn-UseC_-Telco-Customer-Churn.csv?cm_mc_uid=06267660176214972094054&cm_mc_sid_50200000=1497209405&cm_mc_sid_52640000=1497209405
ANN
XGBoost
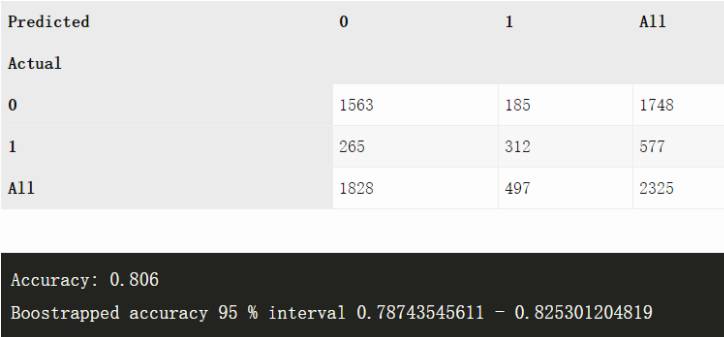
Churn 是一个更加困难的任务,但两种方法都做得挺好。
三种红酒数据集(n=59)
数据集:https://gist.githubusercontent.com/tijptjik/9408623/raw/b237fa5848349a14a14e5d4107dc7897c21951f5/wine.csv
ANN
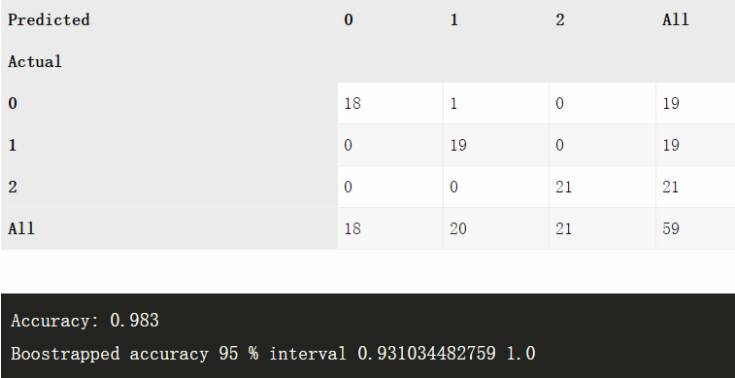
XGBoost
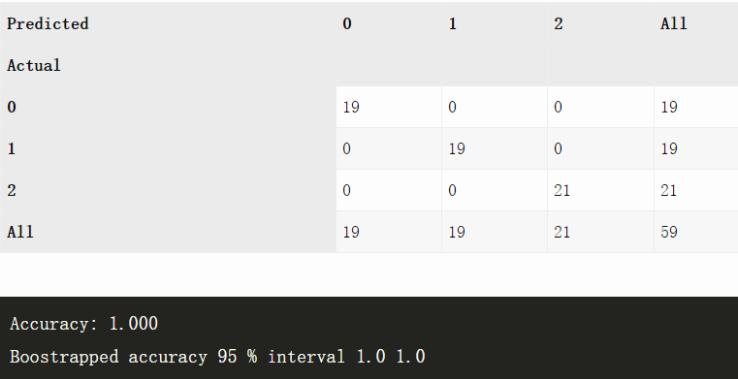
这是一个非常简单的数据集,这两种方法都没有出现异常,因为样本空间实在是太小了,所以 boostrap 基本上没起什么作用。
德国人资信数据(n=1000)

数据集:https://onlinecourses.science.psu.edu/stat857/sites/onlinecourses.science.psu.edu.stat857/files/german_credit.csv








