
 编者按
编者按与其担心未来自己的工作是否会被机器取代,不如好好加持一下未来科技即将给我们带来的工作魔力吧。
文 / 顾贝妮 创新战略顾问,动脉网联合创始人
尽管目前仍然无法判断人工智能未来是否将要取代人类大部分工作的真假可能性,但随着共享概念的深入人心以及众包工作模式的普及,作为一种HIT(Human Intelligence Task),众包模式似乎正与人工智能AI(Artificial Intelligence)相对应,在某些领域,两者甚至具有天然的结盟动机。
众包与机器学习的关系,可以从两个维度来:一类是以训练机器学习为目的,应用众包手段;另一类则是以完成接包任务为目的而应用机器学习技术。
在这方面, Crowdflower作为众包服务平台已成立近10年,近日传出又获得2000万美元风险投资的消息已是力证。众包人力结合机器学习的模式引人注目。在去年的这个时候,Crowdflower也曾融进1000万美元,投资方包括微软在内,微软的人工智能技术也随之引入。目前,Crowdflower已获得融资共计约5800万美元。
众包是低成本的数据获取渠道
机器学习严重依赖数据,怎样获得量大、质高的数据,以及对数据进行必要的清洗、标注,这些往往都成为训练机器算法的瓶颈。而众包模式作为互联网手段,是一种低成本的数据获取与处理方式。
根据Everest Group Pricing Assurance提供的数据,众包模式与传统外包模式相比,成本可降低高达60%。例如,Google利用谷歌利用众包方式打造测绘地图,获得了原本成本高昂的世界街景图片数据。这个办法,本田、高通等也相继效仿,开发基于外包的地图测绘技术。
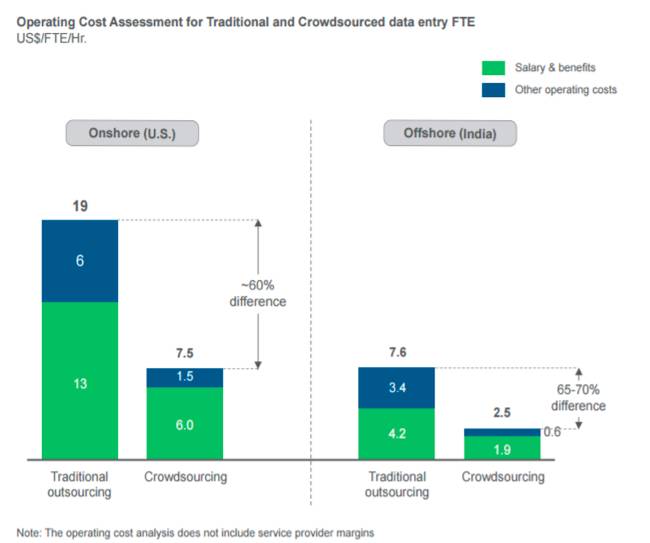
传统外包与众包模式的成本比较
在某些巧妙的模式设计下,甚至可以免费获得你想要的数据。最为典型的是由CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart)的发明者Luis von Ahn创办的多邻国Duolingo语言学习平台。
一直以来,多邻国的语言学习平台都是免费的,甚至没有广告。某些评论称“If you are not pay for the product, you are the product”(如果你没有为所使用的产品付费,那你本身就是这个产品的一部分)。
这句话听着很在理。你在使用多邻国的免费语言学习课程时,正在为它的客户免费提供文档翻译服务,这也意味着你即是多邻国的用户,更是它的免费劳工。就像BUZZFEED、CNN都是多邻国的客户一样。
