编程派微信号:codingpy
作者:Clinton Dreisbach,译者:isawall,校对:EarlGrey,出品:PythonTG 翻译组/编程派。
文中蓝色文字均为超链接,需要在点击“阅读原文”后才能查看。
本文来自我在 DjangoCon 2016 大会上的演讲。您可以观看演讲用的PPT。以及该智能看板的开源源代码和在线演示。
最近我和几个警局部门合作创建了一个显示 911(也被称作 Call for Service)数据的智能看板,该看板允许用户对这些数据进行进一步挖掘。当我开始这个项目的时候,已经有一个用 dc.js 写的原型,dc.js 是用于构建动态看板的 JavaScript 框架,所有的数据都在前端(data on the frontend),原型的数据记录来源于佛罗里达州的 Tampa 市。我需要基于此原型,增强其处理数据的能力 —— 上百万条数据记录。
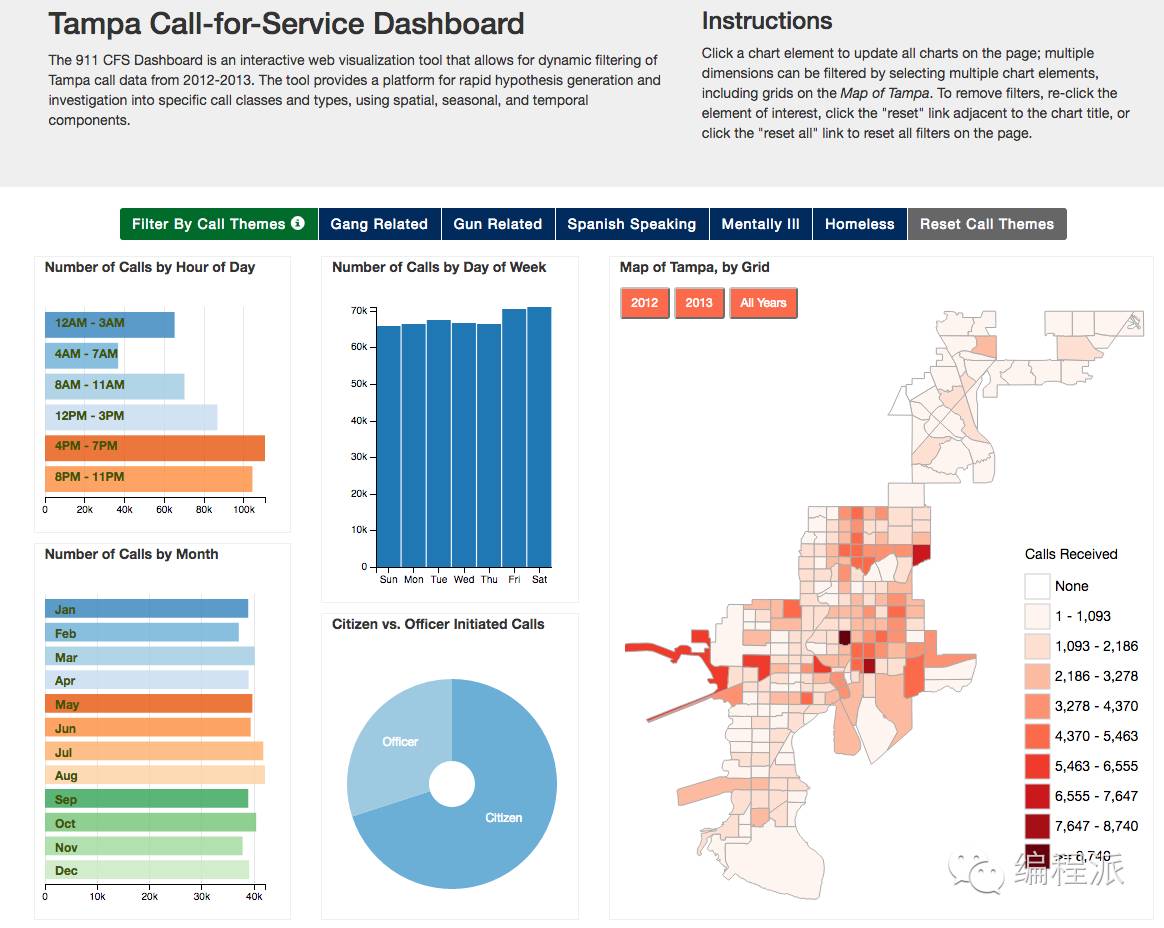
Tampa/dc.js 智能看板原型
我们面临的问题是要让这个智能看板适用于其他城市。Tampa市警局的看板是纯前端实现,没有后台服务器。所有的数据在一个 CSV 文件中,运行时所有数据会读进浏览器的内存当中。这种方式显然不适用于大型数据,也很难进行设置和升级。
我决定用 Django 和 D3 来创建新的看板。同时,我选取了一些用起来顺手工具。它们包括:
Django REST Framework
django-url-filter
NVD3 & D3
Ractive.js
Leaflet
架构设计
和其他项目一样,最终的架构和开始时的很不一样。通常对我来说更简单的做法是先探索性地写程序,同时搞清楚我需要什么,然后再从头开始写,或者将之前的代码整合到最终的架构中。一开始时,有几点需求是明确的:
我要多说两句,解释下最后一点。什么是响应式编程(reactive programming)?简单来说,就是当后台数据更新的时,UI 也同时更新。我希望由数据驱动应用。下文我还会就此进行说明。
