
科研经验 | 文献 | 实验 | 工具 | SCI写作 | 国自然

作者:Angelslive
转载请注明:解螺旋·临床医生科研成长平台
这次文献精读介绍的文章是与全基因组关联分析和电子病历相关的一篇文章,涉及到生物信息学的一种方法。该文章于去年底发表在Nature Genetics上,介绍了如何利用电子病历研究发现和高血压相关的新位点,从而寻找到一些和高血压相关的疾病危险因素。

回复170524可下载文献,一月有效
首先梳理一下和该文章相关的知识点
全基因组关联分析(Genome Wild Association Study,GWAS):是用于推测基因位点与表型间有无关联及关联强度大小的一种分析方法。
GWAS具体需要什么数据和怎样操作呢?首先,需要理解下面这个对应式:y~gene+covariance
y是表型值,即文章中血压值数据,如收缩压、舒张压等,是选定所要研究数据的表型,它可以是连续性变量,也可以是分类型变量;而模型里的x即为我们需要研究的基因值,在全基因组关联分析中使用的基因型是单核苷酸多态性(SNP),对于一个基因位点的SNP有三个基因型AA,AT,TT(可参考上一讲的概念),则可将其转化为如0,1,2等的x值,方便研究。
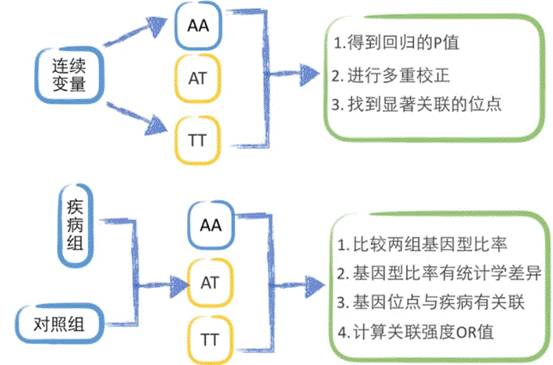
而在研究基因和疾病表型的关系时 ,加入covariance可以排除影响表型的一些环境因素。当基因和环境对表型同时有作用时,可以规避环境的因素,避免出现假阳性结果。具体添加方法会在文章解读的细节中提到。
其实这篇文章的思路较为浅显,能发表在NG上的主要原因,是引入了电子病历这样一个比较新的概念。关于这个概念在GWAS中的意义还要从GWAS方法的特点说起。
GWAS作为一种传统的疾病分析方法,被广泛的运用于各种疾病分析中,从而找出许多的疾病治病位点。
然而,这种方法也有一些不足。比如研究某种疾病时,需要很大的样本量,一项研究往往需要成千上万人才能准确找出一些和疾病相关位点;其次是数据不准确,例如06年以前研究高血压通常采用的是血压范围,这种方法可能不准确,以致于寻找到的位点也会相应不太准确;还有就是是信息的缺失,一般存在两种情况,一是芯片质量不好,二是纸质版病历中资料的缺失,这些都会使样本量不能满足分析需求。
因此,这篇文章通过电子病历对信息进行横向和纵向的整合,不仅包含了一个样本在某一节点的信息,而且包含每个样本从发生起到现在的所有疾病进展信息。不仅仅增加了样本量,更提高了分析的准确性和有效性。电子病历的另一个好处是能够提供病人的一些生活信息,比如是否吸烟、饮酒等,这些因素都可以加入全基因组分析的covariance中,规避一些假阳性的可能。
了解了电子病历的普遍性优势后,回到本文所研究的高血压领域,目前在高血压位点分析方面,仅有85个SNP位点被发现和血压表型相关,相比于其他心血管表型,高血压的遗传解释度过低,还有很多新位点未能发现。
那么,有什么办法能够发现新位点呢?首先,可以增大样本量,但这是一项很大的工程,需要资金和各方面的支持。其次,我们可以提高测量的准确度,例如,06年前测量高血压用的是范围值,其实这样在分析中不是很准确,而06年以后使用的准确值,就提高了血压测量的准确性。
除此之外,还可以增加基因位点信息,这种方法我们一般称之为imputation。比如,有两个芯片A,B,A芯片数据有20个SNP,而B有60个SNP,我们就可以将B作为reference,把A中20个SNP扩增为60个,也就是基因信息的填补。
针对以上三个策略,本研究可以说体现出了电子病历用于高血压研究的优势,首先极大扩充样本量,数据集中参加人有11万人,其中包括100多万个收缩压和舒张压数值;同时可以获得长期的临床监测,使研究更加准确;还可以提供更全面的生活、环境等信息,便于后期covariance的运用,提高准确度。
全文共有4个Figure,大概思路如下。
Figure1是整个疾病分析流程图。
Figure2-4为数据解构部分:
Figure2分析不同人种有没有显著的血压差异,以便在具有差异时control不同因素
Figure3通过GWAS分析新找到的位点在不同组别间是否有效应差异,探究了不同数据集中SNP解释度的差异表现
Figure4是血压差异的组织特异性分析结果
Figure1分为a,b两图,其中a图是本文疾病分析流程图,包括关联分析和荟萃分析(meta analysis),荟萃分析是一种将不同研究结果binding到一起的扩大样本量的方法。从数据的具体筛选过程中可以看出,本文样本量大、数据多,因此可以随意筛选出质量高的病例,这也体现出电子病历的优势,有钱任性啊!

