本文由新浪微博架构师陈飞撰写,因见解深刻,故在此转载
现在越来越多的企业开始全面拥抱云计算,开始关注云原生技术。从管理物理数据中心到使用云主机,我们不用再关心基础运维。从云主机到 Kubernetes容器,我们不用再关心机器的管理。云上抽象层级越高,就越少人需要关心底层问题,企业就能够节省大量的人力成本与资源投入。云原生技术就是更高一层的抽象, CNCF对云原生技术的定义是:
有利利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展应用。通过容器器、 服务网格、微服务、不不可变基础设施和声明式API等技术,构建容错性好、易易于管理和便于观察的松耦合系统。
例如FaaS架构,开发者可以完全不用考虑服务器,构建并运行应用程序和服务。还有面向开源架构的的云原生技术,与提供 MySQL, Redis 云服务类似,提供基于Spring Cloud、Dubbo、HSF 等开源微服务架构的应用管理服务,开发者无需考虑部署、监控、运维的问题。
微博也一直在致力于推动基础设施云原生化,我们围绕Kubernetes构建面向容器器的云原生基础设施,形成了了物理数据中心加多个公有云的混合云 Kubernetes平台,提供秒级伸缩能力。构建开箱即用的CI/CD体系,依托云原生伸缩能力,保证大量的Job稳定运行,让开发人员摆脱代码发布泥沼。接下介绍这几方面的实践经验。
物理数据中心Kubernetes化
面向单机器的基础设施架构已经无法发挥云的最大优势。把容器按照服务颗粒度进行管理,每个服务对应一组虚拟机,虽然基础运维通过 IaaS 层抽象得到了极大简化,但是业务的运维成本依然很高,业务SRE需要维护复杂的设备配置脚本,管理不同服务设备配置的差异性,需要7*24小时对故障设备进行干预。而且资源利用率无法最大化,服务池是按设备划分,一个新设备添加到服务池后只能被这个服务使用,它的冗余的计算能力并不能为其他服务使用。另外不同业务容器运行在不同的机器上,容器网络架构更关注性能而非隔离性,通常会采用Host模式,这也提高了服务混合部署的运维成本。
基础设施只有形成集群,才能最大程度发挥容器的良好隔离、资源分配与编排管理的优势。目前Kubernetes已经容器编排系统的事实标准,提供面向应用的容器集群部署和管理系统,消除物理(虚拟)机,网络和存储基础设施的负担。同时CNCF推出一致性认证,推动各公有云厂商提供标准的 Kubernetes服务,这就确保通过Kubernetes部署的应用在不不同云厂商之间具有可迁移性,避免被厂商锁定。
之前提到微博的容器会独占物理机的网络协议栈,虽然能够做到网络效率的最大化,但是会导致多容器部署时出现端口冲突,无法满足Kubernetes动态编排的需求。为了了解决端口冲突问题,我们首先测试了了vxlan网络架构,因为其数据平面需要进行封装、解封操作,网络性能损耗超过5%,并不不满足微博后端服务对网络性能的要求。最后我们评估可行的网络方案有两种 MacVlan和Calico BGP。