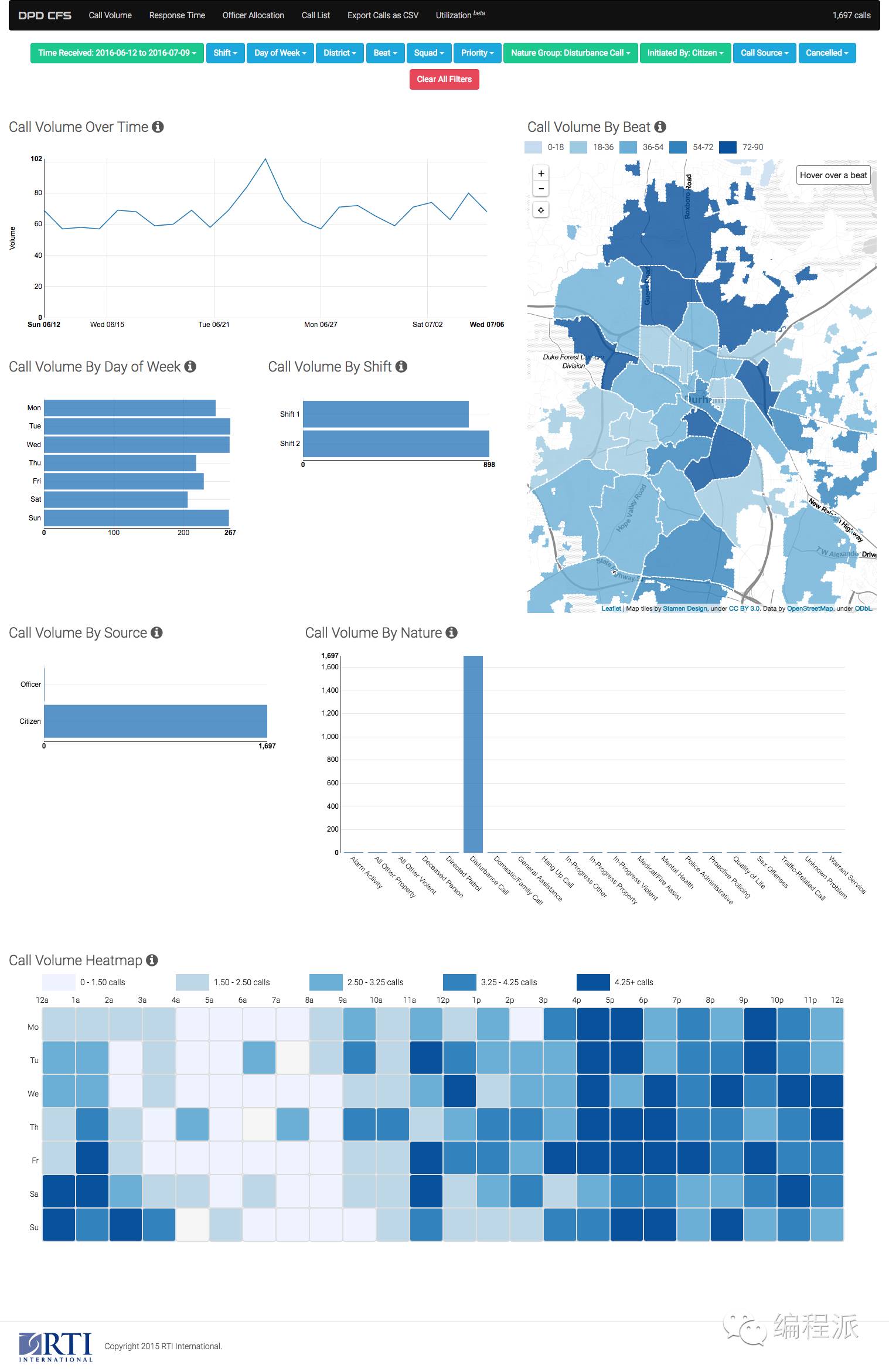
最终成果
Django
针对 Django,我对看板的每个页面设置了一个 JSON 端点(endpoint)。其中一个页面显示拨打 911的总量,另外一个显示电话接通时间,第三个以地图的方式显示所有电话的来源地,我们给每个页面都设置了一个端点:
url(r'^api/call_volume/$', views.APICallVolumeView.as_view()),
url(r'^api/response_time/$', views.APICallResponseTimeView.as_view()),
url(r'^api/call_map/$', views.APICallMapView.as_view()),
为了生成这些端点的内容,我给每一组图表创建了一个“摘要模型”(summary model)。这些摘要模型访问数据库,并为 API 的输出建立数据结构。这些模型均继承自一个基类,这样就能轻松创建新的模型。
class CallOverview:
def __init__(self, filters):
self.filter = CallFilterSet(data=filters,
queryset=Call.objects.all(),
strict_mode=StrictMode.fail)
self.qs = self.filter.filter()
self.bounds = self.qs.aggregate(min_time=Min('time_received'),
max_time=Max('time_received'))
def by_dow(self):
results = self.qs \
.annotate(id=F('dow_received'), name=F('dow_received')) \
.values("id", "name") \
.annotate(**self.annotations)
return self.merge_data(results, range(0, 7))
class CallVolumeOverview(CallOverview):
annotations = dict(volume=Count("id"))
class CallResponseTimeOverview(CallOverview):
annotations = dict(mean=Avg(Secs("officer_response_time")))
我在每一类中使用 annotatations 决定看板的页面上需要展示什么数据。
另外,我在摘要模型中自定义了对象关系映射(ORM)函数和集群(aggregations)。看下面这个例子:
def precision(self):
if self.span >= timedelta(days=365):
return 'month'
elif self.span >= timedelta(days=7):
return 'day'
else:
return 'hour'
def volume_by_date(self):
results = self.qs.annotate(date=DateTrunc('time_received',
precision=self.precision())) \
.values("date") \
.annotate(volume=Count("date")) \
.order_by("date")
return results
你会发现我在这里使用了DateTrunc。它使用了 PostgresSQL 中的一个同名函数,将根据你处理的数据量将时间数据截成月、天或者小时。
class DateTrunc(Func):
"""
Accepts a single timestamp field or expression and returns that timestamp
truncated to the specified *precision*. This is useful for investigating
time series.
