作者:罗宾
罗宾,世界500强全球化IT项目中国区负责人,服务于快速消费品、零售行业十余年。某领先BI公司大中华区高级顾问,丰富的BI行业知识以及BI项目咨询、管理和实施经验。
博客专栏:
https://ask.hellobi.com/blog/luobin

这张完美的图,囤了好久了,今天拿出来,仔细研读一下,分享给大家。
先把全文整体浏览一遍……,主要是走这8步:
学好统计、数学和机器学习
学会编程
理解数据库
探索数据科学工作流
提升到大数据层面
成长、交流和学习
全身心投入工作
混社会(社区和论坛)
好了,先来热个身,什么是数据科学(家)?

2010的解读和2015的还不太一样,2010认为是“数学好,业务精,技术强”,也就是说:
理论基础要扎实——数学和统计学要掌握的好
丰富的行业知识——对所在的业务领域、行业知识要精通
技术牛人或大神——装的了机,调的通网,写的了代码,玩的转数据……
以上是修成正果的节奏,要是跑偏了呢,一般会这样:
数学不太好——很危险!没有严谨的方法论(理论依据),就有可能在瞎折腾;
业务不太熟——运用不到工业界(企业),就只会是个纸上谈兵的理论家;
技术不太强——没有现代IT技术的武装,就只会是个搞传统研究的老专家;
下面这张图,很好的解释了这些细节:
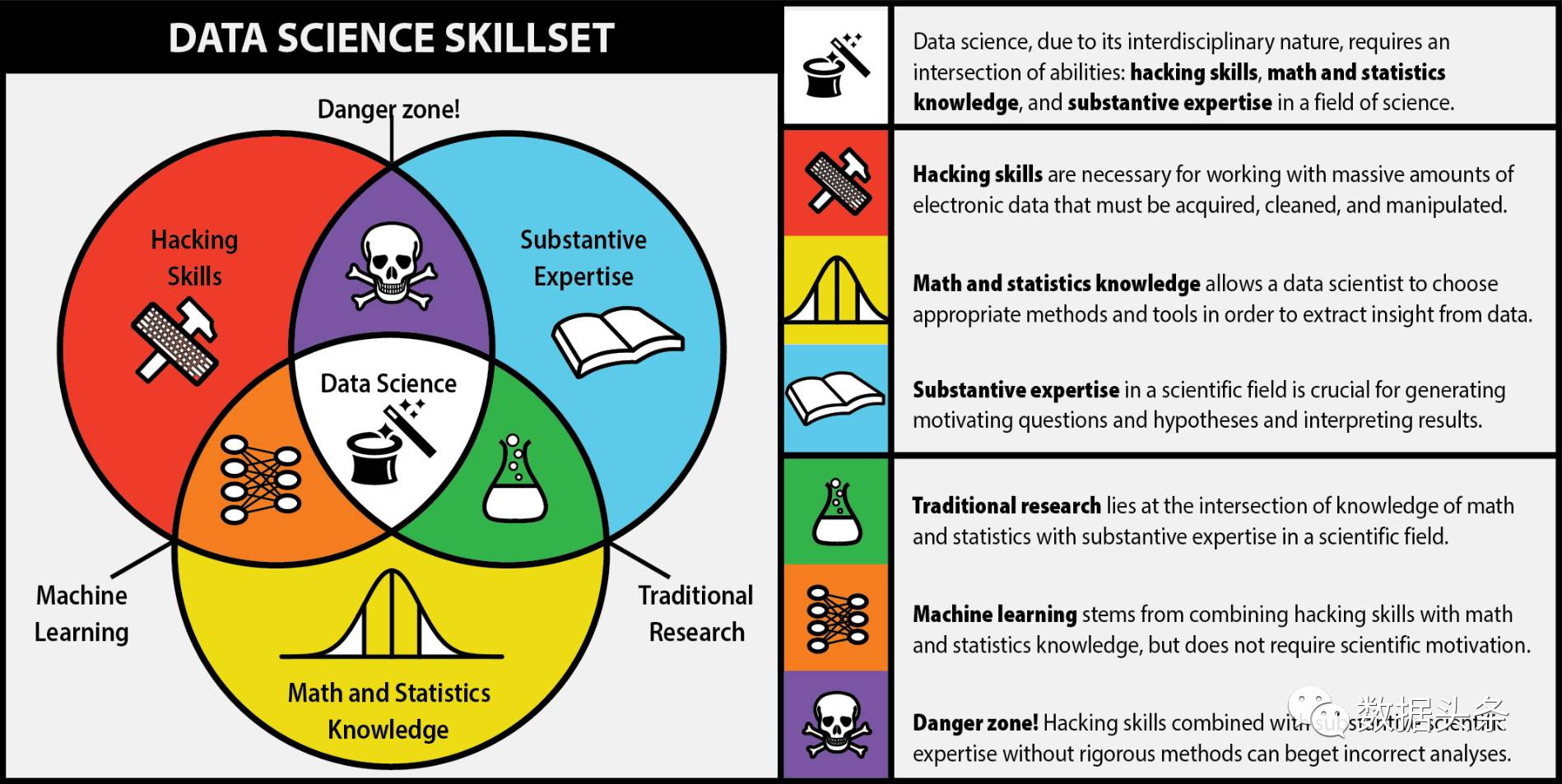
但是2015这张图,又是几个意思呢?