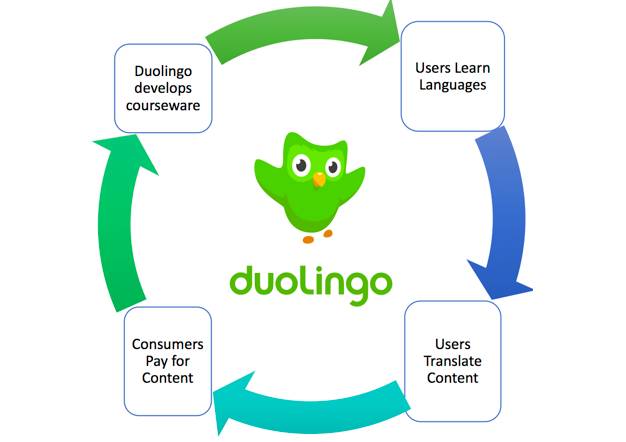
多邻国商业模式示意
无独有偶,著名的的患者社区Patientslikeme也为患者提供一个免费使用的分享平台,各种疑难杂症的病患进入在线社区分享自己的病情与诊疗感受。对病患来说这是典型的免费分享平台,而换个角度来看,Patinetslikeme通过从这些患者用户那里获得了海量且珍贵的个人健康数据,用以服务制药公司、医疗机构,进行各类医药研发或临床试验。
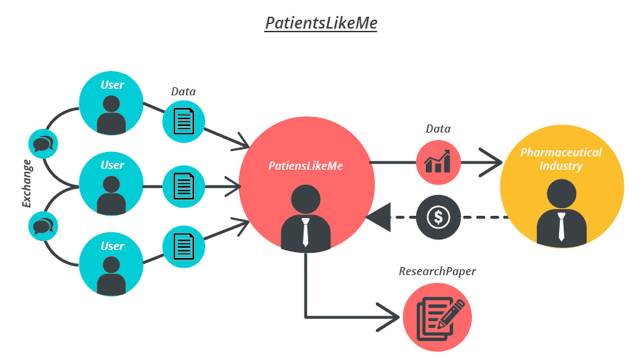
Patientslikeme商业模式示意图
从上述企业玩法不难看出,对于需要海量数据训练算法的人工智能技术公司而言,可以选择委托众包平台,或者自己设计一种结合众包、甚至免费模式来获取数据。
训练数据形成客观市场
事实上,确实有一些人工智能技术公司,正在委托像亚马逊、CrowdFlower这样的数据服务众包平台。另一家值得一提的公司——ImageNet ,就在创建之初的前两年里使用了近5万人去检查、分类和为十亿张候选图片做标签,许多工作则委托在亚马逊Amazon Mechanical Turk平台。
从另一个维度来说,随着机器学习技术的深入各个产业,未来用于训练算法的数据处理工作会越来越多,这本身也会是一项越发值得关注的生意。
在如今这个越加数据化的世界中,数据量增长更加迅速,而了解数据挖掘基础知识的人都知道,现有的大数据平台中,80%为非结构化的数据,如何获得更有价值并且适合机器学习的结构化数据?显然离不开一个处理过程。
于是,训练数据这门生意迎来了更大的市场空间。其中,微任务众包被用于智能影像、自然语言处理、情绪分析等相关领域的数据训练尤为适用。
CrowdFlower也正瞄准了这一市场。与CrowdFlower最为类似的还有Amazon于2005年既推出的Amazon Mechanical Turk,从利用大量的低成本劳力,再到进一步训练算法。
除此之外,类似的创业公司,例如Mighty AI(原名Spare5),于2017年1月宣布获得1400万美元B轮融资,结合之前的融资情况,Mighty AI共计融资达2725万美元,包括英特尔、埃森哲、谷歌等著名企业资本方,且获得IBM沃森这一大客户。Mighty AI更是直接打出“Training Data as a Service”的业务招牌,通过众包模式,为那些需要训练AI模型的算法工程师们提供相应数据处理服务。