The *precision* named parameter can take:
* microseconds
* milliseconds
* second
* minute
* hour
* day
* week
* month
* quarter
* year
* decade
* century
* millennium
Usage example::
checkin = Checkin.objects.
annotate(day=DateTrunc('logged_at', 'day'),
hour=DateTrunc('logged_at', 'hour')).
get(pk=1)
assert checkin.logged_at == datetime(2015, 11, 1, 10, 45, 0)
assert checkin.day == datetime(2015, 11, 1, 0, 0, 0)
assert checkin.hour == datetime(2015, 11, 1, 10, 0, 0)
"""
function = "DATE_TRUNC"
template = "%(function)s('%(precision)s', %(expressions)s)"
def __init__(self, expression, precision, **extra):
super().__init__(expression, precision=precision, **extra)
对这么一小段代码而言,注释好像有点太多了。不过很高兴能看到拓展 Django 的对象关系映射是这么简单。
我还自定义了集群,Percentile:
class CallResponseTimeOverview(CallOverview):
annotations = dict(mean=Avg(Secs("officer_response_time")))
default = dict(mean=0)
def officer_response_time(self):
results = self.qs.filter(
officer_response_time__gt=timedelta(0)).aggregate(
avg=Avg(Secs('officer_response_time')),
quartiles=Percentile(Secs('officer_response_time'),
[0.25, 0.5, 0.75],
output_field=ArrayField(DurationField)),
max=Max(Secs('officer_response_time')))
每一个摘要模型都用方法 to_dic 生成输出:
def to_dict(self):
return {
'filter': self.filter.data,
'bounds': self.bounds,
'precision': self.precision(),
'count': self.count(),
'volume_by_date': self.volume_by_date(),
'volume_by_source': self.volume_by_source(),
'volume_by_district': self.by_field('district'),
'volume_by_beat': self.by_field('beat'),
'volume_by_nature': self.by_field('nature'),
'volume_by_nature_group': self.by_nature_group(),
'volume_by_dow': self.by_dow(),
'volume_by_shift': self.by_shift(),
'heatmap': self.day_hour_heatmap(),
'beat_ids': self.beat_ids(),
'district_ids': self.district_ids(),
}
这些摘要模型由一系列过滤器驱动。这里,这些过滤器被指定为调用 API 时的 GET 实参。Django 主要有两个包协助完成过滤工作,django-filter 和 django-url-filter。django-url-filter 不常见也很难用。我之所以用它,是因为它更容易被修改,这正是我需要的。对于类似的项目,无论哪一个应该都很好用。
我第一个要修改的就是让查询方法被能用于过滤器。django-url-filter 可以将GET实参,如district=7&nature=10,作为形参传递给模型类 .filter方法。修改后,任何指向查询集(queryset)的 GET 实参将调用那个方法,于是 shift=1&district=7 (.shift 是用于查询的方法)将最终调用 Call.objects.filter(district_id=7).shift(1)。
下面一段代码能更简单,也能实现同样的功能:
def filter(self):
include = {self.prepare_spec(i): self.prepare_value(i) for i in
self.includes}
qs = self.queryset
for k, v in include.items():
try:
qs = getattr(qs, k)(v)
except AttributeError:
qs = qs.filter(**{k: v})
另一个我需要的修改是从数据结构创建过滤器,而不是按类创建。为了防止代码重复,我以 JSON 数据结构的方式将过滤器提供给前台,这样我就能用它控制智能看板。请看如下所示数据结构。就像大多数其他按需变化的事物一样,代码显得很杂乱,但应该是不言自明的。
[ {"name": "time_received", "type": "daterange"},
{"name": "shift", "type": "select", "method": True,
"lookups": ["exact"],
"options": [[0, "Shift 1"], [1, "Shift 2"]]},
{"name": "dow_received", "label": "Day of Week", "type": "select",
"options": [
[0, "Monday"], [1, "Tuesday"], [2, "Wednesday"], [3, "Thursday"],
[4, "Friday"], [5, "Saturday"], [6, "Sunday"]
]},
{"name": "district", "rel": "District"},
{"name": "beat", "rel": "Beat"},
{"name": "squad", "rel": "Squad", "method": True, "rel": "Squad",
"lookups": ["exact"]},
{"name": "priority", "rel": "Priority"},
{"name": "nature", "rel": "Nature"},
{"name": "nature__nature_group", "label": "Nature Group", "rel": "NatureGroup"},
{"name": "initiated_by", "type": "select", "method": True,
"lookups": ["exact"],
"options": [[0, "Officer"], [1, "Citizen"]]},
{"name": "call_source", "rel": "CallSource"},
{"name": "cancelled", "type": "boolean"}, ]
注意:将这些转变成Python对象的代码很拙劣。
最后,我利用 Django REST 框架生成真正的结点。回想一下,这些都能用 Django 独立实现。Django REST 框架是个很强大的平台,因此,我在其他地方也使用了它的序列化器(Serializer)。
class APICallResponseTimeView(APIView):
"""Powers response time dashboard."""