人工智能包含机器学习,机器学习又包含了深度学习;大数据领域跟三者都有交叉,但又是另外一个全新的领域。
数据挖掘(Data Mining),是AI人工智能和Big Data都会涉及到的领域,主要就是那些基础算法,预测、分类、聚类、关联等。
数据科学,就在此应运而生,跟AI和Big Data都有交叉,但不涉及深度学习。
太混乱了,一句话解释:数据科学(家)就是人工智能、机器学习和大数据领域的复合型学科(人才)
再来看看需要什么样的学历背景:
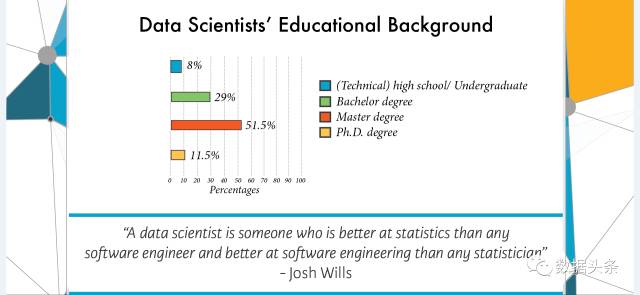
一句话概括:技校就行,本科不错,硕士最好,博士当然可以,但人不多(总人头就不多)
下面那句名言,说数据科学家基本就是这种人:你跟他谈技术,他和你谈业务;你要谈业务,他就搬理论……想不到,你是这样的数据科学家。
小结一下,数据科学家就是复合型人才,差不多智商的都可以上。但是,以我敏锐的洞察和经验,注意到这是DataCamp做的宣传图,它会把这事描述的相对容易,门槛低嘛大家都有兴趣来学,这样的图,其实也是软文的一种(老外的软文)。下图是DataCamp的首页,主要是提供在线的、收费的数据科学课程的
好,我们把书翻到第1页,先来看第1步——学好统计、数学和机器学习(走遍天下都不怕)

首先,关于数学,有一些非常好的资源可以利用:
可汗学院
官网是https://www.khanacademy.org
网易公开课(可汗学院)也有部分翻译过的课程
麻省理工学院MIT的OCW
https://ocw.mit.edu/index.htm
其次,关于统计学:
优达学城的统计学入门(Intro to Statistics)
https://cn.udacity.com/
OpenIntro的Statistics
https://www.openintro.org/
DataCamp自己也有几门课程
最后,关于机器学习
斯坦福在线的ML课程,应该就是大大牛Andrew Ng的课程
Coursera的practical machine learning
这里搜一下就有:https://www.coursera.org/
约翰霍普金斯大学的课程
DataCamp自己也有几门课程
