tf-idf,英语的全称叫做 term frequency-inverse document frequency,它是文本挖掘领域的基本技术之一。tf-idf 是一种统计的方法,用来评估一个词语在一份语料库中对于其中一份文件的重要程度。词语的重要性会随着它在该文件中出现的次数而增加,但是也会同时随着它在语料库中其他文件出现的次数而减少。
假设一份语料集合是 D,那么语料集中文件的个数就是 N=|D|,第 j 份文件用  来表示,其中
来表示,其中  。同时假设在语料库中出现的所有词语的集合是
。同时假设在语料库中出现的所有词语的集合是  。
。
(一)词频的定义以及基本性质
从直觉上来说,如果某一个词语在一份文件中重复出现了多次,那么这个词语在这份文件中的重要性就会显著增加。在给定的一份文件 里面,词频(term frequency)指的是语料库中的一个词语  在该文件中出现的频率。词频通常定义为:
在该文件中出现的频率。词频通常定义为:
 = \frac{n_{i,j}}{\sum_{k}n_{k,j}},")
其中, 指的是词语 在文件 中的出现次数,而分母
指的是词语 在文件 中的出现次数,而分母  则是文件 中所有的词语的出现次数之和。
则是文件 中所有的词语的出现次数之和。
备注:如果某个词语在该文件中没有出现过,那么该词语在这个文件中的词频就是零。
词频除了以上的基本定义之外,还有其他的各种形式:
二值表示: = \mathcal{I}(t_{i}\in d_{j})") ,其中
,其中  是指示函数,
是指示函数,
计数表示: = n_{i,j},")
概率表示: = n_{i,j}/\sum_{k}n_{k,j},")
对数表示: = 1") +
+ ,")
double normalization K表示: = K") +
+ n_{i,j}/\max_{k}n_{k,j}") ,其中
,其中 ") ,或者 K 直接取值为 0.5 即可。
,或者 K 直接取值为 0.5 即可。
(二)逆向文件频率的定义以及基本性质
除了词频之外,还有逆向文件频率(inverse document frequency)这个概念,它是用来描述一个词语普遍性的指标。通常来说,如果某个词语在绝大多数甚至所有的文件中都出现过,例如一些常见的停用词,那么该词语的重要性就要降低,因为它在语料集中十分普遍。因此,逆向文件频率的定义通常就是:
 = \log(\frac{|D|}{|\{d\in D: t_{i}\in d\}|}),")
其中,N=|D| 是语料库中文件的总数, 表示的是在语料库中包含词语 的文件个数,也就是说
表示的是在语料库中包含词语 的文件个数,也就是说  的文件个数。
的文件个数。
备注:如果该词语不在语料库中,会导致分母是零,因此在一般情况下会使用  + 。
+ 。
逆向文件频率除了以上的基本定义之外,还有以下几种常见的计算方法:假设  ,
,
唯一性表示:1
逆向文件频率:=-\log(\frac{n_{i}}{|D|})=-log(p(t_{i}|d)),")
光滑的逆向文件频率: +
+ ,")
概率化逆向文件频率:.")
(三)TF-IDF 的定义和基本性质
那么,为了描述词语 在文件 中的重要性,tf-idf 的定义就可以写成:
=tf(t_{i},d_{j})\times idf(t_{i},D).")
通常来说,tf-idf 倾向于过滤掉常见的词语,而保留重要的词语。
下面:我们来通过一个案例来看 tf-idf 是如何进行计算的。
假设语料集中有两份文档,分别是 Document 1 和 Document 2,出现的词语个数如下表示:
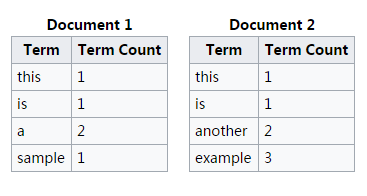
通过这幅图可以直接计算出 “this” 这个词语在各个文件中的重要性程度:
 ,
, ,
, ,
,
因此可以得到  。原因是 “this” 这个词语在两个文件中都出现了,是一个常见的词语。
。原因是 “this” 这个词语在两个文件中都出现了,是一个常见的词语。
 ,
, ,
,  ,
,
因此可以得到  ,
, 。原因是 “example” 这个词语在第一份文件中没有出现,第二份文件中出现了。
。原因是 “example” 这个词语在第一份文件中没有出现,第二份文件中出现了。
(四)向量空间模型
空间向量模型是把一个文件表示成向量的代数模型,文件与文件之间的相似度使用向量之间的角度来进行比较。
假设语料库中所有词语的个数是 T,第 j 个文件是 ,查询是 q,它们用向量表示就是:
\in \mathbb{R}^{T}")
\in \mathbb{R}^{T}")
每个维度对应了一个相应的词语。如果该词语没有出现在该文件中,那么向量中所对应的位置就是零。在这里,比较经典的一种做法就是选择 tf-idf 权重,也就是说第 j 个文件的向量是按照如下规则选择的,, w_{i,q}=tfidf(t_{i},q), 1\leq i\leq T") 。
。
那么文件 和查询 q 之间的相似度就可以定义为:
=\frac{d_{j}\cdot q}{||d_{j}||\cdot||q||}.")
其中分子指的是两个向量的内积,分母指的是两个向量的欧几里得范数的乘积。
备注:在词组计数模型(Term Count Model)中,也可以简单的考虑词语出现的次数即可:") 。
。
欢迎大家关注公众账号数学人生
(长按图片,识别二维码即可添加关注)