def get(self, request, format=None):
overview = CallResponseTimeOverview(request.GET)
return Response(overview.to_dict())
前台
由数据驱动
前文中,我提到过要让数据驱动应用。实操中,那意味着前台应用工作流如下:
用户通过点击图表上的过滤器选项栏选择不同的过滤器。
URL会被更新以反映现有的过滤器。
应用监视 URL 的变化。只要 URL 一变,它就向后台请求新数据。
当请求返回后,我们更新数据。
当数据更新,页面也就更新了。
我们将这种架构称为“响应式的”,但到底是什么意思?前台订阅事件(包括数据变更),然后响应事件后进行自我更新。最后两点就是响应式的由来。
前三项很有意思,而且,颠覆了你之前的期待。过滤器改变时,我便更新内部状态,而当状态更新后,URL 的哈希值也更新了。我订阅了「哈希值变化」事件,然后发出 Ajax 请求。根据下述应用流步骤,回想一下就看到了事件和响应。他们看起来同步,实际是异步的。
这种响应式范式,和你在著名的 React.js 中看到的是一样的。我们用的是 Ractive.js,这个库没那么有名,但是简单易懂。对于本项目中的智能看板,Ractive 的复杂程度刚好合适。在两个库中,你都需要创建组件。这些组件当中有数据,当数据变化触发的事件,并可以通过 UI 互动触发事件。
下面是一个简单的 Ractive 组件和相关的模板:
var ChartHeader = Ractive.extend({
template: require("../templates/chart_header.html"),
data: {
hidden: true
},
oninit: function() {
this.on("toggleExplanation", function() {
this.set("hidden", !this.get("hidden"));
});
}
});
<div>
<h3 class="chart-title">
{{ title }}
<i class="fa fa-info-circle clickable"
on-click="toggleExplanation">i>
h3>
{{ #unless hidden }}
<div class="explanation well">
{{ >content }}
div>
{{ /unless }}
div>
注意,这个模板并不止渲染一次。每当 Ractive 组件中的数据发生变化,就会重新计算该模板。
图表
D3 是目前为止最好的、功能最齐全的可视化库,但是说它是画图表的库并不准确。它是一个可用于生成图表和其他可视化形式的底层工具。如果你只需要一些图表,选择更高层级(high-level)工具会使你的工作变得轻松得多。你应该选择一些基于 D3 的工具——有 D3 作为基础,可以更容易地从生成可视化图形,如我们用到的热图(heatmap)。一些推荐工具如下:
我们用的是 NVD3。 这是个不错的选择:因为 NVD3 的默认样式很棒,图表种类也不少。
我们来看一个 NVD3 图表,以及如何更新。首先创建一个高级对象开始, HorizontalBarChart。
var volumeByDOWChart = new HorizontalBarChart({
dashboard: dashboard,
filter: "dow_received",
el: "#volume-by-dow",
ratio: 1.5,
fmt: d3.format(",d"),
x: function (d) {
return d.name;
},
y: function (d) {
return d.volume;
}
});
monitorChart(dashboard, "data.volume_by_dow", volumeByDOWChart.update);