好了,发散一下思路,现在好的课程,在网上已经是铺天盖地了,只要你有本事,想学什么都可以。所以,现在挤破头的学区房,10年以后可能会是个大笑话;当然,挤进名校,还有提升圈子、阶层的作用,这样看,又不好笑了……
翻到第2页,再来看第2步——学会编程
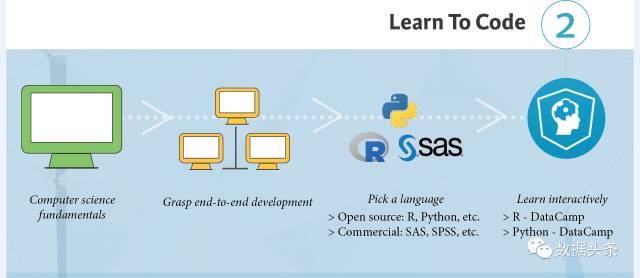
想起一个说法,说以后编程可能会是像英语一样的,每个人的最基础的技能了,所以,程序员可以先偷着乐一下。
首先你要具备一些计算机科学的基础知识
然后尝试一些基础性的开发工作
再选定一门好的(或你喜欢的)编程语言
开源的R和Python(当前最火)
商业工具:SAS, SPSS 等等
交互式的去学吧!就是学习、练习、交流、实践、思考,反复学习,刻意练习。(DataCamp刚才还很含蓄,现在憋不住要推自己的课程了……)
好,再来看第3步——理解数据库

既然要跟数据打交道,那么对数据存放和管理的地方——数据库的深刻理解,一定必不可少:
MySQL:经典的关系型数据库,开源,体积小,速度快,成本低;中小型网站或企业开发之必备;同Linux,Apache,PHP形成最高效、经典的开发环境LAMP
Oracle:领先的企业级数据库,高效率,功能强大,可移植性好,高可靠性,高吞吐量
Cassandra:高可用性和高可扩展性的NoSQL数据库(属于列式存储),支持大规模分布式数据存储和高并发数据访问
CouchDB:一个Erlang语言开发的Apache的顶级开源项目,是一个面向文档的NoSQL数据库
PostgreSQL:加州大学伯克利分校研发的对象关系型数据库管理系统(ORDBMS)
MongoDB:也是一个面向文档的NoSQL数据库,非关系数据库中最像关系数据库的,对数据结构要求不严格
需要对数据库加深理解的,可以移步至:
MongoDB University
https://university.mongodb.com/
斯坦福在线(又来了)
Introduction to Database
Datastax
https://www.datastax.com/
TutorialsPoint
http://www.tutorialspoint.com/