b图紫色表示三个研究集合(基因型数据),对三个集合做了一个imputation,即根据参考数列进行基因型填充;蓝色和灰色分别表示为样本基因型和表型数值;橘粉色和橙色为将不同来源结果(基因型数据和表型数据)binding到一起的全基因组关联分析和重复验证分析。
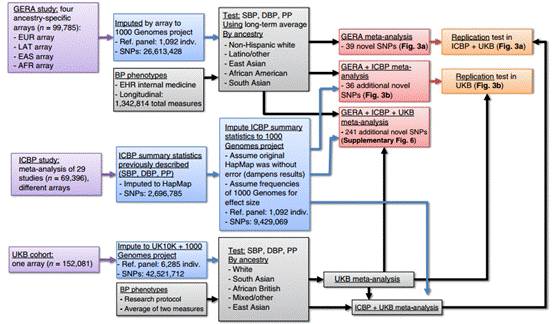
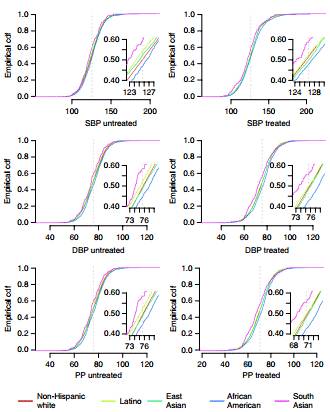
Figure2对疾病分析中是否需要control服药和人种因素进行了covariance,以完善整个模型。结果并没有显著差异,因此表明实验中不需要control是否服药和人种因素。
补充图中,横坐标表示位于基因组的物理位置,纵坐标表示线性回归分析得到的P值,该数值越小则表明SNP和疾病关联度越显著。该结果不仅重复出了前人发现的85个位点的研究结果,还发现了新位点,表明了电子病历的方法是非常有效的。
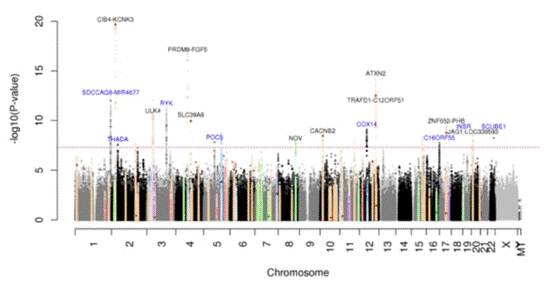
Figure3的数据解构进行了新位点在不同数据集、不同血压表型中的效应值比较。Bar的颜色代表荟萃分析中的不同P值。其中,红色表示极为显著,橙色为较为显著,蓝色不显著,黑色为完全不显著。可以看出,相较于舒张压来说,收缩压可能更容易受到基因影响。
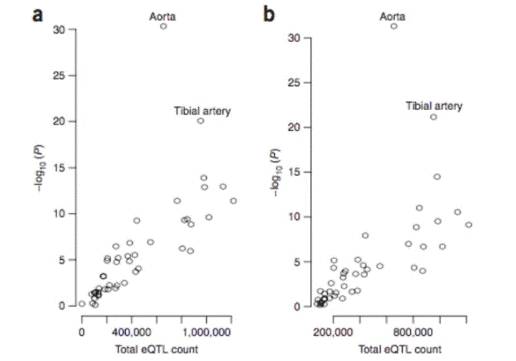
Figure4为51个组织的组织特异性分析。图中每一个点对应一个组织,在两种组织中发现,基因突变可能极为显著地影响血压表型。A用的是SNP位点,而B则将SNP前后位点进行扩充研究。研究结果发现,血压数值在主动脉和颈动脉组织中存在特异性,即表明高血压也是具有组织特异性的一种症状。
本文的套路,总结为一句话就是:如果想发新文章,就要找到质量高的数据。
总结起来,本文的不足之处是套路传统,没有太多创新性。但是亮点也非常显著,就是电子病历。其结果重复了前人的研究结果,证明了电子病历运用于病例分析数据的可靠性;同时也提供了扩充GWAS研究样本量的新思路。我们在以后的研究中,可将该模式运用于其他疾病表型的分析,说不定有很大的收获哟!
长按识别下方二维码添加文献菌为好友,直接提问和深入交流。