HorizontalBarChart 可接受多种选项,其中有的设计表现形式,有的更加底层。dashboard是真正的 Ractive 智能看板插件,我们需要从中获取数据,然后触发一个在看板加载完后绘制图表的事件。 filter 是过滤器对象的关键,前端监控的鼠标点击时将更新图表。其他都是表现形式选项,指定图表渲染位置及如何格式化数据
和所有高级组件一样,HorizontalBarChart 有一个 .create方法,在实例化(instantiation)时被调用, 还有一个被 monitorChart调用的 .update 方法。monitorChart这个函数是用于监视看板中关键路径(“keypath”,是指一个树状目录型的数据)上的数据,当该数据的子集改变时调用一个函数。
function monitorChart (ractive, keypath, fn) {
ractive.observe(keypath, function (newData) {
if (!ractive.get("loading")) {
fn(newData);
}
});
}
制作一个新图表,只需要定义一个新图表对象,然后给它配置一个 monitorChart 即可。(回过头来看,monitorChart 这个名字起得很糟糕:它应该叫 monitorRactive。)
热图
高级库不是什么事都能干。在本项目中,我们想要一个基于天/小时的热图,用于查看拨打 911 的通讯量。我们需要用 D3 来实现这个。我们从 bl.ocks.org 的一个例子开始。
如果要一行一行代码地介绍,可能得领写一篇 D3 教程,但是我们有两个贡献反映了怎么将同样的形式复制到其他可视化图形中:
this.create = function () {
var bounds = this.getBounds(),
container = d3.select(this.el),
width = bounds.width,
height = bounds.height,
gridSize = Math.floor(width / this.ratio / 10);
container
.append("svg")
.attr("width", width)
.attr("height", height)
.attr("viewBox", "0 0 " + width + " " + height)
.append("g")
.attr("transform", "translate(" + margin.left + "," + margin.top + ")");
this.drawLabels();
d3.select(window).on("resize", function () {
self.resize();
});
this.drawn = true;
};
this.update = function (data) {
self.ensureDrawn().then(function () {
self._update(data);
});
};
我们用一个方法去建立可视化,然后当 Ractive 组件中正确的子集数据变化时调用一个 .update方法。我们必须确保这个组件被完全绘制,因为Ractive组件中的数据会随着页面加载立即变化。
经验总结
正如其他软件工程,回看之前的过程我会以不同的方式去做很多事情。在写这篇文章的时候,我发现了很多可以重写的代码。我还想尝试其他不同的库。总之,尽管如此,我还是对该项目很满意,特别是它的架构。
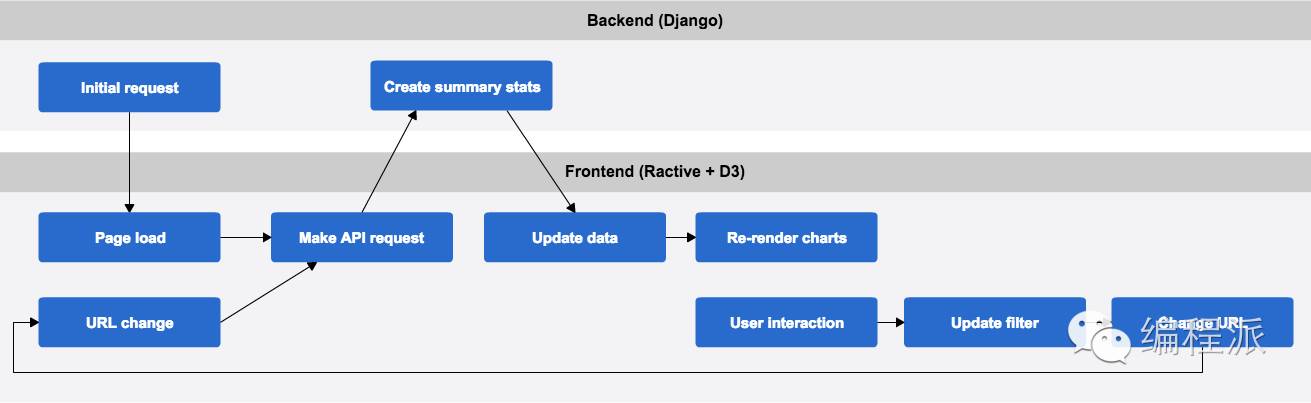
这个架构的优势在于它的具有单向流动性以及可标记状态。数据处理都交由 PostgreSQL 完成,而 Django 则负责协调看板和数据库的通讯。