好,再来看第4步——探索数据科学工作流
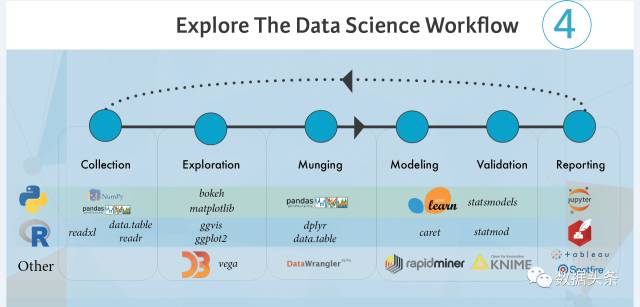
此处,对于数据科学家的日常,我们又分为6小步走:
数据收集
运用各种方法(复制、导出,爬虫等),将原始数据收集起来,存储到一个地方(文本文件,Excel,数据库等)。
数据探索
使用一些基本的数据可视化工具,对数据做一个初步探查,看看大致的状况和数据分布情况。
数据清理
对重复数据,错误数据进行处理;对数据格式、规范进行统一;对部分数据进行分拆或者合并。
数据建模
根据需要求解的问题,选用合适的数据模型进行建模,并输出数据分析的结果。
数据验证
选用合适的统计分析工具,对数据分析输出的结果进行验证,确认分析结果在合理的误差范围或精度要求之内。
制作报告
将数据分析的结果和由此得出的结论,结合业务实际,制作出合理的数据分析报告。
这里,需要了解几个通俗的说法:
程序——几行代码,完成一个输入到输出的函数,或者过程,我们叫程序。
程序包(或者库)——预先写好的,通用的,规范的一堆程序文件,可以在我们的程序里调用。
工具(开发环境,IDE,软件)——通常是图形化界面下的,可以进行程序开发的一整套工具(软件)。
那么,对于以上6个步骤,就可以简单的解释了:
数据收集
Python:可以调用Numpy和Pandas等科学计算的“库”来做
R语言:可以调用readxl, data.table等“库”来做
数据探索
Python:可以调用Bokeh或Matplotlib等数据可视化“库”来做
R语言:可以调用ggvis, ggplot2等“库”来做
其它:可以使用可视化软件vega来实现
数据清理
Python:可以调用Pandas等“库”来做
R语言:可以调用dplyr, data.table等“库”来做
其它:可以使用数据清理和转化软件Data Wrangler来实现
数据建模
Python:可以使用开源机器学习框架Scikit-learn来做
R语言:可以调用caret这个机器学习“包”来做
其它:可以使用数据挖掘工具rapidminer来实现
数据验证
Python:可以调用statsmodels库来做
R语言:可以调用statmod库来做
其它:可以使用开源数据挖掘软件KNIME来实现