其中 MacVlan 成熟稳定,通过机房上联交换机改为Vlan Trunk模式,在物理机上创建MacVlan网卡子接口,通过CNI插件将虚拟网卡插入Pause容器中,实现容器网络与物理网络打通。容器的网络通信直接通过MacVlan物理子接口,发出的报文在网卡上打VlanTag,数据平面基本没有性能损耗。控制平面因需要对所有上联交换机进行Vlan Trunk改造,工作量量较大,所以这个方案仅针对高配物理机所在网络进行了改造。
Calico BGP是可以同时实现数据平面0损耗与控制平面自动化的容器网络解决方案。与MacVlan实现的扁平二层网络不同,Calico在每个节点上部署 BGP Client与Reflector实现了一个扁平的三层网络,每个节点发布的路由状态由 Felix 维护。不过由于Felix采用iptables实现路路由ACLs功能,对性能存在一定影响。因为物理数据中心不面向外部用户开放,所以ACLs功能对微博是可以去除的,我们对 Calico 进行了优化,去除iptables依赖。
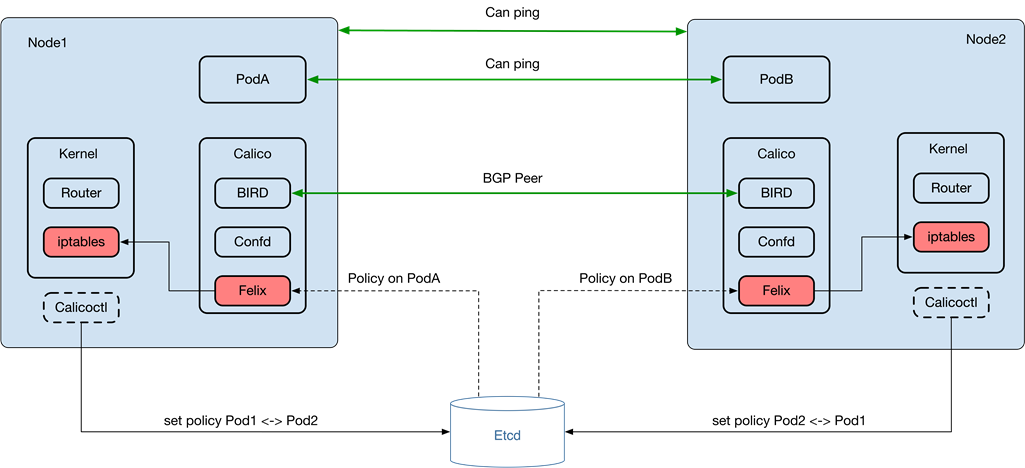
微博也主动回馈Kubernetes社区,也包括为Kubernetes代码库做贡献,例例如修复多租户下网络隔离TC资源泄露问题。
之前的运维是面向物理机的,所以物理机上存在很多运维工具,如日志推送、域名解析、时钟同步、定时任务等。业务通过Kubernetes编排后,以上的功能都需要进行容器化改造。例如在容器中使用systemd会涉及到提权问题,在实践过程中发现用systemd如果权限控制不当会造成容器器被Kill的情况。所以我们单独开发了兼容linux crontab语法的定时任务工具gorun,把这个工具集成在了了运维容器里面。
因为业务容器会产生大量日志,出于I/O性能考虑,同时为了方便快速定位,日志会存储于本地PVC中,支持配额管理,避免一个容器把磁盘写满。运维基础设施容器通过监听文件,对老旧日志进行压缩清理,性能Profile日志会在本地进行统计计算后通过UDP协议推送到Graphite或Prometheus。对于关键日志,会通过Flume推送到Kafka集群,而且支持失败重传,保证日志的一致性。
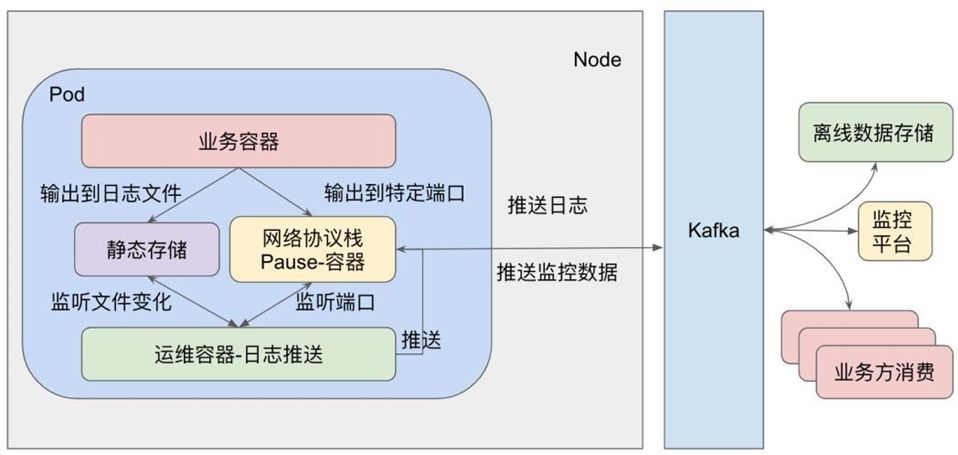
通过对运维容器化后,所有业务Pod都具备相同的运维能力,形成标准化的监控报警、运维决策、流量切换、服务降级,异常封杀、日志查询的服务保障体系,服务可运维性大幅度提升。
容器编排
Kubernetes的Deployment支持Pod自我修复,滚动升级和回滚,扩容和缩容,这些特性都是云原生基础设施必备的。但是Kubernetes设计原则中对集群的管理尤其是服务升级过程中保持“无损”升级,对Deployment进行行滚动升级,会创建新Pod替换老Pod,以保证Deployment中Pod的副本数量。原有里面的IP地址和滚动升级之前的IP地址是不会相同的。而如果集群够大,一次滚动发布就会导致负载均衡变更(集群副本数/滚动发布步长)次。对于微博服务来说,频繁变更会导致这个负载均衡管辖下的后端实例的接口不不稳定。