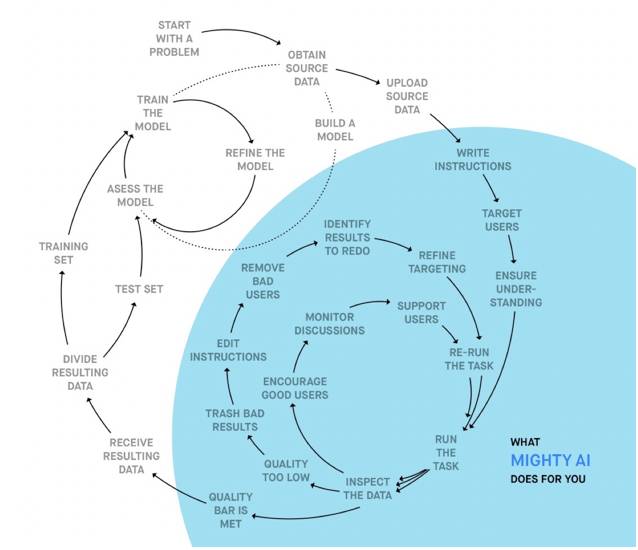
Mighty.AI的TRAINING DATA AS A SERVICE™工作流程示意图
机器学习优化众包效益
除了众包能助力机器学习外,反过来机器学习技术用在众包平台中也能优化众包效率。
以数据型任务为主要业务的众包平台的发展主要经历了三个阶段。
阶段一:低级别的劳力密集模式。主要依靠低成本人工完成任务,这也是既往众包最普遍的模式。
阶段二:机器训练阶段。也就是任务由人工完成,但同时机器已介入学习。
阶段三:机器可完成客观比例的任务,在复杂度高、机器不确定的情况下转由人工介入完成。也就是CrowdFlower如今强调的HITL模式。
就众包而言,成本一直是该模式最显著的优势之一。随着机器训练的深化,算法能直接完成的数据任务比例将不断提高,使得人工成本得以进一步降低。也就是说人工智能介入后,众包服务的边际成本有望实现逐渐降低,增大这门生意的利润空间。
比如,CrowdFlower就推出了面向客户提供机器学习的产品CrowdFlower AI服务,并逐渐将其产品化,提供给有深度需求的数据科学家做机器学习训练之用。
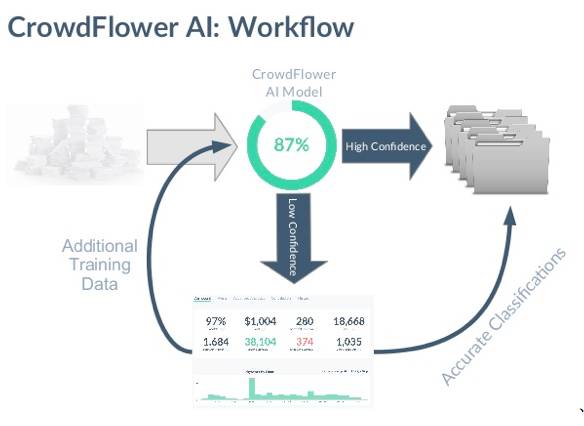
CrowdFlower AI工作流程
2016年11月,将机器学习结合众包的另一家创业公司Unbabel宣布获得500万美元A轮融资。Unbabel在2014年孵化于著名创业加速器Y Combinator,背后有包括Google Venture在内的著名投资方。Unbabel着力开发一款翻译引擎,其特点在于将机器学习和众包发动的40000名人工编辑配合使用从而提供服务。
从项目管理的目标来说,机器学习结合众包的模式,从时间、质量、成本三者间寻求最优化,除了成本优势之外,结合机器学习,在时间控制上也可获得进一步优化。
在时间要求方面,对平台来说只要劳动供给方充足,就可以有一定保障,也因此供给方的招募能力也是作为大型众包平台的重要竞争力之一。如果机器能完成的任务占比高,则意味着所需人工的数量要求可调低,则对时间控制力更强。
总之,就目前所设想的机器与人的各种工作方式的结合中,众包人力与机器学习CP的组合已经开始大放光彩了。与其担心未来自己的工作是否会被机器取代,不如好好加持一下未来科技即将给我们带来的工作魔力吧。
作者个人自媒体微信号:futuretalking,读者可由此号与作者直接交流