制作报告
Python:可以使用Jupyter工具来实现
R语言:可以使用R Studio自带的R Markdown来实现
其它:可以使用商业化BI软件Tableau, Spotfire等来实现
不错,已经走完一半了,接下来,我们走第5步——提升到大数据层面
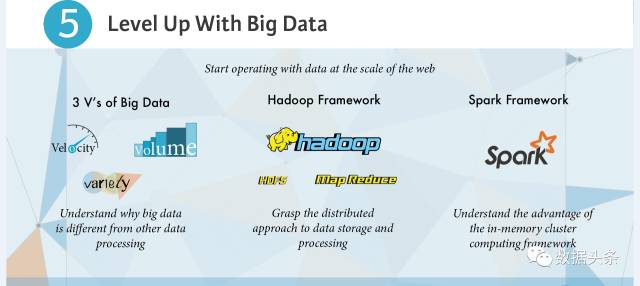
首先,我们来理解,所谓的“大数据”到底比“小数据”,大在哪里?
流行的说法有4V和3V之说,其中3个V是指:
Velocity——更快的数据产生速度。主要归因于进入新的数据时代(比如从PC时代-->互联网-->移动互联网-->物联网),数据产生速度的量级开始猛增
Volume——更大、更多的数据量。数据产生快了,量自然就多了
Variety——更多样的数据种类。除了以前的结构化数据,还有文本、文档;图片、图像;音频、视频;XML、HTML等等大量的非结构化数据
4V就是在此基础上增加了一个Value,数据的价值。
其次,我们来看看最经典的大数据框架——Hadoop,曾经这个以“黄色小象”为logo的hadoop,就几乎是大数据的代名词。简单理解hadoop,它就是一个分布式的大数据系统基础架构:
因为数据“大”了,一台服务器(单机)处理不过来了,所以需要团结一个个的服务器(集群),来协同处理;或者说,把一个大的数据任务,分解出来,处理完成,再合并起来。Hadoop就把这个分布式系统的框架,搭好了。
计算机的两个重要组成部分,处理器CPU负责计算,内存(硬盘)负责存储,所以,对应的,MapReduce就是Hadoop的分布式计算框架;HDFS就是Hadoop的分布式文件存储系统。
最后,关于Spark,业界其实一直流传着Hadoop是一个大坑的说法,实施起来并没有传说中那么好,(当然也造就了一大批hadoop填坑的工作岗位)。主要问题在于MapReduce,计算引擎这块,Spark算是第二代引擎,对大数据计算时的中间输出结果,使用内存计算进行了优化,大大提升了数据处理速度(号称提升了100倍),所以可用于大规模的实时数据流处理和交互式分析。
接下来,我们再来看第6步——成长、交流和学习