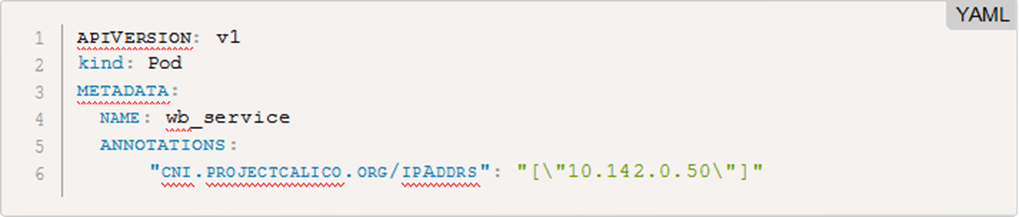
微博实现了常备Pod的In-place Rolling Updates功能,根据业务冗余度及业务实际需要来调整上线的步长,上线过程中保持容器的IP不变,减少在上线过程中业务的抖动。因为业务的启动需要一定时间,不能按照容器启停来做步长控制,我们利用Kubernetes容器生命周期管理的liveness/readiness probe 实现容器提供服务的状态,避免了上线过程中容器大面积重启的问题。同时优化了了Kubernetes的postStar的原生实现,因为原生里面只调用一次,不管成功与否都会杀掉容器,改成不成功会按照指定的次数或时间进行重试。IP的静态分配使用Calico CNI实现:
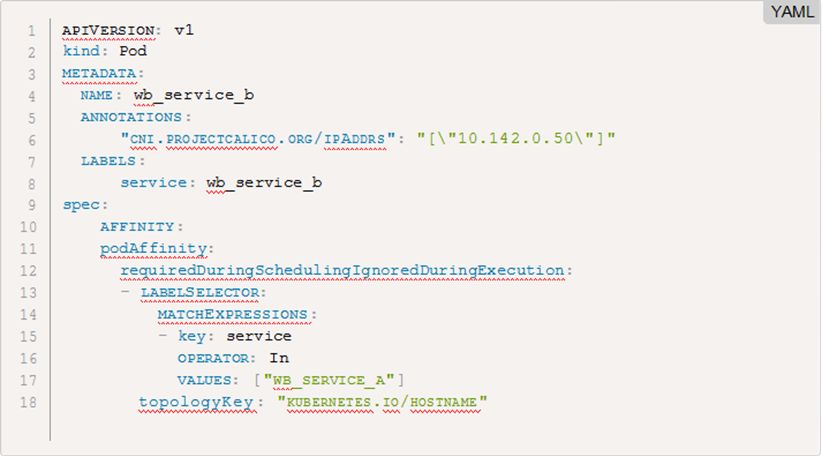
Kubernetes的编排策略相对灵活,分为三个阶段,初筛阶段用于筛选出符合基本要求的物理机节点,优选阶段用于得到在初筛的节点里面根据策略略来完成选择最优节点。在优选完毕之后,还有一个绑定过程,用于把Pod和物理机进行绑定,锁定机器上的资源。这三步完成之后,位于节点上的 kubelet才开始创建Pod。在实际情况中,把物理机上的容器迁移到 Kubernetes,需要保持容器的部署结构尽量一致,例如一个服务池中每台物理机上分配部署了wb_service_a和wb_service_b两个容器,可以通过 podAffinity来完成服务混部的编排:
一些比较复杂的,运维复杂的集群,通过Kubernetes Operator进行容器编排。Operator是由CoreOS 开发的,用来扩展Kubernetes API,特定的应用程序控制器,它用来创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统。Operator基于Kubernetes的资源和控制器概念之上构建,但同时又包含了了应用程序特定的领域知识。Operator 可以将运维人员对软件操作的知识给代码化,同时利用Kubernetes强大的抽象来管理大规模的软件应用。例如CacheService的运维是比较复杂的,需要资源编排,数据同步,HA结构编排,备份与恢复,故障恢复等等。通过实现 CacheService Operator可以让开发通过声明式的Yaml文件即可创建、配置、管理复杂的Cache集群。CacheService Operator支持:
1. 创建/销毁:通过Yaml声明CacheService规格,即可通过Kubernetes一键部署,删除
2. 伸缩:可以修改Yaml中声明的副本数量,Operator实现扩容,配置主从结构,挂载域名等操作
3. 备份:Operator根据Yaml中声明的备份机制,实现自动的备份功能,例例如定期备份,错峰备份等
4. 升级:实现不停机版本升级,并支持回滚
5. 故障恢复:单机故障时,自动HA切换,同时恢复副本数量,并自动恢复主从结构