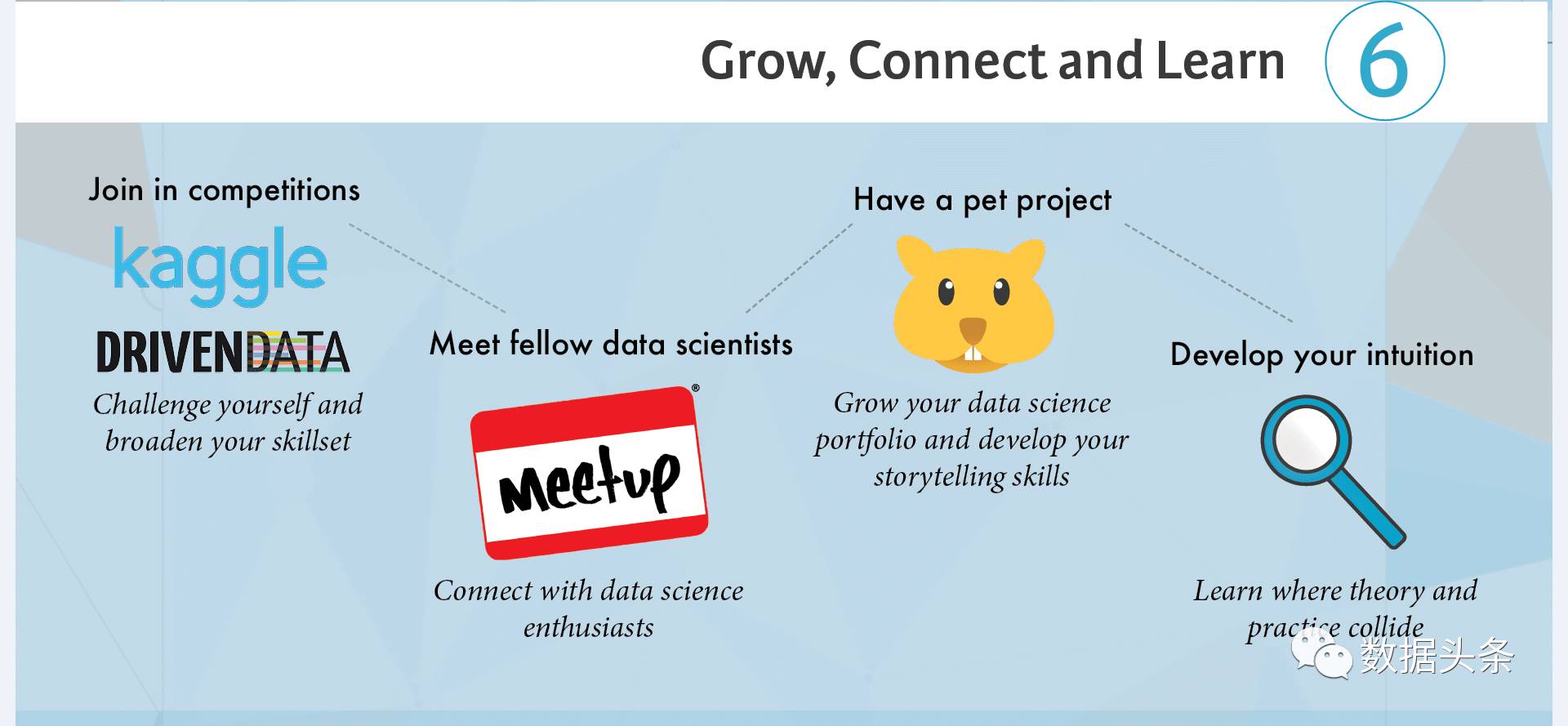
学了这么多,也该出来练练手了:
参加一些数据挖掘或算法挑战竞赛
最著名的是Kaggle,国内有阿里的天池。将所学的技能,去解决工业界(企业)遇到的实际问题,并获取一定的奖金,何乐而不为?
结交各路豪杰(现在叫大牛/大神)
一个人学容易闭门造车,或者一个问题卡死在哪里,无从下手。多认识一些志同道合的朋友,可以增长见识,开拓思路,学习进度也可以大大提升。
参与一些实际项目(积累项目经验)
跟几个人创建一个合作小团队,实打实的去完成一个实际的小项目,会在很大程度上提升你的个人资历和背景,实践出真知。
提升你的直觉(心理表征)
反复的学习、演练、实践、再学习,便可以让个人知识、技能和经验不断螺旋式上升,慢慢的,以前棘手的问题,已经可以下意识的给出结论或者解决办法,就像可以完全依靠直觉来处理一样,其实,这就是刻意练习所强化出来的心理表征的作用。
下面看第7步——全身心投入工作

演练完了,就找一份全职的工作吧,可以从实习生做起,一路打怪升级,做到真正的数据科学家。你的实践经验也会在这个过程中,继续得到更大的提升。
另外,类似Kaggle这样的平台,也提供数据科学家的工作招聘,你可以把竞赛的成绩直接显示到你的简历里。能力如果足够出色,薪水从来不是问题。
居然要写完了……来看最后一步,天龙8步——混社会(社区和论坛)
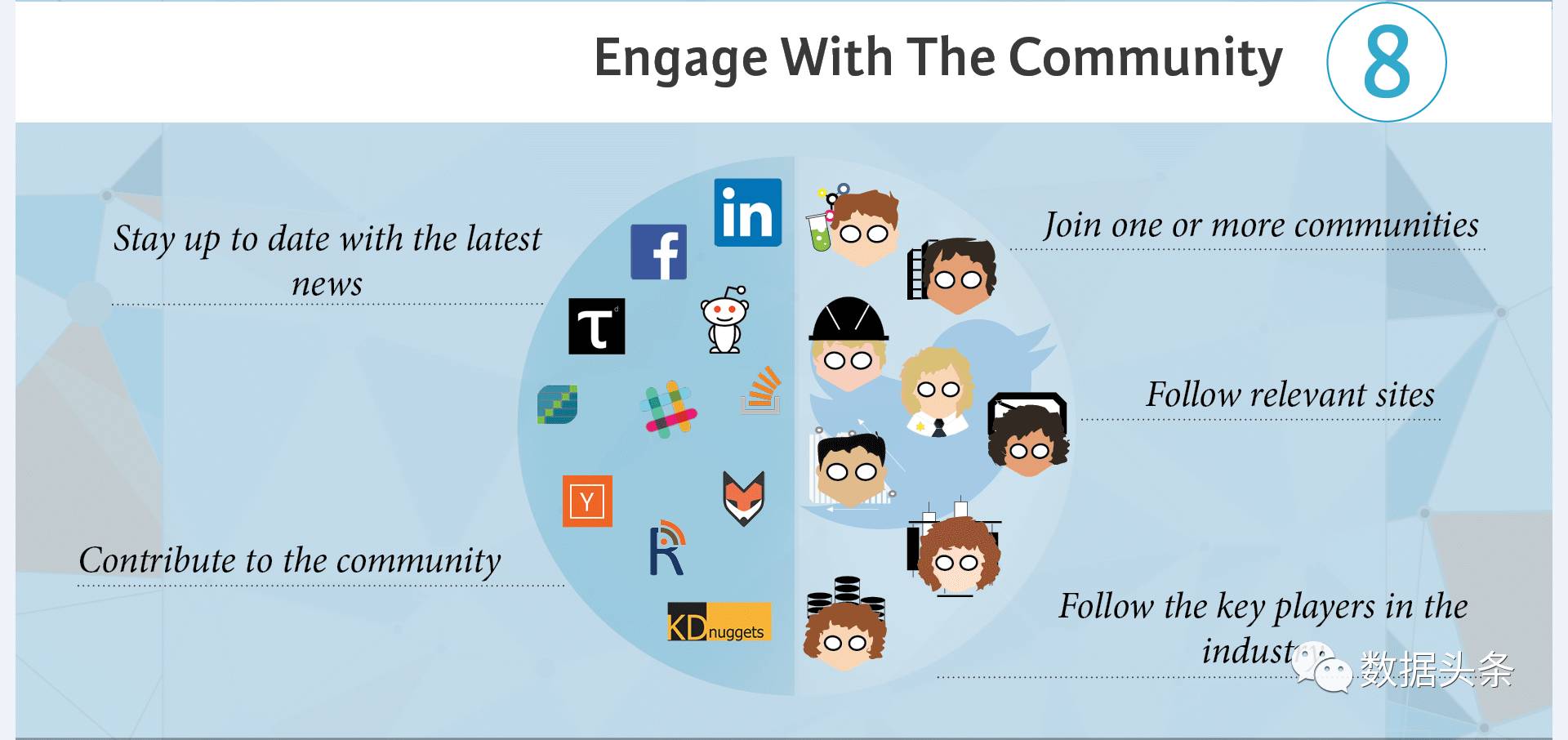
工作也有了,收入也杠杠的,那么……好山好水好无聊啊,总得找点事情做做,那就去混社会吧(当然是数据科学家的社会),有好多种操作方式:
时刻关注行业或领域最新资讯,保证不落伍,谈资满满。
不能一味索取,也要贡献一些产出,知识经验分享,代码共享,思路分享……不一而足。
可以加入一些社区,微信群,线上线下均可,总要找到组织嘛,个人总要有些群体归属感(我又突然想起那句“适当离群,才能保证足够优秀”的话……)。
当你还是一个小白时,记得粉大牛/大神,虚心请教,背后痛下苦功,争取早日成为另一个大牛;成为大牛后,也记得对小白好一点。:)
更多干货请戳:
从0起步,走BI业务路线——如何往项目、咨询、管理的方向发展
点击阅读原文或扫码开始学习












